 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Near-field Indoor Channel Model for THz Bands Based on Surface Scattering Characteristics
Jun 01, 2026Terahertz (THz) communication and extremely large-scale MIMO (XL-MIMO) are essential for achieving ultra-high data rates in future 6G systems. However, at sub-millimeter wavelengths, typical indoor materials exhibit significant roughness that invalidates conventional ideal smooth surface assumptions, while massive array apertures introduce pronounced near-field effects and spatial non-stationarity. To address these challenges, this paper proposes a hybrid near-field channel model utilizing surface scattering characteristics based on distinct measurement campaigns. First, based on typical indoor materials scattering measurements across the 260-400 GHz band, an improved Beckmann-Kirchhoff (B-K) model is developed to accurately characterize surface roughness and diffuse scattering behavior. The model independently analyzes single-bounce (SB) and multi-bounce (MB) clusters by applying deterministic rough surface scattering theory and geometry-statistical approach, respectively. Then, using near-field spatial non-stationarity measurements from a 630-element virtual array in the 330-360 GHz band, a Dual-Gaussian Mixture Model (DMM) and a Negative Binomial (NB) distribution are adopted to describe the lengths and the number of spatial visibility regions (VRs), respectively. Additionally, a Weibull distribution is employed to model the intra-region power fluctuations. Finally, comprehensive XL-MIMO channel evaluations within the same band demonstrate that the proposed model aligns closely with measured results in terms of the spatial cross-correlation function (SCCF), frequency cross-correlation function (FCF), and channel capacity. By reproducing the spatial sparsity of THz band, the proposed model overcomes the limitation of conventional standard models, such as 3GPP 38.901 and WINNER II, in significantly overestimating channel capacity.
Task-Focused Memorization for Multimodal Agents
May 29, 2026Long-term memory is essential for multimodal agents to build coherent experience, accumulate world knowledge, and achieve continual learning. However, constructing effective memory goes beyond memory module design and basic requirements such as accuracy and fidelity; the key challenge lies in determining what to memorize. Multimodal agents, such as embodied agents, continuously perceive, reason, and act in real or virtual environments, receiving an unbounded stream of multimodal observations. From this combinatorial explosion of information, an agent must selectively retain content that is relevant to its role in the environment and valuable for future tasks. To bridge this gap, we frame memory generation as a learnable memorization policy and introduce TaskMem (Task-focused Memorization Policy Learning), a reinforcement-learning-based framework that enables the policy to dynamically adjust its focus to the demands of real tasks encountered in the environment. TaskMem adopts a two-phase training paradigm: Phase One learns how to memorize by optimizing memory quality under fundamental fidelity requirements; Phase Two occurs after deployment, where the agent learns what to memorize by tuning an adapter on its base MLLM, using recent environment tasks to define a reward model that guides the memorization policy toward task-relevant content. To evaluate our approach, we reformulate VideoMME, EgoLife, and EgoTempo into streaming benchmarks that simulate a realistic setting in which an agent processes streaming observations and handles tasks arriving online. To isolate memory assessment, the questions must be answered using only the agent's memory, without access to raw video. Built on Qwen3-VL-30B-A3B, TaskMem improves VQA accuracy by 6.3%, 7.0%, and 5.3% on these benchmarks, respectively.
Channel Measurements and Characterization with Phase Drift Compensation for Outdoor 330-360 GHz MIMO Communications
May 27, 2026In this paper, an outdoor channel measurement campaign at 330-360 GHz employing a 128 * 4 virtual antenna array (VAA)-based multiple-input multiple-output (MIMO) configuration is conducted. The transmitter (Tx) and receiver (Rx) location pairs are classified into line-of-sight (LoS) and obstructed-LoS (OLoS) scenarios to enable a detailed investigation of outdoor terahertz (THz) band channel characteristics. During the measurement process, the stationarity of the outdoor environment is carefully verified, and a linear phase drift (PD) effect is identified. Then, we propose a PD-aware Space-Alternating Generalized Expectation-Maximization (SAGE) algorithm, which significantly improves both delay resolution and channel parameter estimation accuracy. Based on the processed measurement data, we characterize key channel properties, including the power delay profile, path loss, shadow fading, delay spread, angular spread, Rician K-factor, as well as their cumulative distribution functions and correlation characteristics. In addition, near-field effects and MIMO-specific properties, including the spatial non-stationarity and the cluster birth-death property, are analyzed.
