 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-VIL: Keypoints-based Visual Imitation Learning
Sep 07, 2022
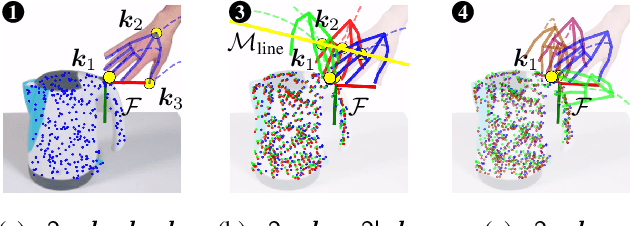
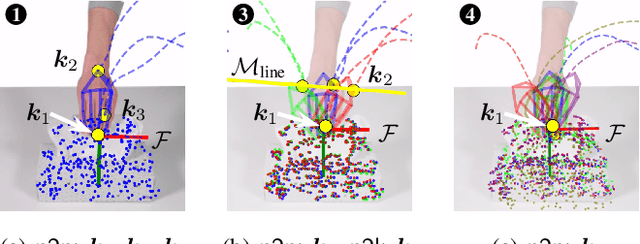
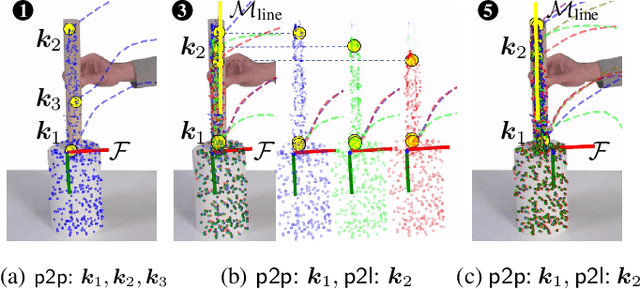
Visual imitation learning provides efficient and intuitive solutions for robotic systems to acquire novel manipulation skills. However, simultaneously learning geometric task constraints and control policies from visual inputs alone remains a challenging problem. In this paper, we propose an approach for keypoint-based visual imitation (K-VIL) that automatically extracts sparse, object-centric, and embodiment-independent task representations from a small number of human demonstration videos. The task representation is composed of keypoint-based geometric constraints on principal manifolds, their associated local frames, and the movement primitives that are then needed for the task execution. Our approach is capable of extracting such task representations from a single demonstration video, and of incrementally updating them when new demonstrations become available. To reproduce manipulation skills using the learned set of prioritized geometric constraints in novel scenes, we introduce a novel keypoint-based admittance controller. We evaluate our approach in several real-world applications, showcasing its ability to deal with cluttered scenes, new instances of categorical objects, and large object pose and shape variations, as well as its efficiency and robustness in both one-shot and few-shot imitation learning settings. Videos and source code are available at https://sites.google.com/view/k-vil.
Optimizing Bi-Encoder for Named Entity Recognition via Contrastive Learning
Aug 30, 2022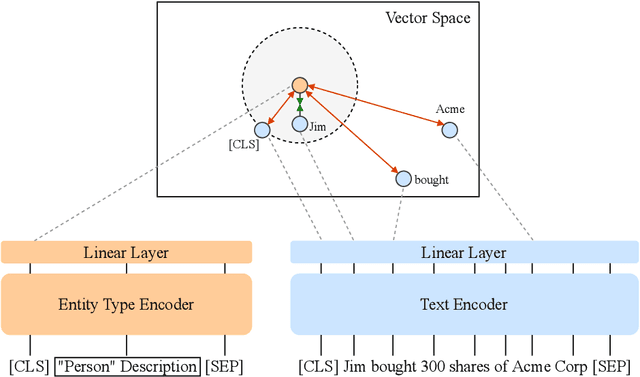
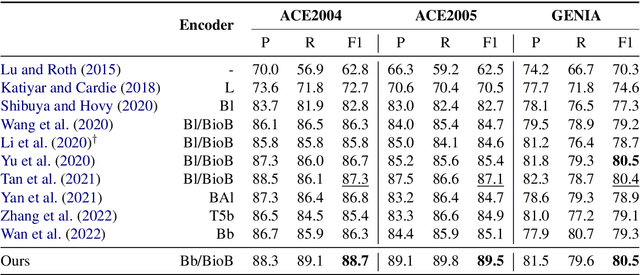
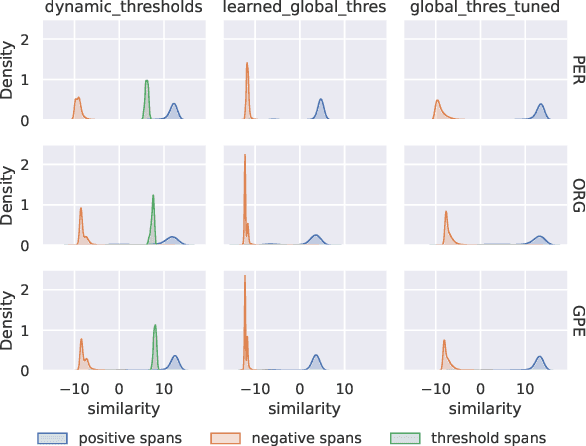
