 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnough Coin Flips Can Make LLMs Act Bayesian
Mar 06, 2025Large language models (LLMs) exhibit the ability to generalize given few-shot examples in their input prompt, an emergent capability known as in-context learning (ICL). We investigate whether LLMs utilize ICL to perform structured reasoning in ways that are consistent with a Bayesian framework or rely on pattern matching. Using a controlled setting of biased coin flips, we find that: (1) LLMs often possess biased priors, causing initial divergence in zero-shot settings, (2) in-context evidence outweighs explicit bias instructions, (3) LLMs broadly follow Bayesian posterior updates, with deviations primarily due to miscalibrated priors rather than flawed updates, and (4) attention magnitude has negligible effect on Bayesian inference. With sufficient demonstrations of biased coin flips via ICL, LLMs update their priors in a Bayesian manner.
Analyzing The Language of Visual Tokens
Nov 07, 2024



With the introduction of transformer-based models for vision and language tasks, such as LLaVA and Chameleon, there has been renewed interest in the discrete tokenized representation of images. These models often treat image patches as discrete tokens, analogous to words in natural language, learning joint alignments between visual and human languages. However, little is known about the statistical behavior of these visual languages - whether they follow similar frequency distributions, grammatical structures, or topologies as natural languages. In this paper, we take a natural-language-centric approach to analyzing discrete visual languages and uncover striking similarities and fundamental differences. We demonstrate that, although visual languages adhere to Zipfian distributions, higher token innovation drives greater entropy and lower compression, with tokens predominantly representing object parts, indicating intermediate granularity. We also show that visual languages lack cohesive grammatical structures, leading to higher perplexity and weaker hierarchical organization compared to natural languages. Finally, we demonstrate that, while vision models align more closely with natural languages than other models, this alignment remains significantly weaker than the cohesion found within natural languages. Through these experiments, we demonstrate how understanding the statistical properties of discrete visual languages can inform the design of more effective computer vision models.
Data-Centric AI Governance: Addressing the Limitations of Model-Focused Policies
Sep 25, 2024



Current regulations on powerful AI capabilities are narrowly focused on "foundation" or "frontier" models. However, these terms are vague and inconsistently defined, leading to an unstable foundation for governance efforts. Critically, policy debates often fail to consider the data used with these models, despite the clear link between data and model performance. Even (relatively) "small" models that fall outside the typical definitions of foundation and frontier models can achieve equivalent outcomes when exposed to sufficiently specific datasets. In this work, we illustrate the importance of considering dataset size and content as essential factors in assessing the risks posed by models both today and in the future. More broadly, we emphasize the risk posed by over-regulating reactively and provide a path towards careful, quantitative evaluation of capabilities that can lead to a simplified regulatory environment.
Comparative Multi-View Language Grounding
Nov 14, 2023



In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.
Does unsupervised grammar induction need pixels?
Dec 20, 2022Are extralinguistic signals such as image pixels crucial for inducing constituency grammars? While past work has shown substantial gains from multimodal cues, we investigate whether such gains persist in the presence of rich information from large language models (LLMs). We find that our approach, LLM-based C-PCFG (LC-PCFG), outperforms previous multi-modal methods on the task of unsupervised constituency parsing, achieving state-of-the-art performance on a variety of datasets. Moreover, LC-PCFG results in an over 50% reduction in parameter count, and speedups in training time of 1.7x for image-aided models and more than 5x for video-aided models, respectively. These results challenge the notion that extralinguistic signals such as image pixels are needed for unsupervised grammar induction, and point to the need for better text-only baselines in evaluating the need of multi-modality for the task.
Voxel-informed Language Grounding
May 19, 2022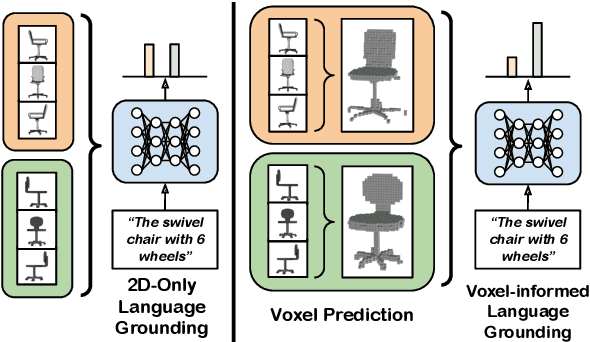
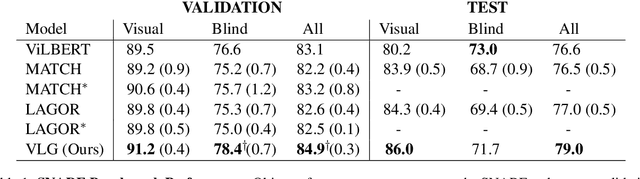
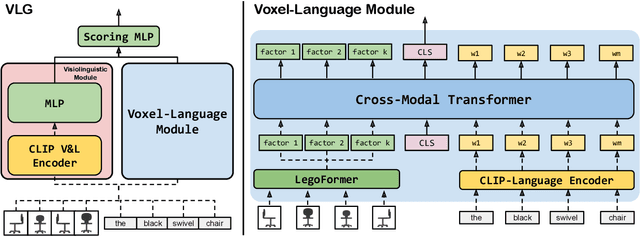
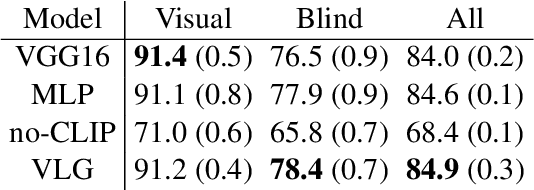
Natural language applied to natural 2D images describes a fundamentally 3D world. We present the Voxel-informed Language Grounder (VLG), a language grounding model that leverages 3D geometric information in the form of voxel maps derived from the visual input using a volumetric reconstruction model. We show that VLG significantly improves grounding accuracy on SNARE, an object reference game task. At the time of writing, VLG holds the top place on the SNARE leaderboard, achieving SOTA results with a 2.0% absolute improvement.
Modularity Improves Out-of-Domain Instruction Following
Oct 24, 2020
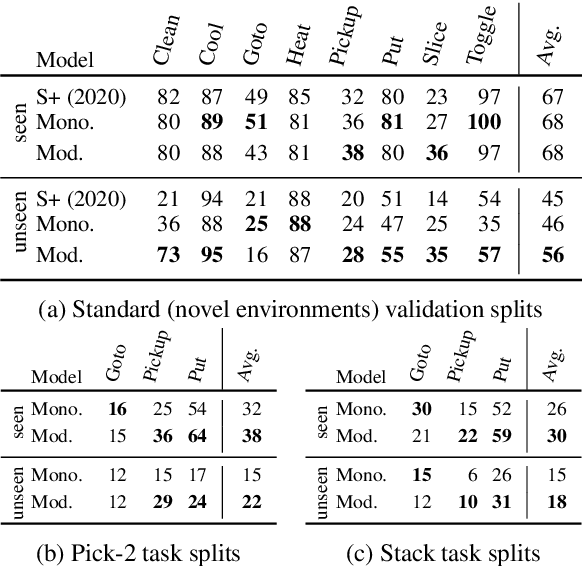
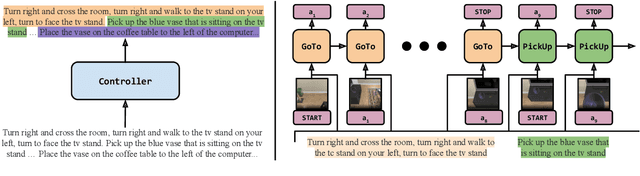

