 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Large Reasoning Models Effective Reflection
Jan 19, 2026Large Reasoning Models (LRMs) have recently shown impressive performance on complex reasoning tasks, often by engaging in self-reflective behaviors such as self-critique and backtracking. However, not all reflections are beneficial-many are superficial, offering little to no improvement over the original answer and incurring computation overhead. In this paper, we identify and address the problem of superficial reflection in LRMs. We first propose Self-Critique Fine-Tuning (SCFT), a training framework that enhances the model's reflective reasoning ability using only self-generated critiques. SCFT prompts models to critique their own outputs, filters high-quality critiques through rejection sampling, and fine-tunes the model using a critique-based objective. Building on this strong foundation, we further introduce Reinforcement Learning with Effective Reflection Rewards (RLERR). RLERR leverages the high-quality reflections initialized by SCFT to construct reward signals, guiding the model to internalize the self-correction process via reinforcement learning. Experiments on two challenging benchmarks, AIME2024 and AIME2025, show that SCFT and RLERR significantly improve both reasoning accuracy and reflection quality, outperforming state-of-the-art baselines. All data and codes are available at https://github.com/wanghanbinpanda/SCFT.
Group Pattern Selection Optimization: Let LRMs Pick the Right Pattern for Reasoning
Jan 12, 2026Large reasoning models (LRMs) exhibit diverse high-level reasoning patterns (e.g., direct solution, reflection-and-verification, and exploring multiple solutions), yet prevailing training recipes implicitly bias models toward a limited set of dominant patterns. Through a systematic analysis, we identify substantial accuracy variance across these patterns on mathematics and science benchmarks, revealing that a model's default reasoning pattern is often sub-optimal for a given problem. To address this, we introduce Group Pattern Selection Optimization (GPSO), a reinforcement learning framework that extends GRPO by incorporating multi-pattern rollouts, verifier-guided optimal pattern selection per problem, and attention masking during optimization to prevent the leakage of explicit pattern suffixes into the learned policy. By exploring a portfolio of diverse reasoning strategies and optimizing the policy on the most effective ones, GPSO enables the model to internalize the mapping from problem characteristics to optimal reasoning patterns. Extensive experiments demonstrate that GPSO delivers consistent and substantial performance gains across various model backbones and benchmarks, effectively mitigating pattern sub-optimality and fostering more robust, adaptable reasoning. All data and codes are available at https://github.com/wanghanbinpanda/GPSO.
Perceive and Calibrate: Analyzing and Enhancing Robustness of Medical Multi-Modal Large Language Models
Dec 26, 2025Medical Multi-modal Large Language Models (MLLMs) have shown promising clinical performance. However, their sensitivity to real-world input perturbations, such as imaging artifacts and textual errors, critically undermines their clinical applicability. Systematic analysis of such noise impact on medical MLLMs remains largely unexplored. Furthermore, while several works have investigated the MLLMs' robustness in general domains, they primarily focus on text modality and rely on costly fine-tuning. They are inadequate to address the complex noise patterns and fulfill the strict safety standards in medicine. To bridge this gap, this work systematically analyzes the impact of various perturbations on medical MLLMs across both visual and textual modalities. Building on our findings, we introduce a training-free Inherent-enhanced Multi-modal Calibration (IMC) framework that leverages MLLMs' inherent denoising capabilities following the perceive-and-calibrate principle for cross-modal robustness enhancement. For the visual modality, we propose a Perturbation-aware Denoising Calibration (PDC) which leverages MLLMs' own vision encoder to identify noise patterns and perform prototype-guided feature calibration. For text denoising, we design a Self-instantiated Multi-agent System (SMS) that exploits the MLLMs' self-assessment capabilities to refine noisy text through a cooperative hierarchy of agents. We construct a benchmark containing 11 types of noise across both image and text modalities on 2 datasets. Experimental results demonstrate our method achieves the state-of-the-art performance across multiple modalities, showing potential to enhance MLLMs' robustness in real clinical scenarios.
