 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Training & Inference for Forecasting: Linking Winner-Take-All back to GMMs
Jun 24, 2026Trajectory forecasting for autonomous driving has advanced rapidly, yet representative models often produce uninformative posteriors over forecast modes, causing problems for mode pruning. We trace this to a modeling-training mismatch: forecasters are typically modeled as conditional Gaussian mixture models (GMMs) but trained with a winner-take-all (WTA) loss that assigns each sample to its nearest mode. We argue that this K-means-like hard assignment (one-hot), while preventing mode collapse, is the source of uninformative mode probabilities: it over-segments the trajectory space, ignores relatedness among nearby modes, and yields assignment instability under small perturbations. Guided by this lens, we introduce two post-hoc treatments: (1) test-time posterior-weighted merging that aggregates nearby candidate trajectories; and (2) a one-step expectation-maximization (EM) update that replaces hard labels with soft responsibilities, sharing probability mass across neighboring modes. Across several WTA-trained architectures, these lightweight steps produce more informative, faithfully ranked mode posteriors and strengthen final forecasts on popular displacement metrics -- without retraining. Our analysis unifies recent design choices through a GMM-vs-K-means perspective and offers principled, practical corrections that better align training objectives with inference.
A Semantic and Occlusion-Aware GM-PHD Filter
May 20, 2026This paper proposes a new birth model including semantic information derived from deep learning to create an occlusion-aware Gaussian Mixture Probability Hypothesis Density (GM-PHD) filter. Unlike prior approaches that rely on simplistic or uniform assumptions, the proposed Semantic-Occlusion Aware (S-OA) birth model defines initialization terms by explicitly considering regions of occlusion and by leveraging semantic information about the environment. This enables the filter to accurately represent where new objects are more likely to appear, thereby improving tracking performance in complex and high-density driving scenarios. The method is evaluated through Monte Carlo simulations and experiments on the KITTI dataset. Performance is assessed by measuring the latency between first detection and track initiation, along with the mean absolute cardinality error and the Optimal Subpattern Assignment (OSPA) metric. Results demonstrate that the S-OA birth model reduces initialization delay in occlusion-heavy settings, matching or outperforming the strongest baseline in approximately 70% of cases. A sensitivity analysis of birth model weights is also provided. Overall, the findings underscore the benefits of integrating occlusion reasoning and semantic priors into Bayesian tracking frameworks for autonomous driving.
When the City Teaches the Car: Label-Free 3D Perception from Infrastructure
Mar 17, 2026Building robust 3D perception for self-driving still relies heavily on large-scale data collection and manual annotation, yet this paradigm becomes impractical as deployment expands across diverse cities and regions. Meanwhile, modern cities are increasingly instrumented with roadside units (RSUs), static sensors deployed along roads and at intersections to monitor traffic. This raises a natural question: can the city itself help train the vehicle? We propose infrastructure-taught, label-free 3D perception, a paradigm in which RSUs act as stationary, unsupervised teachers for ego vehicles. Leveraging their fixed viewpoints and repeated observations, RSUs learn local 3D detectors from unlabeled data and broadcast predictions to passing vehicles, which are aggregated as pseudo-label supervision for training a standalone ego detector. The resulting model requires no infrastructure or communication at test time. We instantiate this idea as a fully label-free three-stage pipeline and conduct a concept-and-feasibility study in a CARLA-based multi-agent environment. With CenterPoint, our pipeline achieves 82.3% AP for detecting vehicles, compared to a fully supervised ego upper bound of 94.4%. We further systematically analyze each stage, evaluate its scalability, and demonstrate complementarity with existing ego-centric label-free methods. Together, these results suggest that city infrastructure itself can potentially provide a scalable supervisory signal for autonomous vehicles, positioning infrastructure-taught learning as a promising orthogonal paradigm for reducing annotation cost in 3D perception.
On the Feasibility and Opportunity of Autoregressive 3D Object Detection
Mar 09, 2026LiDAR-based 3D object detectors typically rely on proposal heads with hand-crafted components like anchor assignment and non-maximum suppression (NMS), complicating training and limiting extensibility. We present AutoReg3D, an autoregressive 3D detector that casts detection as sequence generation. Given point-cloud features, AutoReg3D emits objects in a range-causal (near-to-far) order and encodes each object as a short, discrete-token sequence consisting of its center, size, orientation, velocity, and class. This near-to-far ordering mirrors LiDAR geometry--near objects occlude far ones but not vice versa--enabling straightforward teacher forcing during training and autoregressive decoding at test time. AutoReg3D is compatible across diverse point-cloud or backbones and attains competitive nuScenes performance without anchors or NMS. Beyond parity, the sequential formulation unlocks language-model advances for 3D perception, including GRPO-style reinforcement learning for task-aligned objectives. These results position autoregressive decoding as a viable, flexible alternative for LiDAR-based detection and open a path to importing modern sequence-modeling tools into 3D perception.