We present an efficient bi-encoder framework for named entity recognition (NER), which applies contrastive learning to map candidate text spans and entity types into the same vector representation space. Prior work predominantly approaches NER as sequence labeling or span classification. We instead frame NER as a metric learning problem that maximizes the similarity between the vector representations of an entity mention and its type. This makes it easy to handle nested and flat NER alike, and can better leverage noisy self-supervision signals. A major challenge to this bi-encoder formulation for NER lies in separating non-entity spans from entity mentions. Instead of explicitly labeling all non-entity spans as the same class Outside (O) as in most prior methods, we introduce a novel dynamic thresholding loss, which is learned in conjunction with the standard contrastive loss. Experiments show that our method performs well in both supervised and distantly supervised settings, for nested and flat NER alike, establishing new state of the art across standard datasets in the general domain (e.g., ACE2004, ACE2005) and high-value verticals such as biomedicine (e.g., GENIA, NCBI, BC5CDR, JNLPBA).
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
Aug 21, 2022

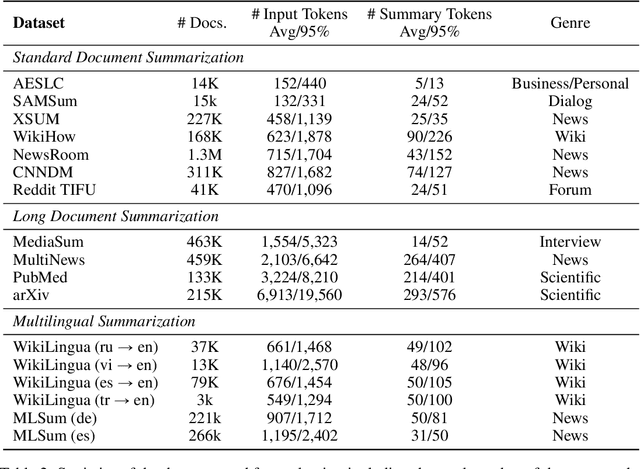
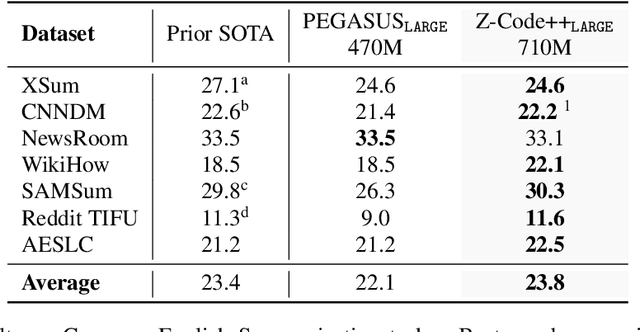
This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022
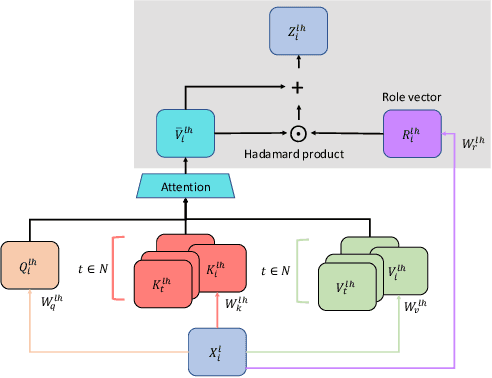

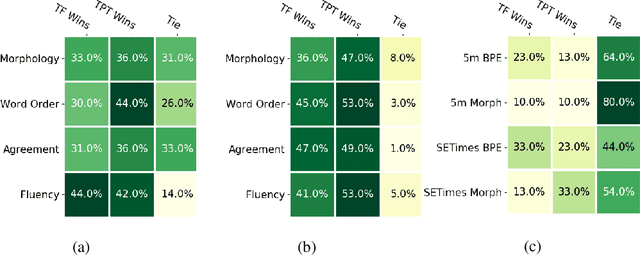
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
Interactive Code Generation via Test-Driven User-Intent Formalization
Aug 11, 2022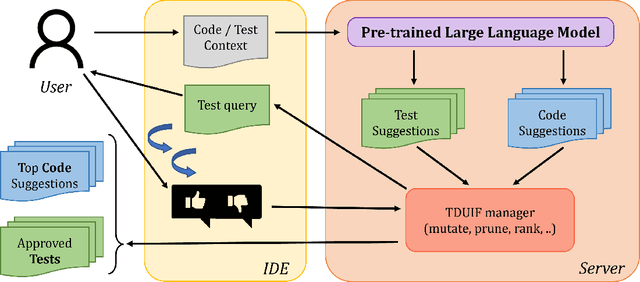



Pre-trained large language models (LLMs) such as OpenAI Codex have shown immense potential in automating significant aspects of coding by producing natural code from informal natural language (NL) intent. However, the code produced does not have any correctness guarantees around satisfying user's intent. In fact, it is hard to define a notion of correctness since natural language can be ambiguous and lacks a formal semantics. In this paper, we take a first step towards addressing the problem above by proposing the workflow of test-driven user-intent formalization (TDUIF), which leverages lightweight user feedback to jointly (a) formalize the user intent as tests (a partial specification), and (b) generates code that meets the formal user intent. To perform a scalable and large-scale automated evaluation of the algorithms without requiring a user in the loop, we describe how to simulate user interaction with high-fidelity using a reference solution. We also describe and implement alternate implementations of several algorithmic components (including mutating and ranking a set of tests) that can be composed for efficient solutions to the TDUIF problem. We have developed a system TICODER that implements several solutions to TDUIF, and compare their relative effectiveness on the MBPP academic code generation benchmark. Our results are promising with using the OpenAI Codex LLM on MBPP: our best algorithm improves the pass@1 code generation accuracy metric from 48.39% to 70.49% with a single user query, and up to 85.48% with up to 5 user queries. Second, we can generate a non-trivial functional unit test consistent with the user intent within an average of 1.69 user queries for 90.40% of the examples for this dataset.
OPERA: Harmonizing Task-Oriented Dialogs and Information Seeking Experience
Jun 24, 2022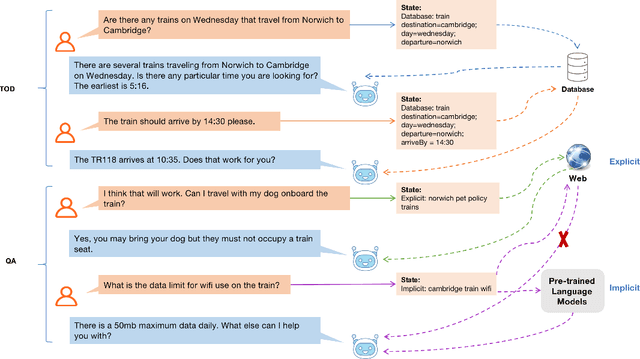
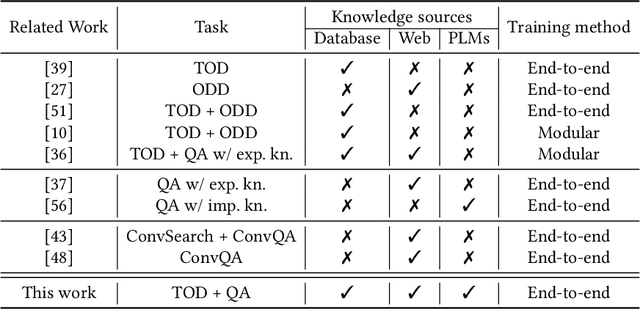
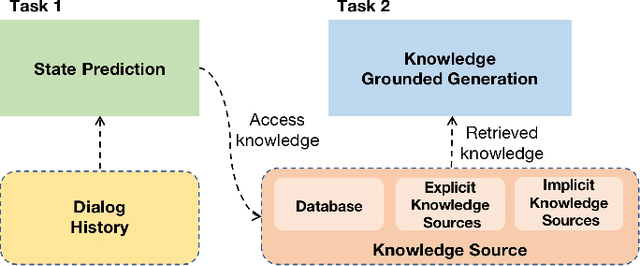

Existing studies in conversational AI mostly treat task-oriented dialog (TOD) and question answering (QA) as separate tasks. Towards the goal of constructing a conversational agent that can complete user tasks and support information seeking, it is important to build a system that handles both TOD and QA with access to various external knowledge. In this work, we propose a new task, Open-Book TOD (OB-TOD), which combines TOD with QA task and expand external knowledge sources to include both explicit knowledge sources (e.g., the Web) and implicit knowledge sources (e.g., pre-trained language models). We create a new dataset OB-MultiWOZ, where we enrich TOD sessions