 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Core Memory Management and Consolidation for Long-term Continual Learning
May 15, 2025



In this paper, we focus on a long-term continual learning (CL) task, where a model learns sequentially from a stream of vast tasks over time, acquiring new knowledge while retaining previously learned information in a manner akin to human learning. Unlike traditional CL settings, long-term CL involves handling a significantly larger number of tasks, which exacerbates the issue of catastrophic forgetting. Our work seeks to address two critical questions: 1) How do existing CL methods perform in the context of long-term CL? and 2) How can we mitigate the catastrophic forgetting that arises from prolonged sequential updates? To tackle these challenges, we propose a novel framework inspired by human memory mechanisms for long-term continual learning (Long-CL). Specifically, we introduce a task-core memory management strategy to efficiently index crucial memories and adaptively update them as learning progresses. Additionally, we develop a long-term memory consolidation mechanism that selectively retains hard and discriminative samples, ensuring robust knowledge retention. To facilitate research in this area, we construct and release two multi-modal and textual benchmarks, MMLongCL-Bench and TextLongCL-Bench, providing a valuable resource for evaluating long-term CL approaches. Experimental results show that Long-CL outperforms the previous state-of-the-art by 7.4\% and 6.5\% AP on the two benchmarks, respectively, demonstrating the effectiveness of our approach.
Continuous Visual Autoregressive Generation via Score Maximization
May 12, 2025



Conventional wisdom suggests that autoregressive models are used to process discrete data. When applied to continuous modalities such as visual data, Visual AutoRegressive modeling (VAR) typically resorts to quantization-based approaches to cast the data into a discrete space, which can introduce significant information loss. To tackle this issue, we introduce a Continuous VAR framework that enables direct visual autoregressive generation without vector quantization. The underlying theoretical foundation is strictly proper scoring rules, which provide powerful statistical tools capable of evaluating how well a generative model approximates the true distribution. Within this framework, all we need is to select a strictly proper score and set it as the training objective to optimize. We primarily explore a class of training objectives based on the energy score, which is likelihood-free and thus overcomes the difficulty of making probabilistic predictions in the continuous space. Previous efforts on continuous autoregressive generation, such as GIVT and diffusion loss, can also be derived from our framework using other strictly proper scores. Source code: https://github.com/shaochenze/EAR.
Examining the Source of Defects from a Mechanical Perspective for 3D Anomaly Detection
May 09, 2025In this paper, we go beyond identifying anomalies only in structural terms and think about better anomaly detection motivated by anomaly causes. Most anomalies are regarded as the result of unpredictable defective forces from internal and external sources, and their opposite forces are sought to correct the anomalies. We introduced a Mechanics Complementary framework for 3D anomaly detection (MC4AD) to generate internal and external Corrective forces for each point. A Diverse Anomaly-Generation (DA-Gen) module is first proposed to simulate various anomalies. Then, we present a Corrective Force Prediction Network (CFP-Net) with complementary representations for point-level representation to simulate the different contributions of internal and external corrective forces. A combined loss was proposed, including a new symmetric loss and an overall loss, to constrain the corrective forces properly. As a highlight, we consider 3D anomaly detection in industry more comprehensively, creating a hierarchical quality control strategy based on a three-way decision and contributing a dataset named Anomaly-IntraVariance with intraclass variance to evaluate the model. On the proposed and existing five datasets, we obtained nine state-of-the-art performers with the minimum parameters and the fastest inference speed. The source is available at https://github.com/hzzzzzhappy/MC4AD
ConCISE: Confidence-guided Compression in Step-by-step Efficient Reasoning
May 08, 2025Large Reasoning Models (LRMs) perform strongly in complex reasoning tasks via Chain-of-Thought (CoT) prompting, but often suffer from verbose outputs caused by redundant content, increasing computational overhead, and degrading user experience. Existing compression methods either operate post-hoc pruning, risking disruption to reasoning coherence, or rely on sampling-based selection, which fails to intervene effectively during generation. In this work, we introduce a confidence-guided perspective to explain the emergence of redundant reflection in LRMs, identifying two key patterns: Confidence Deficit, where the model reconsiders correct steps due to low internal confidence, and Termination Delay, where reasoning continues even after reaching a confident answer. Based on this analysis, we propose ConCISE (Confidence-guided Compression In Step-by-step Efficient Reasoning), a framework that simplifies reasoning chains by reinforcing the model's confidence during inference, thus preventing the generation of redundant reflection steps. It integrates Confidence Injection to stabilize intermediate steps and Early Stopping to terminate reasoning when confidence is sufficient. Extensive experiments demonstrate that fine-tuning LRMs on ConCISE-generated data yields significantly shorter outputs, reducing length by up to approximately 50% under SimPO, while maintaining high task accuracy. ConCISE consistently outperforms existing baselines across multiple reasoning benchmarks.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025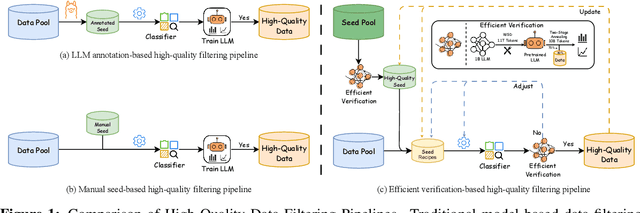