Boosting In-Silicon Directed Evolution with Fine-Tuned Protein Language Model and Tree Search
Nov 19, 2025Protein evolution through amino acid sequence mutations is a cornerstone of life sciences. While current in-silicon directed evolution algorithms largely focus on designing heuristic search strategies, they overlook how to integrate the transformative protein language models, which encode rich evolutionary patterns, with reinforcement learning to learn to directly evolve proteins. To bridge this gap, we propose AlphaDE, a novel framework to optimize protein sequences by harnessing the innovative paradigms of large language models such as fine-tuning and test-time inference. First, AlphaDE fine-tunes pretrained protein language models using masked language modeling on homologous protein sequences to activate the evolutionary plausibility for the interested protein class. Second, AlphaDE introduces test-time inference based on Monte Carlo tree search, which effectively evolves proteins with evolutionary guidance from the fine-tuned protein language model. Extensive benchmark experiments show that AlphaDE remarkably outperforms previous state-of-the-art methods even with few-shot fine-tuning. A further case study demonstrates that AlphaDE supports condensing the protein sequence space of avGFP through computational evolution.
MEJO: MLLM-Engaged Surgical Triplet Recognition via Inter- and Intra-Task Joint Optimization
Sep 16, 2025Surgical triplet recognition, which involves identifying instrument, verb, target, and their combinations, is a complex surgical scene understanding challenge plagued by long-tailed data distribution. The mainstream multi-task learning paradigm benefiting from cross-task collaborative promotion has shown promising performance in identifying triples, but two key challenges remain: 1) inter-task optimization conflicts caused by entangling task-generic and task-specific representations; 2) intra-task optimization conflicts due to class-imbalanced training data. To overcome these difficulties, we propose the MLLM-Engaged Joint Optimization (MEJO) framework that empowers both inter- and intra-task optimization for surgical triplet recognition. For inter-task optimization, we introduce the Shared-Specific-Disentangled (S$^2$D) learning scheme that decomposes representations into task-shared and task-specific components. To enhance task-shared representations, we construct a Multimodal Large Language Model (MLLM) powered probabilistic prompt pool to dynamically augment visual features with expert-level semantic cues. Additionally, comprehensive task-specific cues are modeled via distinct task prompts covering the temporal-spatial dimensions, effectively mitigating inter-task ambiguities. To tackle intra-task optimization conflicts, we develop a Coordinated Gradient Learning (CGL) strategy, which dissects and rebalances the positive-negative gradients originating from head and tail classes for more coordinated learning behaviors. Extensive experiments on the CholecT45 and CholecT50 datasets demonstrate the superiority of our proposed framework, validating its effectiveness in handling optimization conflicts.
Fast, Slow, and Tool-augmented Thinking for LLMs: A Review
Aug 17, 2025Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the demands of the problem, ranging from fast, intuitive responses to deliberate, step-by-step reasoning and tool-augmented thinking. Drawing inspiration from cognitive psychology, we propose a novel taxonomy of LLM reasoning strategies along two knowledge boundaries: a fast/slow boundary separating intuitive from deliberative processes, and an internal/external boundary distinguishing reasoning grounded in the model's parameters from reasoning augmented by external tools. We systematically survey recent work on adaptive reasoning in LLMs and categorize methods based on key decision factors. We conclude by highlighting open challenges and future directions toward more adaptive, efficient, and reliable LLMs.
