 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reasoning Traces to Reusable Modules: Understanding Compositional Generalization in Language Model Reasoning
Jun 16, 2026Post-training pipelines that combine supervised fine-tuning (SFT) with reinforcement learning (RL) have emerged as the key recipe for transforming large language models (LLMs) into robust reasoners. We argue that this combined success is driven by compositional generalization, which we formalize through a hierarchical latent selection model. In this framework, reasoning traces are generated by a cascade of discrete latent selection variables corresponding to reusable atomic modules, including both skills (local operations) and routing mechanisms (how intermediate information is selected, reused, and composed). Within this model, we theoretically show that SFT and RL play asymmetric, complementary roles: SFT supplies the raw module materials in compositional traces, and RL decomposes those traces to identify the latent atomic modules and enable compositional generalization. We design controlled experiments to validate this theory. Our results demonstrate that RL can extract atomic modules from compound traces supplied by SFT and recombine them to solve new configurations. Moreover, we find that training on compound traces yields stronger generalization than training on isolated atomic modules. Finally, we investigate the relationship between SFT and RL data and identify an effective protocol in which SFT ensures coverage of all atomic modules through compositional traces, while RL focuses on novel compositions outside the SFT support to drive exploration.
PR2: Predictive Routing Replay for MoE-Based LLM Reinforcement Learning
May 29, 2026Mixture of Experts (MoE) Large Language Models (LLMs) achieve strong performance at scale. However, reinforcement learning (RL) on MoE-based LLMs often suffers from training instability. A root cause is router drift, i.e., expert activations can change drastically across model updates and differ between disaggregated rollout and training phases, causing large rollout--training mismatch and unstable importance sampling weights in PPO-style RL algorithms. Routing replay mitigates this issue by freezing the replay route within each reasoning trajectory, but it ignores how the router evolves under off-policy updates and thus causes router staleness. To address this limitation, we propose Predictive Routing Replay (PR2), which augments each router with a lightweight evolution predictor that learns to anticipate short-horizon router evolution. During the rollout phase, we use the predictive routing distribution to apply top-$k$ routing, enabling gradients to reach experts that are likely to become active after updates. During the training phase, we replay the resulting predicted route to retain consistency for stable importance estimation. Theoretical analysis and experiments support that PR2 reduces routing-induced mismatch, improves RL stability, and yields stronger performance across various reasoning benchmarks.
Efficient Agentic Reasoning Through Self-Regulated Simulative Planning
May 21, 2026How should an agent decide when and how to plan? A dominant approach builds agents as reactive policies with adaptive computation (e.g., chain-of-thought), trained end-to-end expecting planning to emerge implicitly. Without control over the presence, structure, or horizon of planning, these systems dramatically increase reasoning length, yielding inefficient token use without reliable accuracy gains. We argue efficient agentic reasoning benefits from decomposing decision-making into three systems: simulative reasoning (System II) grounding deliberation in future-state prediction via a world model; self-regulation (System III) deciding when and how deeply to plan via a learned configurator; and reactive execution (System I) handling fine-grained action. Simulative reasoning provides unified planning across diverse tasks without per-domain engineering, while self-regulation ensures the planner is invoked only when needed. To test this, we develop SR$^2$AM (Self-Regulated Simulative Reasoning Agentic LLM), realizing both as distinct stages within an LLM's chain-of-thought, with the LLM as world model. We explore two instantiations: recording decisions from a prompted multi-module system (v0.1) and reconstructing structured plans from traces of pretrained reasoning LLMs (v1.0), trained via supervised then reinforcement learning (RL). Across math, science, tabular analysis, and web information seeking, v0.1-8B and v1.0-30B achieve Pass@1 competitive with 120-355B and 685B-1T parameter systems respectively, while v1.0-30B uses 25.8-95.3% fewer reasoning tokens than comparable agentic LLMs. RL increases average planning horizon by 22.8% while planning frequency grows only 2.0%, showing it learns to plan further ahead rather than more often. More broadly, learned self-regulation instantiates a principle we expect to extend beyond planning to how agents govern their own learning and adaptation.
EMO: Frustratingly Easy Progressive Training of Extendable MoE
May 14, 2026Sparse Mixture-of-Experts (MoE) models offer a powerful way to scale model size without increasing compute, as per-token FLOPs depend only on k active experts rather than the total pool of E experts. Yet, this asymmetry creates an MoE efficiency paradox in practice: adding more experts balloons memory and communication costs, making actual training inefficient. We argue that this bottleneck arises in part because current MoE training allocates too many experts from the beginning, even though early-stage data may not fully utilize such capacity. Motivated by this, we propose EMO, a simple progressive training framework that treats MoE capacity as expandable memory and grows the expert pool over the course of training. EMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion. Empirical results show that EMO matches the performance of a fixed-expert setup in large-scale experiments while improving wall-clock efficiency. It offers a surprisingly simple yet effective path to scalable MoE training, preserving the benefits of large expert pools while reducing both training time and GPU cost.
CocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
World Reasoning Arena
Mar 26, 2026World models (WMs) are intended to serve as internal simulators of the real world that enable agents to understand, anticipate, and act upon complex environments. Existing WM benchmarks remain narrowly focused on next-state prediction and visual fidelity, overlooking the richer simulation capabilities required for intelligent behavior. To address this gap, we introduce WR-Arena, a comprehensive benchmark for evaluating WMs along three fundamental dimensions of next world simulation: (i) Action Simulation Fidelity, the ability to interpret and follow semantically meaningful, multi-step instructions and generate diverse counterfactual rollouts; (ii) Long-horizon Forecast, the ability to sustain accurate, coherent, and physically plausible simulations across extended interactions; and (iii) Simulative Reasoning and Planning, the ability to support goal-directed reasoning by simulating, comparing, and selecting among alternative futures in both structured and open-ended environments. We build a task taxonomy and curate diverse datasets designed to probe these capabilities, moving beyond single-turn and perceptual evaluations. Through extensive experiments with state-of-the-art WMs, our results expose a substantial gap between current models and human-level hypothetical reasoning, and establish WR-Arena as both a diagnostic tool and a guideline for advancing next-generation world models capable of robust understanding, forecasting, and purposeful action. The code is available at https://github.com/MBZUAI-IFM/WR-Arena.
IsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL
Mar 12, 2026While scaling laws guide compute allocation for LLM pre-training, analogous prescriptions for reinforcement learning (RL) post-training of large language models (LLMs) remain poorly understood. We study the compute-optimal allocation of sampling compute for on-policy RL methods in LLMs, framing scaling as a compute-constrained optimization over three resources: parallel rollouts per problem, number of problems per batch, and number of update steps. We find that the compute-optimal number of parallel rollouts per problem increases predictably with compute budget and then saturates. This trend holds across both easy and hard problems, though driven by different mechanisms: solution sharpening on easy problems and coverage expansion on hard problems. We further show that increasing the number of parallel rollouts mitigates interference across problems, while the number of problems per batch primarily affects training stability and can be chosen within a broad range. Validated across base models and data distributions, our results recast RL scaling laws as prescriptive allocation rules and provide practical guidance for compute-efficient LLM RL post-training.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025