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
Image Recognition with Online Lightweight Vision Transformer: A Survey
May 06, 2025The Transformer architecture has achieved significant success in natural language processing, motivating its adaptation to computer vision tasks. Unlike convolutional neural networks, vision transformers inherently capture long-range dependencies and enable parallel processing, yet lack inductive biases and efficiency benefits, facing significant computational and memory challenges that limit its real-world applicability. This paper surveys various online strategies for generating lightweight vision transformers for image recognition, focusing on three key areas: Efficient Component Design, Dynamic Network, and Knowledge Distillation. We evaluate the relevant exploration for each topic on the ImageNet-1K benchmark, analyzing trade-offs among precision, parameters, throughput, and more to highlight their respective advantages, disadvantages, and flexibility. Finally, we propose future research directions and potential challenges in the lightweighting of vision transformers with the aim of inspiring further exploration and providing practical guidance for the community. Project Page: https://github.com/ajxklo/Lightweight-VIT
Fixed-Length Dense Fingerprint Representation
May 06, 2025Fixed-length fingerprint representations, which map each fingerprint to a compact and fixed-size feature vector, are computationally efficient and well-suited for large-scale matching. However, designing a robust representation that effectively handles diverse fingerprint modalities, pose variations, and noise interference remains a significant challenge. In this work, we propose a fixed-length dense descriptor of fingerprints, and introduce FLARE-a fingerprint matching framework that integrates the Fixed-Length dense descriptor with pose-based Alignment and Robust Enhancement. This fixed-length representation employs a three-dimensional dense descriptor to effectively capture spatial relationships among fingerprint ridge structures, enabling robust and locally discriminative representations. To ensure consistency within this dense feature space, FLARE incorporates pose-based alignment using complementary estimation methods, along with dual enhancement strategies that refine ridge clarity while preserving the original fingerprint modality. The proposed dense descriptor supports fixed-length representation while maintaining spatial correspondence, enabling fast and accurate similarity computation. Extensive experiments demonstrate that FLARE achieves superior performance across rolled, plain, latent, and contactless fingerprints, significantly outperforming existing methods in cross-modality and low-quality scenarios. Further analysis validates the effectiveness of the dense descriptor design, as well as the impact of alignment and enhancement modules on the accuracy of dense descriptor matching. Experimental results highlight the effectiveness and generalizability of FLARE as a unified and scalable solution for robust fingerprint representation and matching. The implementation and code will be publicly available at https://github.com/Yu-Yy/FLARE.
Finger Pose Estimation for Under-screen Fingerprint Sensor
May 05, 2025Two-dimensional pose estimation plays a crucial role in fingerprint recognition by facilitating global alignment and reduce pose-induced variations. However, existing methods are still unsatisfactory when handling with large angle or small area inputs. These limitations are particularly pronounced on fingerprints captured by under-screen fingerprint sensors in smartphones. In this paper, we present a novel dual-modal input based network for under-screen fingerprint pose estimation. Our approach effectively integrates two distinct yet complementary modalities: texture details extracted from ridge patches through the under-screen fingerprint sensor, and rough contours derived from capacitive images obtained via the touch screen. This collaborative integration endows our network with more comprehensive and discriminative information, substantially improving the accuracy and stability of pose estimation. A decoupled probability distribution prediction task is designed, instead of the traditional supervised forms of numerical regression or heatmap voting, to facilitate the training process. Additionally, we incorporate a Mixture of Experts (MoE) based feature fusion mechanism and a relationship driven cross-domain knowledge transfer strategy to further strengthen feature extraction and fusion capabilities. Extensive experiments are conducted on several public datasets and two private datasets. The results indicate that our method is significantly superior to previous state-of-the-art (SOTA) methods and remarkably boosts the recognition ability of fingerprint recognition algorithms. Our code is available at https://github.com/XiongjunGuan/DRACO.
A Survey of Slow Thinking-based Reasoning LLMs using Reinforced Learning and Inference-time Scaling Law
May 05, 2025



