 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Alignment in LVLMs with Debiased Self-Judgment
Aug 28, 2025



The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations--where generated outputs are not grounded in the visual input--and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.
Mimicking the Physicist's Eye:A VLM-centric Approach for Physics Formula Discovery
Aug 24, 2025



Automated discovery of physical laws from observational data in the real world is a grand challenge in AI. Current methods, relying on symbolic regression or LLMs, are limited to uni-modal data and overlook the rich, visual phenomenological representations of motion that are indispensable to physicists. This "sensory deprivation" severely weakens their ability to interpret the inherent spatio-temporal patterns within dynamic phenomena. To address this gap, we propose VIPER-R1, a multimodal model that performs Visual Induction for Physics-based Equation Reasoning to discover fundamental symbolic formulas. It integrates visual perception, trajectory data, and symbolic reasoning to emulate the scientific discovery process. The model is trained via a curriculum of Motion Structure Induction (MSI), using supervised fine-tuning to interpret kinematic phase portraits and to construct hypotheses guided by a Causal Chain of Thought (C-CoT), followed by Reward-Guided Symbolic Calibration (RGSC) to refine the formula structure with reinforcement learning. During inference, the trained VIPER-R1 acts as an agent: it first posits a high-confidence symbolic ansatz, then proactively invokes an external symbolic regression tool to perform Symbolic Residual Realignment (SR^2). This final step, analogous to a physicist's perturbation analysis, reconciles the theoretical model with empirical data. To support this research, we introduce PhysSymbol, a new 5,000-instance multimodal corpus. Experiments show that VIPER-R1 consistently outperforms state-of-the-art VLM baselines in accuracy and interpretability, enabling more precise discovery of physical laws. Project page: https://jiaaqiliu.github.io/VIPER-R1/
Efficient Long CoT Reasoning in Small Language Models
May 24, 2025Recent large reasoning models such as DeepSeek-R1 exhibit strong complex problems solving abilities by generating long chain-of-thought (CoT) reasoning steps. It is challenging to directly train small language models (SLMs) to emerge long CoT. Thus, distillation becomes a practical method to enable SLMs for such reasoning ability. However, the long CoT often contains a lot of redundant contents (e.g., overthinking steps) which may make SLMs hard to learn considering their relatively poor capacity and generalization. To address this issue, we propose a simple-yet-effective method to prune unnecessary steps in long CoT, and then employ an on-policy method for the SLM itself to curate valid and useful long CoT training data. In this way, SLMs can effectively learn efficient long CoT reasoning and preserve competitive performance at the same time. Experimental results across a series of mathematical reasoning benchmarks demonstrate the effectiveness of the proposed method in distilling long CoT reasoning ability into SLMs which maintains the competitive performance but significantly reduces generating redundant reasoning steps.
From EduVisBench to EduVisAgent: A Benchmark and Multi-Agent Framework for Pedagogical Visualization
May 22, 2025
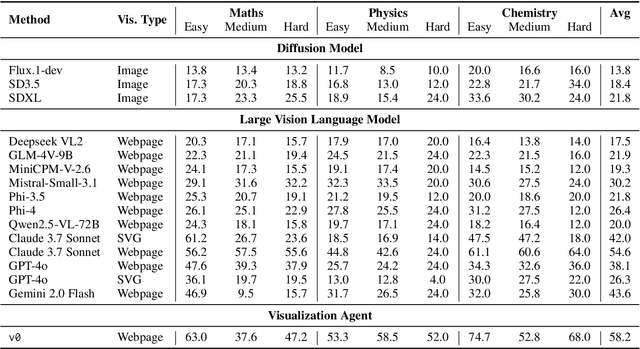
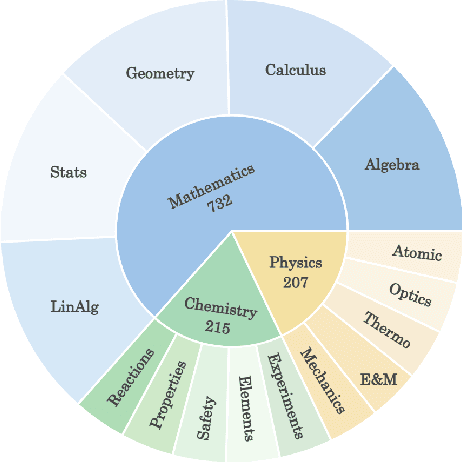
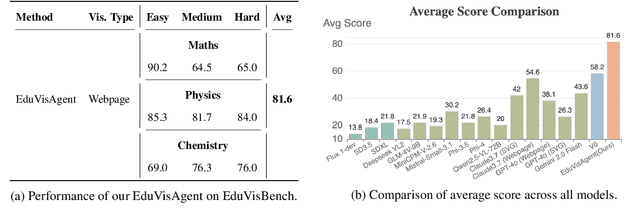
While foundation models (FMs), such as diffusion models and large vision-language models (LVLMs), have been widely applied in educational contexts, their ability to generate pedagogically effective visual explanations remains limited. Most existing approaches focus primarily on textual reasoning, overlooking the critical role of structured and interpretable visualizations in supporting conceptual understanding. To better assess the visual reasoning capabilities of FMs in educational settings, we introduce EduVisBench, a multi-domain, multi-level benchmark. EduVisBench features diverse STEM problem sets requiring visually grounded solutions, along with a fine-grained evaluation rubric informed by pedagogical theory. Our empirical analysis reveals that existing models frequently struggle with the inherent challenge of decomposing complex reasoning and translating it into visual representations aligned with human cognitive processes. To address these limitations, we propose EduVisAgent, a multi-agent collaborative framework that coordinates specialized agents for instructional planning, reasoning decomposition, metacognitive prompting, and visualization design. Experimental results show that EduVisAgent substantially outperforms all baselines, achieving a 40.2% improvement and delivering more educationally aligned visualizations. EduVisBench and EduVisAgent are available at https://github.com/aiming-lab/EduVisBench and https://github.com/aiming-lab/EduVisAgent.
CellTypeAgent: Trustworthy cell type annotation with Large Language Models
May 13, 2025Cell type annotation is a critical yet laborious step in single-cell RNA sequencing analysis. We present a trustworthy large language model (LLM)-agent, CellTypeAgent, which integrates LLMs with verification from relevant databases. CellTypeAgent achieves higher accuracy than existing methods while mitigating hallucinations. We evaluated CellTypeAgent across nine real datasets involving 303 cell types from 36 tissues. This combined approach holds promise for more efficient and reliable cell type annotation.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025



