 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments
Jun 04, 2026Continual learning, the ability of AI systems to improve through sequential experience, has attracted substantial interest, but no high-quality benchmark exists to evaluate it. We introduce Continual Learning Bench (CL-Bench), the first difficult, expert-validated benchmark designed to measure whether LLM-based systems genuinely improve with experience. CL-Bench spans six diverse domains (software engineering, signal processing, disease outbreak forecasting, database querying, strategic game-playing, and demand forecasting), each validated by domain experts and designed so that tasks share a learnable latent structure (codebase layout, disease outbreak dynamics, opponent strategies) that a stateful system can discover online but a stateless one cannot. We evaluate frontier models across several agent architectures, from naive in-context learning (ICL) to dedicated memory systems, introducing a gain metric to isolate learning from prior capabilities. We find that these systems leave headroom for improved continual learning: agents frequently overfit to immediate observations or fail to reuse knowledge across instances, and dedicated memory systems do not fix this -- in fact, naive ICL outperforms systems dedicated to memory management. CL-Bench is the first benchmark to evaluate continual learning across diverse real-world domains with expert-validated tasks and isolate online learning from underlying model capability, showing a need for better continual learning systems.
Benchmarking Agents in Insurance Underwriting Environments
Jan 31, 2026As AI agents integrate into enterprise applications, their evaluation demands benchmarks that reflect the complexity of real-world operations. Instead, existing benchmarks overemphasize open-domains such as code, use narrow accuracy metrics, and lack authentic complexity. We present UNDERWRITE, an expert-first, multi-turn insurance underwriting benchmark designed in close collaboration with domain experts to capture real-world enterprise challenges. UNDERWRITE introduces critical realism factors often absent in current benchmarks: proprietary business knowledge, noisy tool interfaces, and imperfect simulated users requiring careful information gathering. Evaluating 13 frontier models, we uncover significant gaps between research lab performance and enterprise readiness: the most accurate models are not the most efficient, models hallucinate domain knowledge despite tool access, and pass^k results show a 20% drop in performance. The results from UNDERWRITE demonstrate that expert involvement in benchmark design is essential for realistic agent evaluation, common agentic frameworks exhibit brittleness that skews performance reporting, and hallucination detection in specialized domains demands compositional approaches. Our work provides insights for developing benchmarks that better align with enterprise deployment requirements.
Multi-Step Dialogue Workflow Action Prediction
Nov 16, 2023



In task-oriented dialogue, a system often needs to follow a sequence of actions, called a workflow, that complies with a set of guidelines in order to complete a task. In this paper, we propose the novel problem of multi-step workflow action prediction, in which the system predicts multiple future workflow actions. Accurate prediction of multiple steps allows for multi-turn automation, which can free up time to focus on more complex tasks. We propose three modeling approaches that are simple to implement yet lead to more action automation: 1) fine-tuning on a training dataset, 2) few-shot in-context learning leveraging retrieval and large language model prompting, and 3) zero-shot graph traversal, which aggregates historical action sequences into a graph for prediction. We show that multi-step action prediction produces features that improve accuracy on downstream dialogue tasks like predicting task success, and can increase automation of steps by 20% without requiring as much feedback from a human overseeing the system.
Workflow-Guided Response Generation for Task-Oriented Dialogue
Nov 14, 2023