with QA-like information seeking experience grounded on external knowledge. We propose a unified model OPERA (Open-book End-to-end Task-oriented Dialog) which can appropriately access explicit and implicit external knowledge to tackle the defined task. Experimental results demonstrate OPERA's superior performance compared to closed-book baselines and illustrate the value of both knowledge types.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022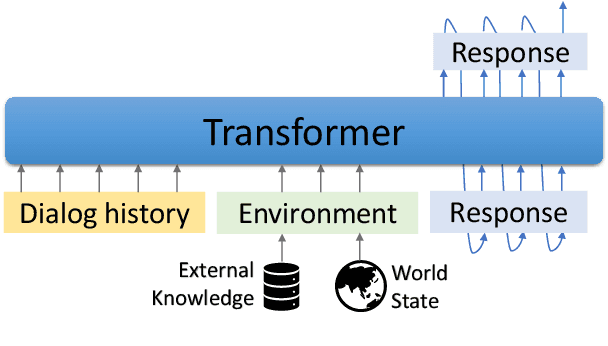
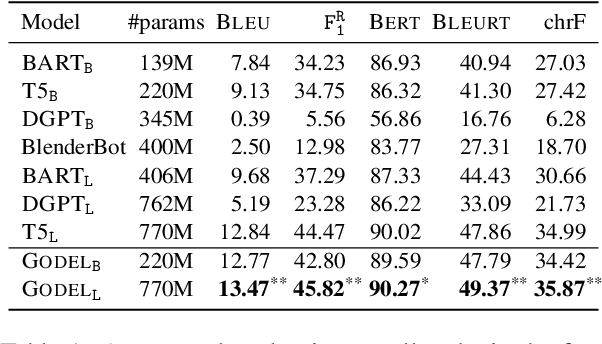

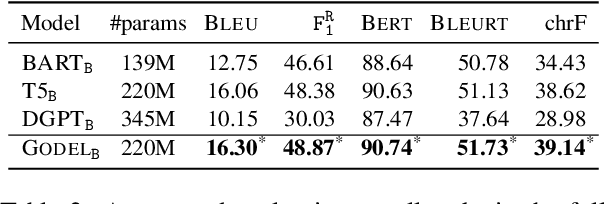
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
Jun 15, 2022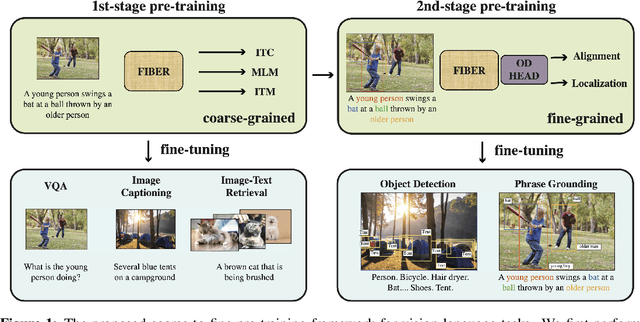

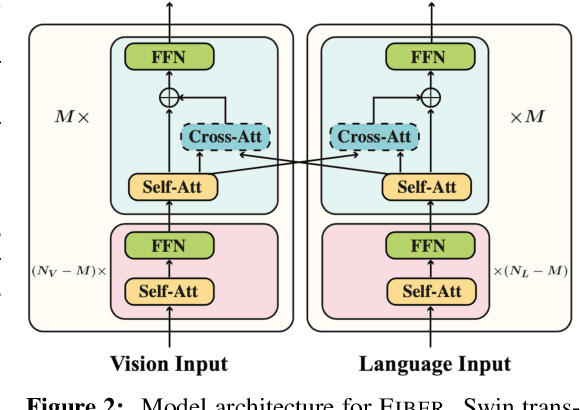
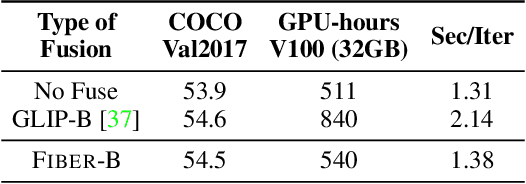
Vision-language (VL) pre-training has recently received considerable attention. However, most existing end-to-end pre-training approaches either only aim to tackle VL tasks such as image-text retrieval, visual question answering (VQA) and image captioning that test high-level understanding of images, or only target region-level understanding for tasks such as phrase grounding and object detection. We present FIBER (Fusion-In-the-Backbone-based transformER), a new VL model architecture that can seamlessly handle both these types of tasks. Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. In addition, unlike previous work that is either only pre-trained on image-text data or on fine-grained data with box-level annotations, we present a two-stage pre-training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. We conduct comprehensive experiments on a wide range of VL tasks, ranging from VQA, image captioning, and retrieval, to phrase grounding, referring expression comprehension, and object detection. Using deep multimodal fusion coupled with the two-stage pre-training, FIBER provides consistent performance improvements over strong baselines across all tasks, often outperforming methods using magnitudes more data. Code is available at https://github.com/microsoft/FIBER.