This survey explores recent advancements in reasoning large language models (LLMs) designed to mimic "slow thinking" - a reasoning process inspired by human cognition, as described in Kahneman's Thinking, Fast and Slow. These models, like OpenAI's o1, focus on scaling computational resources dynamically during complex tasks, such as math reasoning, visual reasoning, medical diagnosis, and multi-agent debates. We present the development of reasoning LLMs and list their key technologies. By synthesizing over 100 studies, it charts a path toward LLMs that combine human-like deep thinking with scalable efficiency for reasoning. The review breaks down methods into three categories: (1) test-time scaling dynamically adjusts computation based on task complexity via search and sampling, dynamic verification; (2) reinforced learning refines decision-making through iterative improvement leveraging policy networks, reward models, and self-evolution strategies; and (3) slow-thinking frameworks (e.g., long CoT, hierarchical processes) that structure problem-solving with manageable steps. The survey highlights the challenges and further directions of this domain. Understanding and advancing the reasoning abilities of LLMs is crucial for unlocking their full potential in real-world applications, from scientific discovery to decision support systems.
MC3D-AD: A Unified Geometry-aware Reconstruction Model for Multi-category 3D Anomaly Detection
May 04, 2025



3D Anomaly Detection (AD) is a promising means of controlling the quality of manufactured products. However, existing methods typically require carefully training a task-specific model for each category independently, leading to high cost, low efficiency, and weak generalization. Therefore, this paper presents a novel unified model for Multi-Category 3D Anomaly Detection (MC3D-AD) that aims to utilize both local and global geometry-aware information to reconstruct normal representations of all categories. First, to learn robust and generalized features of different categories, we propose an adaptive geometry-aware masked attention module that extracts geometry variation information to guide mask attention. Then, we introduce a local geometry-aware encoder reinforced by the improved mask attention to encode group-level feature tokens. Finally, we design a global query decoder that utilizes point cloud position embeddings to improve the decoding process and reconstruction ability. This leads to local and global geometry-aware reconstructed feature tokens for the AD task. MC3D-AD is evaluated on two publicly available Real3D-AD and Anomaly-ShapeNet datasets, and exhibits significant superiority over current state-of-the-art single-category methods, achieving 3.1\% and 9.3\% improvement in object-level AUROC over Real3D-AD and Anomaly-ShapeNet, respectively. The source code will be released upon acceptance.