Task-oriented dialogue (TOD) systems aim to achieve specific goals through interactive dialogue. Such tasks usually involve following specific workflows, i.e. executing a sequence of actions in a particular order. While prior work has focused on supervised learning methods to condition on past actions, they do not explicitly optimize for compliance to a desired workflow. In this paper, we propose a novel framework based on reinforcement learning (RL) to generate dialogue responses that are aligned with a given workflow. Our framework consists of ComplianceScorer, a metric designed to evaluate how well a generated response executes the specified action, combined with an RL opimization process that utilizes an interactive sampling technique. We evaluate our approach on two TOD datasets, Action-Based Conversations Dataset (ABCD) (Chen et al., 2021a) and MultiWOZ 2.2 (Zang et al., 2020) on a range of automated and human evaluation metrics. Our findings indicate that our RL-based framework outperforms baselines and is effective at enerating responses that both comply with the intended workflows while being expressed in a natural and fluent manner.
Long-term Control for Dialogue Generation: Methods and Evaluation
May 15, 2022
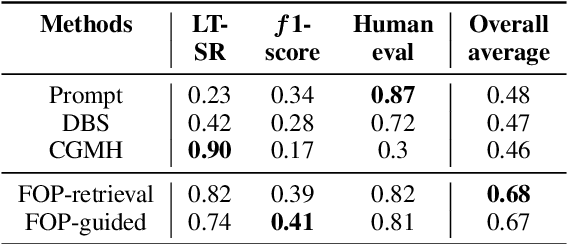
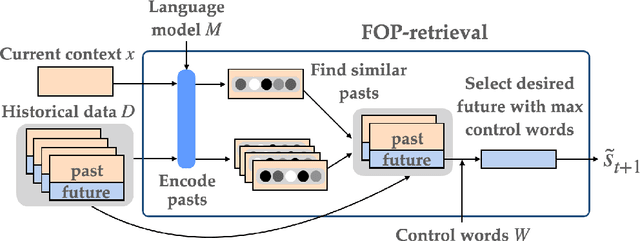
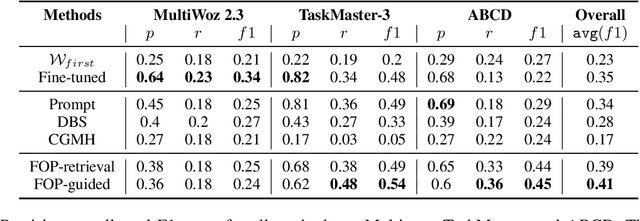
Current approaches for controlling dialogue response generation are primarily focused on high-level attributes like style, sentiment, or topic. In this work, we focus on constrained long-term dialogue generation, which involves more fine-grained control and requires a given set of control words to appear in generated responses. This setting requires a model to not only consider the generation of these control words in the immediate context, but also produce utterances that will encourage the generation of the words at some time in the (possibly distant) future. We define the problem of constrained long-term control for dialogue generation, identify gaps in current methods for evaluation, and propose new metrics that better measure long-term control. We also propose a retrieval-augmented method that improves performance of long-term controlled generation via logit modification techniques. We show through experiments on three task-oriented dialogue datasets that our metrics better assess dialogue control relative to current alternatives and that our method outperforms state-of-the-art constrained generation baselines.
A Bayesian Approach to Identifying Representational Errors
Mar 28, 2021
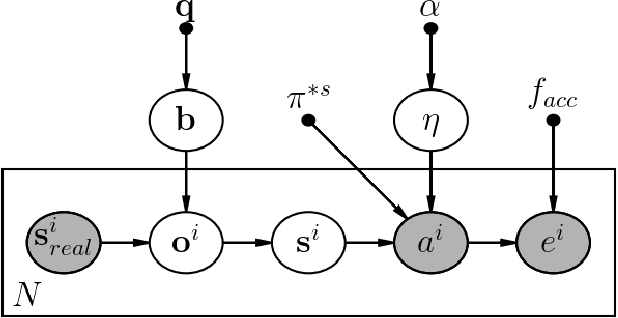


Trained AI systems and expert decision makers can make errors that are often difficult to identify and understand. Determining the root cause for these errors can improve future decisions. This work presents Generative Error Model (GEM), a generative model for inferring representational errors based on observations of an actor's behavior (either simulated agent, robot, or human). The model considers two sources of error: those that occur due to representational limitations -- "blind spots" -- and non-representational errors, such as those caused by noise in execution or systematic errors present in the actor's policy. Disambiguating these two error types allows for targeted refinement of the actor's policy (i.e., representational errors require perceptual augmentation, while other errors can be reduced through methods such as improved training or attention support). We present a Bayesian inference algorithm for GEM and evaluate its utility in recovering representational errors on multiple domains. Results show that our approach can recover blind spots of both reinforcement learning agents as well as human users.
Discovering Blind Spots in Reinforcement Learning
May 23, 2018



Agents trained in simulation may make errors in the real world due to mismatches between training and execution environments. These mistakes can be dangerous and difficult to discover because the agent cannot predict them a priori. We propose using oracle feedback to learn a predictive model of these blind spots to reduce costly errors in real-world applications. We focus on blind spots in reinforcement learning (RL) that occur due to incomplete state representation: The agent does not have the appropriate features to represent the true state of the world and thus cannot distinguish among numerous states. We formalize the problem of discovering blind spots in RL as a noisy supervised learning problem with class imbalance. We learn models to predict blind spots in unseen regions of the state space by combining techniques for label aggregation, calibration, and supervised learning. The models take into consideration noise emerging from different forms of oracle feedback, including demonstrations and corrections. We evaluate our approach on two domains and show that it achieves higher predictive performance than baseline methods, and that the learned model can be used to selectively query an oracle at execution time to prevent errors. We also empirically analyze the biases of various feedback types and how they influence the discovery of blind spots.
Efficient Model Learning for Human-Robot Collaborative Tasks
May 24, 2014



We present a framework for learning human user models from joint-action demonstrations that enables the robot to compute a robust policy for a collaborative task with a human. The learning takes place completely automatically, without any human intervention. First, we describe the clustering of demonstrated action sequences into different human types using an unsupervised learning algorithm. These demonstrated sequences are also used by the robot to learn a reward function that is representative for each type, through the employment of an inverse reinforcement learning algorithm. The learned model is then used as part of a Mixed Observability Markov Decision Process formulation, wherein the human type is a partially observable variable. With this framework, we can infer, either offline or online, the human type of a new user that was not included in the training set, and can compute a policy for the robot that will be aligned to the preference of this new user and will be robust to deviations of the human actions from prior demonstrations. Finally we validate the approach using data collected in human subject experiments, and conduct proof-of-concept demonstrations in which a person performs a collaborative task with a small industrial robot.