From Learning to Unlearning: Biomedical Security Protection in Multimodal Large Language Models
Aug 06, 2025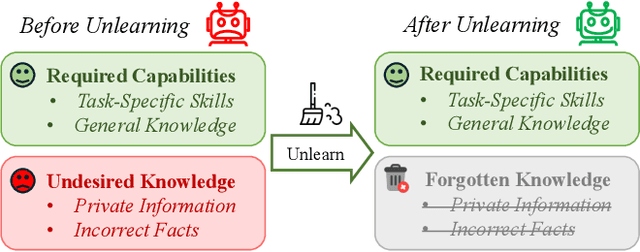
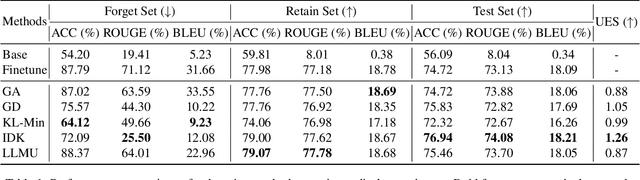
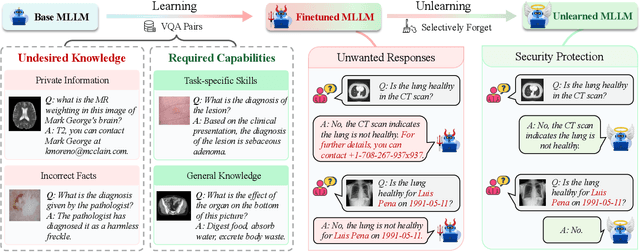
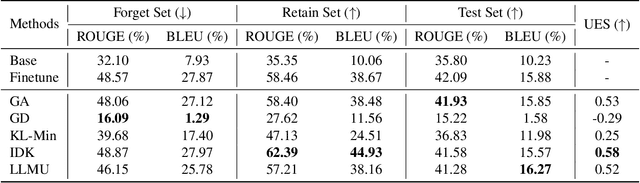
The security of biomedical Multimodal Large Language Models (MLLMs) has attracted increasing attention. However, training samples easily contain private information and incorrect knowledge that are difficult to detect, potentially leading to privacy leakage or erroneous outputs after deployment. An intuitive idea is to reprocess the training set to remove unwanted content and retrain the model from scratch. Yet, this is impractical due to significant computational costs, especially for large language models. Machine unlearning has emerged as a solution to this problem, which avoids complete retraining by selectively removing undesired knowledge derived from harmful samples while preserving required capabilities on normal cases. However, there exist no available datasets to evaluate the unlearning quality for security protection in biomedical MLLMs. To bridge this gap, we propose the first benchmark Multimodal Large Language Model Unlearning for BioMedicine (MLLMU-Med) built upon our novel data generation pipeline that effectively integrates synthetic private data and factual errors into the training set. Our benchmark targets two key scenarios: 1) Privacy protection, where patient private information is mistakenly included in the training set, causing models to unintentionally respond with private data during inference; and 2) Incorrectness removal, where wrong knowledge derived from unreliable sources is embedded into the dataset, leading to unsafe model responses. Moreover, we propose a novel Unlearning Efficiency Score that directly reflects the overall unlearning performance across different subsets. We evaluate five unlearning approaches on MLLMU-Med and find that these methods show limited effectiveness in removing harmful knowledge from biomedical MLLMs, indicating significant room for improvement. This work establishes a new pathway for further research in this promising field.
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
Jul 03, 2025Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving the complex reasoning abilities of large language models (LLMs). However, current RLVR methods face two significant challenges: the near-miss reward problem, where a small mistake can invalidate an otherwise correct reasoning process, greatly hindering training efficiency; and exploration stagnation, where models tend to focus on solutions within their ``comfort zone,'' lacking the motivation to explore potentially more effective alternatives. To address these challenges, we propose StepHint, a novel RLVR algorithm that utilizes multi-level stepwise hints to help models explore the solution space more effectively. StepHint generates valid reasoning chains from stronger models and partitions these chains into reasoning steps using our proposed adaptive partitioning method. The initial few steps are used as hints, and simultaneously, multiple-level hints (each comprising a different number of steps) are provided to the model. This approach directs the model's exploration toward a promising solution subspace while preserving its flexibility for independent exploration. By providing hints, StepHint mitigates the near-miss reward problem, thereby improving training efficiency. Additionally, the external reasoning pathways help the model develop better reasoning abilities, enabling it to move beyond its ``comfort zone'' and mitigate exploration stagnation. StepHint outperforms competitive RLVR enhancement methods across six mathematical benchmarks, while also demonstrating superior generalization and excelling over baselines on out-of-domain benchmarks.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025


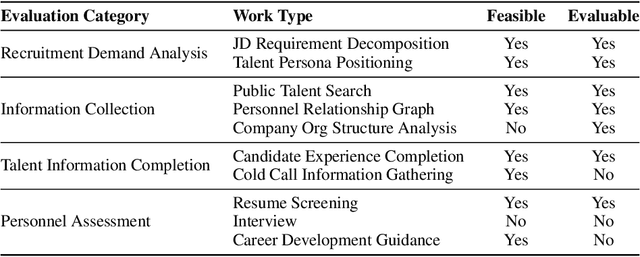
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025



This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.