 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleMoGen: Autoregressive Next-Scale Prediction for Human Motion Generation
May 12, 2026We present ScaleMoGen, a scale-wise autoregressive framework for text-driven human motion generation. Unlike conventional autoregressive approaches that rely on standard next-token prediction, ScaleMoGen frames motion generation as a coarse-to-fine process. We quantize 3D motions into compositional discrete tokens across multiple skeletal-emporal scales of increasing granularity, learning to generate motion by autoregressively predicting next-scale token maps. To maintain structural integrity, our motion tokenizers and quantizers are explicitly designed so that discrete tokens at every scale strictly preserve the skeletal hierarchy. Additionally, we employ bitwise quantization and prediction, which efficiently scale up the tokenizer vocabulary to preserve motion details and stabilize optimization. Extensive experiments demonstrate that ScaleMoGen achieves state-of-the-art performance, establishing an FID of 0.030 (vs. 0.045 for MoMask) on HumanML3D and a CLIP Score of 0.693 (vs. 0.685 for MoMask++) on the SnapMoGen dataset. Furthermore, we demonstrate that our skeletal-temporal multi-scale representation naturally facilitates training-free, text-guided motion editing.
IAM: Identity-Aware Human Motion and Shape Joint Generation
Apr 28, 2026Recent advances in text-driven human motion generation enable models to synthesize realistic motion sequences from natural language descriptions. However, most existing approaches assume identity-neutral motion and generate movements using a canonical body representation, ignoring the strong influence of body morphology on motion dynamics. In practice, attributes such as body proportions, mass distribution, and age significantly affect how actions are performed, and neglecting this coupling often leads to physically inconsistent motions. We propose an identity-aware motion generation framework that explicitly models the relationship between body morphology and motion dynamics. Instead of relying on explicit geometric measurements, identity is represented using multimodal signals, including natural language descriptions and visual cues. We further introduce a joint motion-shape generation paradigm that simultaneously synthesizes motion sequences and body shape parameters, allowing identity cues to directly modulate motion dynamics. Extensive experiments on motion capture datasets and large-scale in-the-wild videos demonstrate improved motion realism and motion-identity consistency while maintaining high motion quality. Project page: https://vjwq.github.io/IAM
HandX: Scaling Bimanual Motion and Interaction Generation
Mar 30, 2026Synthesizing human motion has advanced rapidly, yet realistic hand motion and bimanual interaction remain underexplored. Whole-body models often miss the fine-grained cues that drive dexterous behavior, finger articulation, contact timing, and inter-hand coordination, and existing resources lack high-fidelity bimanual sequences that capture nuanced finger dynamics and collaboration. To fill this gap, we present HandX, a unified foundation spanning data, annotation, and evaluation. We consolidate and filter existing datasets for quality, and collect a new motion-capture dataset targeting underrepresented bimanual interactions with detailed finger dynamics. For scalable annotation, we introduce a decoupled strategy that extracts representative motion features, e.g., contact events and finger flexion, and then leverages reasoning from large language models to produce fine-grained, semantically rich descriptions aligned with these features. Building on the resulting data and annotations, we benchmark diffusion and autoregressive models with versatile conditioning modes. Experiments demonstrate high-quality dexterous motion generation, supported by our newly proposed hand-focused metrics. We further observe clear scaling trends: larger models trained on larger, higher-quality datasets produce more semantically coherent bimanual motion. Our dataset is released to support future research.
Unleashing Guidance Without Classifiers for Human-Object Interaction Animation
Mar 26, 2026Generating realistic human-object interaction (HOI) animations remains challenging because it requires jointly modeling dynamic human actions and diverse object geometries. Prior diffusion-based approaches often rely on hand-crafted contact priors or human-imposed kinematic constraints to improve contact quality. We propose LIGHT, a data-driven alternative in which guidance emerges from the denoising pace itself, reducing dependence on manually designed priors. Building on diffusion forcing, we factor the representation into modality-specific components and assign individualized noise levels with asynchronous denoising schedules. In this paradigm, cleaner components guide noisier ones through cross-attention, yielding guidance without auxiliary classifiers. We find that this data-driven guidance is inherently contact-aware, and can be enhanced when training is augmented with a broad spectrum of synthetic object geometries, encouraging invariance of contact semantics to geometric diversity. Extensive experiments show that pace-induced guidance more effectively mirrors the benefits of contact priors than conventional classifier-free guidance, while achieving higher contact fidelity, more realistic HOI generation, and stronger generalization to unseen objects and tasks.
UMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Mar 16, 2026Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross-modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model. Code and model will be publicly available. Project Page: https://oliver-cong02.github.io/UMO.github.io/
IH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
LLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens
Feb 12, 2026Recent progress in large models has led to significant advances in unified multimodal generation and understanding. However, the development of models that unify motion-language generation and understanding remains largely underexplored. Existing approaches often fine-tune large language models (LLMs) on paired motion-text data, which can result in catastrophic forgetting of linguistic capabilities due to the limited scale of available text-motion pairs. Furthermore, prior methods typically convert motion into discrete representations via quantization to integrate with language models, introducing substantial jitter artifacts from discrete tokenization. To address these challenges, we propose LLaMo, a unified framework that extends pretrained LLMs through a modality-specific Mixture-of-Transformers (MoT) architecture. This design inherently preserves the language understanding of the base model while enabling scalable multimodal adaptation. We encode human motion into a causal continuous latent space and maintain the next-token prediction paradigm in the decoder-only backbone through a lightweight flow-matching head, allowing for streaming motion generation in real-time (>30 FPS). Leveraging the comprehensive language understanding of pretrained LLMs and large-scale motion-text pretraining, our experiments demonstrate that LLaMo achieves high-fidelity text-to-motion generation and motion-to-text captioning in general settings, especially zero-shot motion generation, marking a significant step towards a general unified motion-language large model.