A Measurement-Based Parameterization of Physics Reflection Models for Terahertz Communication
May 22, 2026The accurate modeling of reflection coefficients is pivotal for developing reliable channel models in emerging terahertz (THz) communications. This study establishes a 300$\sim$400 GHz channel measurement platform to measure the reflection coefficients of various materials. Based on the analysis of measured data, we propose the single-layer interference with an extended-parameterized Lorentz/Drude (SLI-EPLD) reflection coefficient model. In this model, a sub-band modeling strategy is adopted to characterize the variation of reflection coefficients with frequency, while a parameterized mapping approach is employed to ensure the stability of model parameters. Furthermore, the weighted sub-band fitting for trend regression (WF-TREND) algorithm is introduced to achieve precise sub-band parameter fitting. Validation results demonstrate superior performance to existing models across multiple materials. The reflection coefficient model established in this work serves as a critical foundation for channel modeling in 300$\sim$400 GHz for high-THz communication.
Theoretical and Empirical Study of Spatial Power Focusing Effect for Sparse Arrays at Terahertz Band
Nov 19, 2025This work investigates the spatial power focusing effect for large-scale sparse arrays at terahertz (THz) band, combining theoretical analysis with experimental validation. Specifically, based on a Green's function channel model, we analyze the power distribution along the $z$-axis, deriving a closed-form expression to characterize the focusing effect. Furthermore, the factors influencing the focusing effect, including phase noise and positional deviations, are theoretically analyzed and numerically simulated. Finally, a 300 GHz measurement platform based on a vector network analyzer (VNA) is constructed for experimental validation. The measurement results demonstrate close consistence with theoretical simulation results, confirming the spatial power focusing effect for sparse arrays.
