 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Mar 10, 2026Unified multimodal models (UMMs) that integrate understanding, reasoning, generation, and editing face inherent trade-offs between maintaining strong semantic comprehension and acquiring powerful generation capabilities. In this report, we present InternVL-U, a lightweight 4B-parameter UMM that democratizes these capabilities within a unified framework. Guided by the principles of unified contextual modeling and modality-specific modular design with decoupled visual representations, InternVL-U integrates a state-of-the-art Multimodal Large Language Model (MLLM) with a specialized MMDiT-based visual generation head. To further bridge the gap between aesthetic generation and high-level intelligence, we construct a comprehensive data synthesis pipeline targeting high-semantic-density tasks, such as text rendering and scientific reasoning, under a reasoning-centric paradigm that leverages Chain-of-Thought (CoT) to better align abstract user intent with fine-grained visual generation details. Extensive experiments demonstrate that InternVL-U achieves a superior performance - efficiency balance. Despite using only 4B parameters, it consistently outperforms unified baseline models with over 3x larger scales such as BAGEL (14B) on various generation and editing tasks, while retaining strong multimodal understanding and reasoning capabilities.
GenExam: A Multidisciplinary Text-to-Image Exam
Sep 17, 2025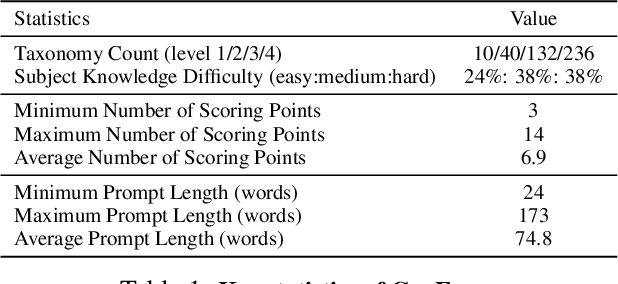

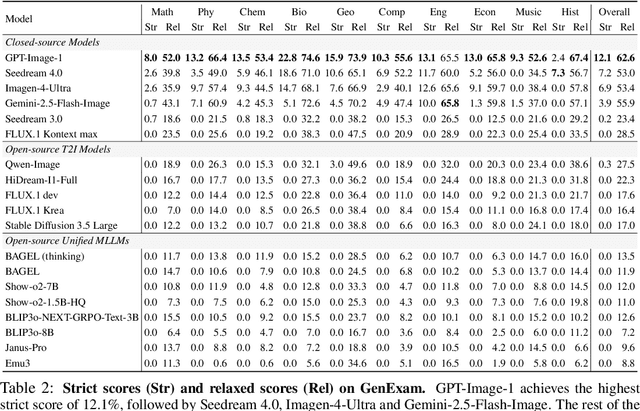

Exams are a fundamental test of expert-level intelligence and require integrated understanding, reasoning, and generation. Existing exam-style benchmarks mainly focus on understanding and reasoning tasks, and current generation benchmarks emphasize the illustration of world knowledge and visual concepts, neglecting the evaluation of rigorous drawing exams. We introduce GenExam, the first benchmark for multidisciplinary text-to-image exams, featuring 1,000 samples across 10 subjects with exam-style prompts organized under a four-level taxonomy. Each problem is equipped with ground-truth images and fine-grained scoring points to enable a precise evaluation of semantic correctness and visual plausibility. Experiments show that even state-of-the-art models such as GPT-Image-1 and Gemini-2.5-Flash-Image achieve less than 15% strict scores, and most models yield almost 0%, suggesting the great challenge of our benchmark. By framing image generation as an exam, GenExam offers a rigorous assessment of models' ability to integrate knowledge, reasoning, and generation, providing insights on the path to general AGI.