A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025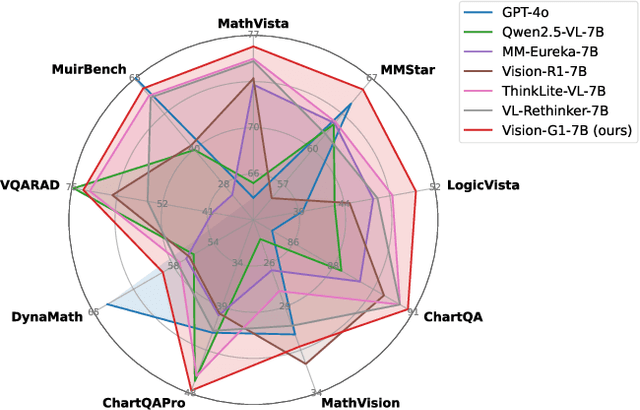

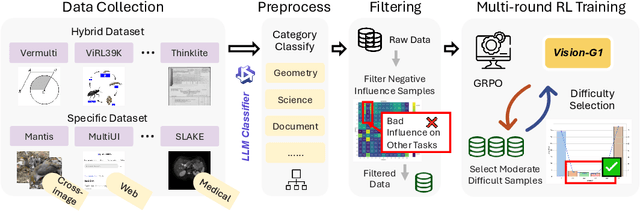

Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.