 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedMASLab: A Unified Orchestration Framework for Benchmarking Multimodal Medical Multi-Agent Systems
Mar 10, 2026While Multi-Agent Systems (MAS) show potential for complex clinical decision support, the field remains hindered by architectural fragmentation and the lack of standardized multimodal integration. Current medical MAS research suffers from non-uniform data ingestion pipelines, inconsistent visual-reasoning evaluation, and a lack of cross-specialty benchmarking. To address these challenges, we present MedMASLab, a unified framework and benchmarking platform for multimodal medical multi-agent systems. MedMASLab introduces: (1) A standardized multimodal agent communication protocol that enables seamless integration of 11 heterogeneous MAS architectures across 24 medical modalities. (2) An automated clinical reasoning evaluator, a zero-shot semantic evaluation paradigm that overcomes the limitations of lexical string-matching by leveraging large vision-language models to verify diagnostic logic and visual grounding. (3) The most extensive benchmark to date, spanning 11 organ systems and 473 diseases, standardizing data from 11 clinical benchmarks. Our systematic evaluation reveals a critical domain-specific performance gap: while MAS improves reasoning depth, current architectures exhibit significant fragility when transitioning between specialized medical sub-domains. We provide a rigorous ablation of interaction mechanisms and cost-performance trade-offs, establishing a new technical baseline for future autonomous clinical systems. The source code and data is publicly available at: https://github.com/NUS-Project/MedMASLab/
From EduVisBench to EduVisAgent: A Benchmark and Multi-Agent Framework for Pedagogical Visualization
May 22, 2025
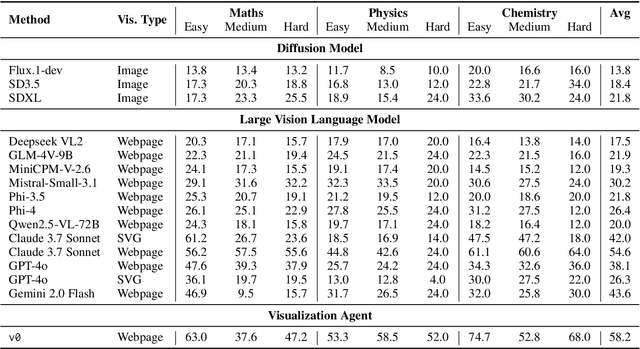
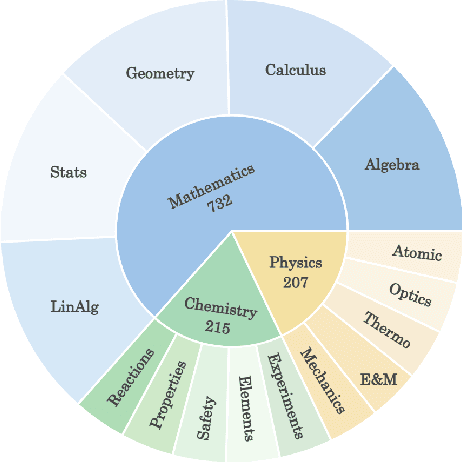
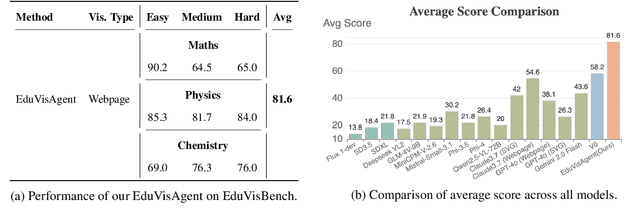
While foundation models (FMs), such as diffusion models and large vision-language models (LVLMs), have been widely applied in educational contexts, their ability to generate pedagogically effective visual explanations remains limited. Most existing approaches focus primarily on textual reasoning, overlooking the critical role of structured and interpretable visualizations in supporting conceptual understanding. To better assess the visual reasoning capabilities of FMs in educational settings, we introduce EduVisBench, a multi-domain, multi-level benchmark. EduVisBench features diverse STEM problem sets requiring visually grounded solutions, along with a fine-grained evaluation rubric informed by pedagogical theory. Our empirical analysis reveals that existing models frequently struggle with the inherent challenge of decomposing complex reasoning and translating it into visual representations aligned with human cognitive processes. To address these limitations, we propose EduVisAgent, a multi-agent collaborative framework that coordinates specialized agents for instructional planning, reasoning decomposition, metacognitive prompting, and visualization design. Experimental results show that EduVisAgent substantially outperforms all baselines, achieving a 40.2% improvement and delivering more educationally aligned visualizations. EduVisBench and EduVisAgent are available at https://github.com/aiming-lab/EduVisBench and https://github.com/aiming-lab/EduVisAgent.