Mutual Coupling Aware Channel Estimation for RIS-Aided Multi-User mmWave Systems
Nov 11, 2025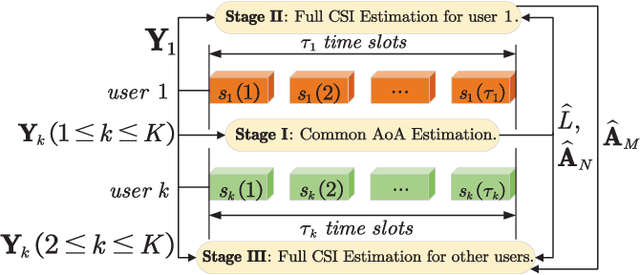
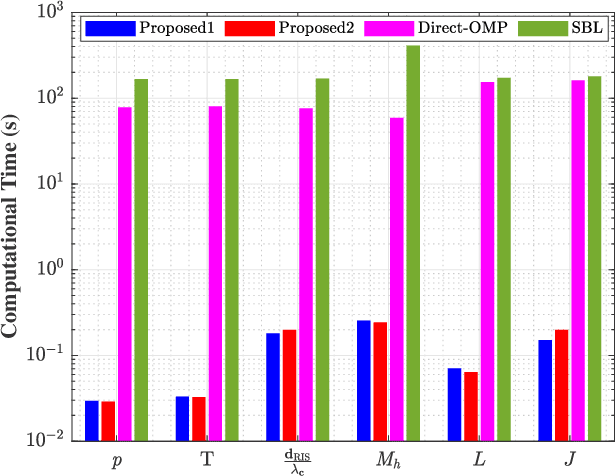
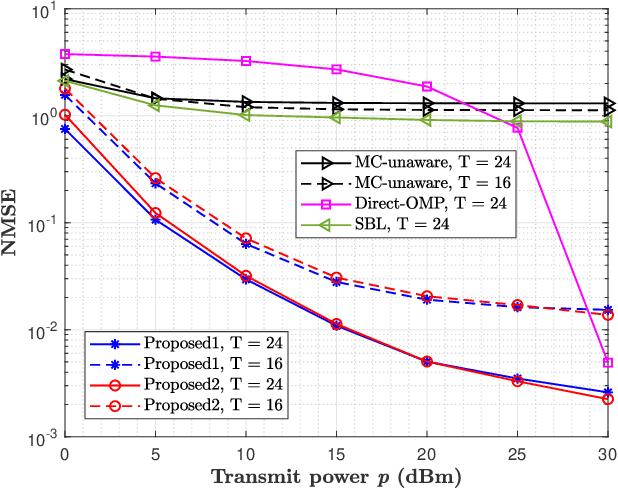
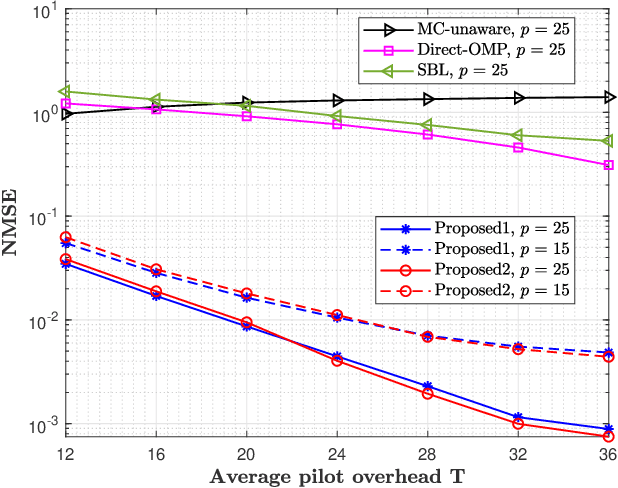
This paper proposes a three-stage uplink channel estimation protocol for reconfigurable intelligent surface (RIS)-aided multi-user (MU) millimeter-wave (mmWave) multiple-input single-output (MISO) systems, where both the base station (BS) and the RIS are equipped with uniform planar arrays (UPAs). The proposed approach explicitly accounts for the mutual coupling (MC) effect, modeled via scattering parameter multiport network theory. In Stage~I, a dimension-reduced subspace-based method is proposed to estimate the common angle of arrival (AoA) at the BS using the received signals across all users. In Stage~II, MC-aware cascaded channel estimation is performed for a typical user. The equivalent measurement vectors for each cascaded path are extracted and the reference column is reconstructed using a compressed sensing (CS)-based approach. By leveraging the structure of the cascaded channel, the reference column is rearranged to estimate the AoA at the RIS, thereby reducing the computational complexity associated with estimating other columns. Additionally, the common angle of departure (AoD) at the RIS is also obtained in this stage, which significantly reduces the pilot overhead for estimating the cascaded channels of other users in Stage~III. The RIS phase shift training matrix is designed to optimize performance in the presence of MC and outperforms random phase scheme. Simulation results validate that the proposed method yields better performance than the MC-unaware and existing approaches in terms of estimation accuracy and pilot efficiency.