GLIPv2: Unifying Localization and Vision-Language Understanding
Jun 12, 2022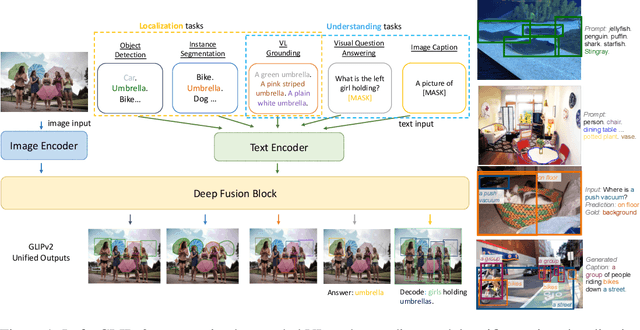
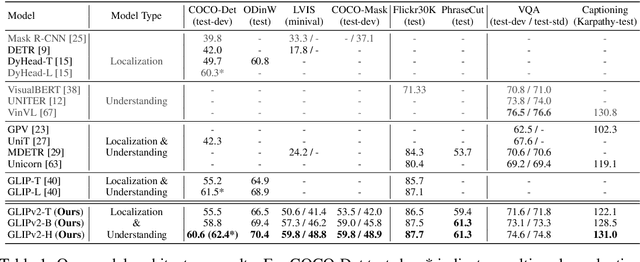
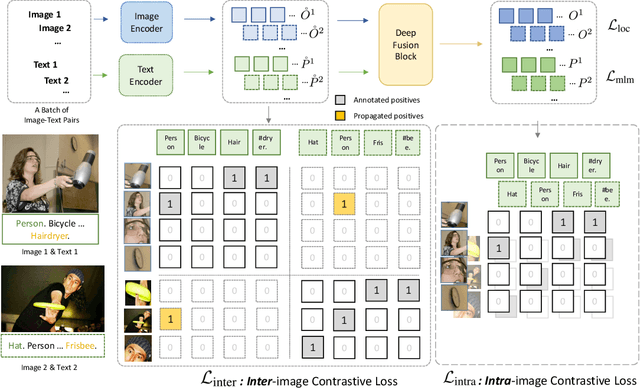
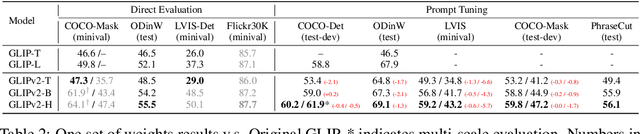
We present GLIPv2, a grounded VL understanding model, that serves both localization tasks (e.g., object detection, instance segmentation) and Vision-Language (VL) understanding tasks (e.g., VQA, image captioning). GLIPv2 elegantly unifies localization pre-training and Vision-Language Pre-training (VLP) with three pre-training tasks: phrase grounding as a VL reformulation of the detection task, region-word contrastive learning as a novel region-word level contrastive learning task, and the masked language modeling. This unification not only simplifies the previous multi-stage VLP procedure but also achieves mutual benefits between localization and understanding tasks. Experimental results show that a single GLIPv2 model (all model weights are shared) achieves near SoTA performance on various localization and understanding tasks. The model also shows (1) strong zero-shot and few-shot adaption performance on open-vocabulary object detection tasks and (2) superior grounding capability on VL understanding tasks. Code will be released at https://github.com/microsoft/GLIP.
Fault-Aware Neural Code Rankers
Jun 04, 2022

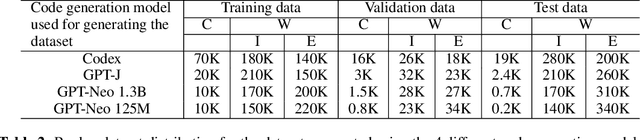

Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.