Mixed Signals: A Diverse Point Cloud Dataset for Heterogeneous LiDAR V2X Collaboration
Feb 19, 2025Vehicle-to-everything (V2X) collaborative perception has emerged as a promising solution to address the limitations of single-vehicle perception systems. However, existing V2X datasets are limited in scope, diversity, and quality. To address these gaps, we present Mixed Signals, a comprehensive V2X dataset featuring 45.1k point clouds and 240.6k bounding boxes collected from three connected autonomous vehicles (CAVs) equipped with two different types of LiDAR sensors, plus a roadside unit with dual LiDARs. Our dataset provides precisely aligned point clouds and bounding box annotations across 10 classes, ensuring reliable data for perception training. We provide detailed statistical analysis on the quality of our dataset and extensively benchmark existing V2X methods on it. Mixed Signals V2X Dataset is one of the highest quality, large-scale datasets publicly available for V2X perception research. Details on the website https://mixedsignalsdataset.cs.cornell.edu/.
Transfer Your Perspective: Controllable 3D Generation from Any Viewpoint in a Driving Scene
Feb 10, 2025



Self-driving cars relying solely on ego-centric perception face limitations in sensing, often failing to detect occluded, faraway objects. Collaborative autonomous driving (CAV) seems like a promising direction, but collecting data for development is non-trivial. It requires placing multiple sensor-equipped agents in a real-world driving scene, simultaneously! As such, existing datasets are limited in locations and agents. We introduce a novel surrogate to the rescue, which is to generate realistic perception from different viewpoints in a driving scene, conditioned on a real-world sample - the ego-car's sensory data. This surrogate has huge potential: it could potentially turn any ego-car dataset into a collaborative driving one to scale up the development of CAV. We present the very first solution, using a combination of simulated collaborative data and real ego-car data. Our method, Transfer Your Perspective (TYP), learns a conditioned diffusion model whose output samples are not only realistic but also consistent in both semantics and layouts with the given ego-car data. Empirical results demonstrate TYP's effectiveness in aiding in a CAV setting. In particular, TYP enables us to (pre-)train collaborative perception algorithms like early and late fusion with little or no real-world collaborative data, greatly facilitating downstream CAV applications.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024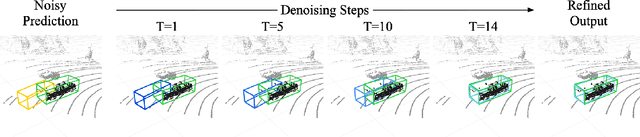
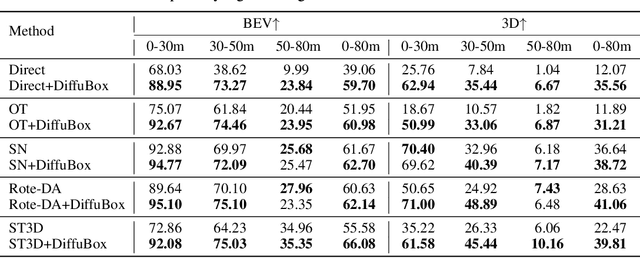
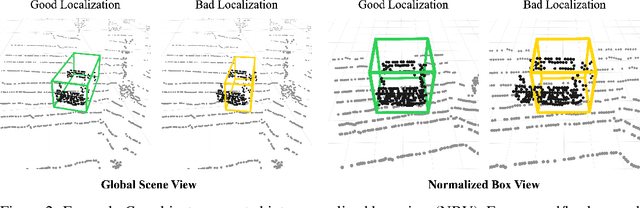
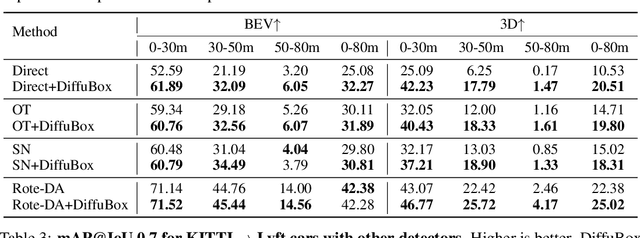
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Better Monocular 3D Detectors with LiDAR from the Past
Apr 09, 2024



Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
Improving Environment Robustness of Deep Reinforcement Learning Approaches for Autonomous Racing Using Bayesian Optimization-based Curriculum Learning
Dec 16, 2023Deep reinforcement learning (RL) approaches have been broadly applied to a large number of robotics tasks, such as robot manipulation and autonomous driving. However, an open problem in deep RL is learning policies that are robust to variations in the environment, which is an important condition for such systems to be deployed into real-world, unstructured settings. Curriculum learning is one approach that has been applied to improve generalization performance in both supervised and reinforcement learning domains, but selecting the appropriate curriculum to achieve robustness can be a user-intensive process. In our work, we show that performing probabilistic inference of the underlying curriculum-reward function using Bayesian Optimization can be a promising technique for finding a robust curriculum. We demonstrate that a curriculum found with Bayesian optimization can outperform a vanilla deep RL agent and a hand-engineered curriculum in the domain of autonomous racing with obstacle avoidance. Our code is available at https://github.com/PRISHIta123/Curriculum_RL_for_Driving.