We propose a modular architecture for following natural language instructions that describe sequences of diverse subgoals, such as navigating to landmarks or picking up objects. Standard, non-modular, architectures used in instruction following do not exploit subgoal compositionality and often struggle on out-of-distribution tasks and environments. In our approach, subgoal modules each carry out natural language instructions for a specific subgoal type. A sequence of modules to execute is chosen by learning to segment the instructions and predicting a subgoal type for each segment. When compared to standard sequence-to-sequence approaches on ALFRED, a challenging instruction following benchmark, we find that modularization improves generalization to environments unseen in training and to novel tasks.
Modeling Conceptual Understanding in Image Reference Games
Nov 19, 2019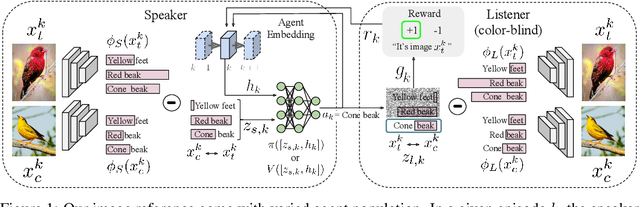
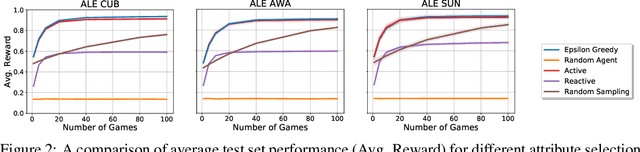
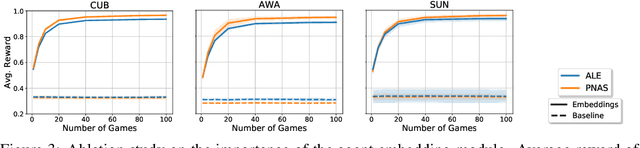
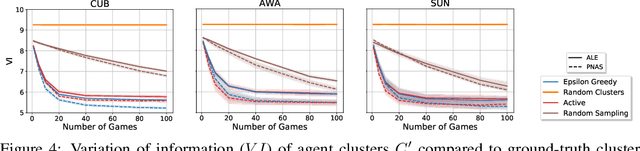
An agent who interacts with a wide population of other agents needs to be aware that there may be variations in their understanding of the world. Furthermore, the machinery which they use to perceive may be inherently different, as is the case between humans and machines. In this work, we present both an image reference game between a speaker and a population of listeners where reasoning about the concepts other agents can comprehend is necessary and a model formulation with this capability. We focus on reasoning about the conceptual understanding of others, as well as adapting to novel gameplay partners and dealing with differences in perceptual machinery. Our experiments on three benchmark image/attribute datasets suggest that our learner indeed encodes information directly pertaining to the understanding of other agents, and that leveraging this information is crucial for maximizing gameplay performance.