High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
Synergistic Weak-Strong Collaboration by Aligning Preferences
Apr 22, 2025Current Large Language Models (LLMs) excel in general reasoning yet struggle with specialized tasks requiring proprietary or domain-specific knowledge. Fine-tuning large models for every niche application is often infeasible due to black-box constraints and high computational overhead. To address this, we propose a collaborative framework that pairs a specialized weak model with a general strong model. The weak model, tailored to specific domains, produces initial drafts and background information, while the strong model leverages its advanced reasoning to refine these drafts, extending LLMs' capabilities to critical yet specialized tasks. To optimize this collaboration, we introduce a collaborative feedback to fine-tunes the weak model, which quantifies the influence of the weak model's contributions in the collaboration procedure and establishes preference pairs to guide preference tuning of the weak model. We validate our framework through experiments on three domains. We find that the collaboration significantly outperforms each model alone by leveraging complementary strengths. Moreover, aligning the weak model with the collaborative preference further enhances overall performance.
Token Level Routing Inference System for Edge Devices
Apr 10, 2025



The computational complexity of large language model (LLM) inference significantly constrains their deployment efficiency on edge devices. In contrast, small language models offer faster decoding and lower resource consumption but often suffer from degraded response quality and heightened susceptibility to hallucinations. To address this trade-off, collaborative decoding, in which a large model assists in generating critical tokens, has emerged as a promising solution. This paradigm leverages the strengths of both model types by enabling high-quality inference through selective intervention of the large model, while maintaining the speed and efficiency of the smaller model. In this work, we present a novel collaborative decoding inference system that allows small models to perform on-device inference while selectively consulting a cloud-based large model for critical token generation. Remarkably, the system achieves a 60% performance gain on CommonsenseQA using only a 0.5B model on an M1 MacBook, with under 7% of tokens generation uploaded to the large model in the cloud.
Weak-for-Strong: Training Weak Meta-Agent to Harness Strong Executors
Apr 07, 2025Efficiently leveraging of the capabilities of contemporary large language models (LLMs) is increasingly challenging, particularly when direct fine-tuning is expensive and often impractical. Existing training-free methods, including manually or automated designed workflows, typically demand substantial human effort or yield suboptimal results. This paper proposes Weak-for-Strong Harnessing (W4S), a novel framework that customizes smaller, cost-efficient language models to design and optimize workflows for harnessing stronger models. W4S formulates workflow design as a multi-turn markov decision process and introduces reinforcement learning for agentic workflow optimization (RLAO) to train a weak meta-agent. Through iterative interaction with the environment, the meta-agent learns to design increasingly effective workflows without manual intervention. Empirical results demonstrate the superiority of W4S that our 7B meta-agent, trained with just one GPU hour, outperforms the strongest baseline by 2.9% ~ 24.6% across eleven benchmarks, successfully elevating the performance of state-of-the-art models such as GPT-3.5-Turbo and GPT-4o. Notably, W4S exhibits strong generalization capabilities across both seen and unseen tasks, offering an efficient, high-performing alternative to directly fine-tuning strong models.