Privacy Blur: Quantifying Privacy and Utility for Image Data Release
Dec 18, 2025
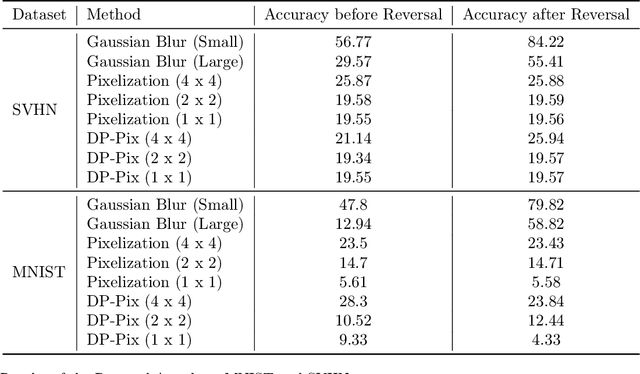

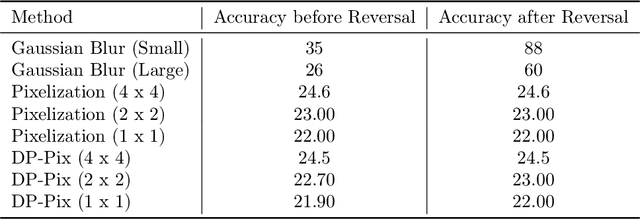
Image data collected in the wild often contains private information such as faces and license plates, and responsible data release must ensure that this information stays hidden. At the same time, released data should retain its usefulness for model-training. The standard method for private information obfuscation in images is Gaussian blurring. In this work, we show that practical implementations of Gaussian blurring are reversible enough to break privacy. We then take a closer look at the privacy-utility tradeoffs offered by three other obfuscation algorithms -- pixelization, pixelization and noise addition (DP-Pix), and cropping. Privacy is evaluated by reversal and discrimination attacks, while utility by the quality of the learnt representations when the model is trained on data with obfuscated faces. We show that the most popular industry-standard method, Gaussian blur is the least private of the four -- being susceptible to reversal attacks in its practical low-precision implementations. In contrast, pixelization and pixelization plus noise addition, when used at the right level of granularity, offer both privacy and utility for a number of computer vision tasks. We make our proposed methods together with suggested parameters available in a software package called Privacy Blur.
AHA! Animating Human Avatars in Diverse Scenes with Gaussian Splatting
Nov 13, 2025We present a novel framework for animating humans in 3D scenes using 3D Gaussian Splatting (3DGS), a neural scene representation that has recently achieved state-of-the-art photorealistic results for novel-view synthesis but remains under-explored for human-scene animation and interaction. Unlike existing animation pipelines that use meshes or point clouds as the underlying 3D representation, our approach introduces the use of 3DGS as the 3D representation to the problem of animating humans in scenes. By representing humans and scenes as Gaussians, our approach allows for geometry-consistent free-viewpoint rendering of humans interacting with 3D scenes. Our key insight is that the rendering can be decoupled from the motion synthesis and each sub-problem can be addressed independently, without the need for paired human-scene data. Central to our method is a Gaussian-aligned motion module that synthesizes motion without explicit scene geometry, using opacity-based cues and projected Gaussian structures to guide human placement and pose alignment. To ensure natural interactions, we further propose a human-scene Gaussian refinement optimization that enforces realistic contact and navigation. We evaluate our approach on scenes from Scannet++ and the SuperSplat library, and on avatars reconstructed from sparse and dense multi-view human capture. Finally, we demonstrate that our framework allows for novel applications such as geometry-consistent free-viewpoint rendering of edited monocular RGB videos with new animated humans, showcasing the unique advantage of 3DGS for monocular video-based human animation.
Pressure2Motion: Hierarchical Motion Synthesis from Ground Pressure with Text Guidance
Nov 07, 2025We present Pressure2Motion, a novel motion capture algorithm that synthesizes human motion from a ground pressure sequence and text prompt. It eliminates the need for specialized lighting setups, cameras, or wearable devices, making it suitable for privacy-preserving, low-light, and low-cost motion capture scenarios. Such a task is severely ill-posed due to the indeterminate nature of the pressure signals to full-body motion. To address this issue, we introduce Pressure2Motion, a generative model that leverages pressure features as input and utilizes a text prompt as a high-level guiding constraint. Specifically, our model utilizes a dual-level feature extractor that accurately interprets pressure data, followed by a hierarchical diffusion model that discerns broad-scale movement trajectories and subtle posture adjustments. Both the physical cues gained from the pressure sequence and the semantic guidance derived from descriptive texts are leveraged to guide the motion generation with precision. To the best of our knowledge, Pressure2Motion is a pioneering work in leveraging both pressure data and linguistic priors for motion generation, and the established MPL benchmark is the first benchmark for this task. Experiments show our method generates high-fidelity, physically plausible motions, establishing a new state-of-the-art for this task. The codes and benchmarks will be publicly released upon publication.