PreResQ-R1: Towards Fine-Grained Rank-and-Score Reinforcement Learning for Visual Quality Assessment via Preference-Response Disentangled Policy Optimization
Nov 07, 2025Visual Quality Assessment (QA) seeks to predict human perceptual judgments of visual fidelity. While recent multimodal large language models (MLLMs) show promise in reasoning about image and video quality, existing approaches mainly rely on supervised fine-tuning or rank-only objectives, resulting in shallow reasoning, poor score calibration, and limited cross-domain generalization. We propose PreResQ-R1, a Preference-Response Disentangled Reinforcement Learning framework that unifies absolute score regression and relative ranking consistency within a single reasoning-driven optimization scheme. Unlike prior QA methods, PreResQ-R1 introduces a dual-branch reward formulation that separately models intra-sample response coherence and inter-sample preference alignment, optimized via Group Relative Policy Optimization (GRPO). This design encourages fine-grained, stable, and interpretable chain-of-thought reasoning about perceptual quality. To extend beyond static imagery, we further design a global-temporal and local-spatial data flow strategy for Video Quality Assessment. Remarkably, with reinforcement fine-tuning on only 6K images and 28K videos, PreResQ-R1 achieves state-of-the-art results across 10 IQA and 5 VQA benchmarks under both SRCC and PLCC metrics, surpassing by margins of 5.30% and textbf2.15% in IQA task, respectively. Beyond quantitative gains, it produces human-aligned reasoning traces that reveal the perceptual cues underlying quality judgments. Code and model are available.
DATR: Diffusion-based 3D Apple Tree Reconstruction Framework with Sparse-View
Aug 27, 2025Digital twin applications offered transformative potential by enabling real-time monitoring and robotic simulation through accurate virtual replicas of physical assets. The key to these systems is 3D reconstruction with high geometrical fidelity. However, existing methods struggled under field conditions, especially with sparse and occluded views. This study developed a two-stage framework (DATR) for the reconstruction of apple trees from sparse views. The first stage leverages onboard sensors and foundation models to semi-automatically generate tree masks from complex field images. Tree masks are used to filter out background information in multi-modal data for the single-image-to-3D reconstruction at the second stage. This stage consists of a diffusion model and a large reconstruction model for respective multi view and implicit neural field generation. The training of the diffusion model and LRM was achieved by using realistic synthetic apple trees generated by a Real2Sim data generator. The framework was evaluated on both field and synthetic datasets. The field dataset includes six apple trees with field-measured ground truth, while the synthetic dataset featured structurally diverse trees. Evaluation results showed that our DATR framework outperformed existing 3D reconstruction methods across both datasets and achieved domain-trait estimation comparable to industrial-grade stationary laser scanners while improving the throughput by $\sim$360 times, demonstrating strong potential for scalable agricultural digital twin systems.
CosmoFlow: Scale-Aware Representation Learning for Cosmology with Flow Matching
Jul 16, 2025Generative machine learning models have been demonstrated to be able to learn low dimensional representations of data that preserve information required for downstream tasks. In this work, we demonstrate that flow matching based generative models can learn compact, semantically rich latent representations of field level cold dark matter (CDM) simulation data without supervision. Our model, CosmoFlow, learns representations 32x smaller than the raw field data, usable for field level reconstruction, synthetic data generation, and parameter inference. Our model also learns interpretable representations, in which different latent channels correspond to features at different cosmological scales.
Efficient Long CoT Reasoning in Small Language Models
May 24, 2025Recent large reasoning models such as DeepSeek-R1 exhibit strong complex problems solving abilities by generating long chain-of-thought (CoT) reasoning steps. It is challenging to directly train small language models (SLMs) to emerge long CoT. Thus, distillation becomes a practical method to enable SLMs for such reasoning ability. However, the long CoT often contains a lot of redundant contents (e.g., overthinking steps) which may make SLMs hard to learn considering their relatively poor capacity and generalization. To address this issue, we propose a simple-yet-effective method to prune unnecessary steps in long CoT, and then employ an on-policy method for the SLM itself to curate valid and useful long CoT training data. In this way, SLMs can effectively learn efficient long CoT reasoning and preserve competitive performance at the same time. Experimental results across a series of mathematical reasoning benchmarks demonstrate the effectiveness of the proposed method in distilling long CoT reasoning ability into SLMs which maintains the competitive performance but significantly reduces generating redundant reasoning steps.