 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpava: Accelerating Long-Video Understanding via Sequence-Parallelism-aware Approximate Attention
Jan 29, 2026The efficiency of long-video inference remains a critical bottleneck, mainly due to the dense computation in the prefill stage of Large Multimodal Models (LMMs). Existing methods either compress visual embeddings or apply sparse attention on a single GPU, yielding limited acceleration or degraded performance and restricting LMMs from handling longer, more complex videos. To overcome these issues, we propose Spava, a sequence-parallel framework with optimized attention that accelerates long-video inference across multiple GPUs. By distributing approximate attention, Spava reduces computation and increases parallelism, enabling efficient processing of more visual embeddings without compression and thereby improving task performance. System-level optimizations, such as load balancing and fused forward passes, further unleash the potential of Spava, delivering speedups of 12.72x, 1.70x, and 1.18x over FlashAttn, ZigZagRing, and APB, without notable performance loss. Code available at https://github.com/thunlp/APB
Wavelet-Driven Masked Multiscale Reconstruction for PPG Foundation Models
Jan 18, 2026Wearable foundation models have the potential to transform digital health by learning transferable representations from large-scale biosignals collected in everyday settings. While recent progress has been made in large-scale pretraining, most approaches overlook the spectral structure of photoplethysmography (PPG) signals, wherein physiological rhythms unfold across multiple frequency bands. Motivated by the insight that many downstream health-related tasks depend on multi-resolution features spanning fine-grained waveform morphology to global rhythmic dynamics, we introduce Masked Multiscale Reconstruction (MMR) for PPG representation learning - a self-supervised pretraining framework that explicitly learns from hierarchical time-frequency scales of PPG data. The pretraining task is designed to reconstruct randomly masked out coefficients obtained from a wavelet-based multiresolution decomposition of PPG signals, forcing the transformer encoder to integrate information across temporal and spectral scales. We pretrain our model with MMR using ~17 million unlabeled 10-second PPG segments from ~32,000 smartwatch users. On 17 of 19 diverse health-related tasks, MMR trained on large-scale wearable PPG data improves over or matches state-of-the-art open-source PPG foundation models, time-series foundation models, and other self-supervised baselines. Extensive analysis of our learned embeddings and systematic ablations underscores the value of wavelet-based representations, showing that they capture robust and physiologically-grounded features. Together, these results highlight the potential of MMR as a step toward generalizable PPG foundation models.
Enhancing Spatial Reasoning in Large Language Models for Metal-Organic Frameworks Structure Prediction
Jan 14, 2026Metal-organic frameworks (MOFs) are porous crystalline materials with broad applications such as carbon capture and drug delivery, yet accurately predicting their 3D structures remains a significant challenge. While Large Language Models (LLMs) have shown promise in generating crystals, their application to MOFs is hindered by MOFs' high atomic complexity. Inspired by the success of block-wise paradigms in deep generative models, we pioneer the use of LLMs in this domain by introducing MOF-LLM, the first LLM framework specifically adapted for block-level MOF structure prediction. To effectively harness LLMs for this modular assembly task, our training paradigm integrates spatial-aware continual pre-training (CPT), structural supervised fine-tuning (SFT), and matching-driven reinforcement learning (RL). By incorporating explicit spatial priors and optimizing structural stability via Soft Adaptive Policy Optimization (SAPO), our approach substantially enhances the spatial reasoning capability of a Qwen-3 8B model for accurate MOF structure prediction. Comprehensive experiments demonstrate that MOF-LLM outperforms state-of-the-art denoising-based and LLM-based methods while exhibiting superior sampling efficiency.
CubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations
Dec 30, 2025Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
VSA:Visual-Structural Alignment for UI-to-Code
Dec 23, 2025


The automation of user interface development has the potential to accelerate software delivery by mitigating intensive manual implementation. Despite the advancements in Large Multimodal Models for design-to-code translation, existing methodologies predominantly yield unstructured, flat codebases that lack compatibility with component-oriented libraries such as React or Angular. Such outputs typically exhibit low cohesion and high coupling, complicating long-term maintenance. In this paper, we propose \textbf{VSA (VSA)}, a multi-stage paradigm designed to synthesize organized frontend assets through visual-structural alignment. Our approach first employs a spatial-aware transformer to reconstruct the visual input into a hierarchical tree representation. Moving beyond basic layout extraction, we integrate an algorithmic pattern-matching layer to identify recurring UI motifs and encapsulate them into modular templates. These templates are then processed via a schema-driven synthesis engine, ensuring the Large Language Model generates type-safe, prop-drilled components suitable for production environments. Experimental results indicate that our framework yields a substantial improvement in code modularity and architectural consistency over state-of-the-art benchmarks, effectively bridging the gap between raw pixels and scalable software engineering.
Modular Layout Synthesis (MLS): Front-end Code via Structure Normalization and Constrained Generation
Dec 22, 2025Automated front-end engineering drastically reduces development cycles and minimizes manual coding overhead. While Generative AI has shown promise in translating designs to code, current solutions often produce monolithic scripts, failing to natively support modern ecosystems like React, Vue, or Angular. Furthermore, the generated code frequently suffers from poor modularity, making it difficult to maintain. To bridge this gap, we introduce Modular Layout Synthesis (MLS), a hierarchical framework that merges visual understanding with structural normalization. Initially, a visual-semantic encoder maps the screen capture into a serialized tree topology, capturing the essential layout hierarchy. Instead of simple parsing, we apply heuristic deduplication and pattern recognition to isolate reusable blocks, creating a framework-agnostic schema. Finally, a constraint-based generation protocol guides the LLM to synthesize production-ready code with strict typing and component props. Evaluations show that MLS significantly outperforms existing baselines, ensuring superior code reusability and structural integrity across multiple frameworks
JoVA: Unified Multimodal Learning for Joint Video-Audio Generation
Dec 15, 2025In this paper, we present JoVA, a unified framework for joint video-audio generation. Despite recent encouraging advances, existing methods face two critical limitations. First, most existing approaches can only generate ambient sounds and lack the capability to produce human speech synchronized with lip movements. Second, recent attempts at unified human video-audio generation typically rely on explicit fusion or modality-specific alignment modules, which introduce additional architecture design and weaken the model simplicity of the original transformers. To address these issues, JoVA employs joint self-attention across video and audio tokens within each transformer layer, enabling direct and efficient cross-modal interaction without the need for additional alignment modules. Furthermore, to enable high-quality lip-speech synchronization, we introduce a simple yet effective mouth-area loss based on facial keypoint detection, which enhances supervision on the critical mouth region during training without compromising architectural simplicity. Extensive experiments on benchmarks demonstrate that JoVA outperforms or is competitive with both unified and audio-driven state-of-the-art methods in lip-sync accuracy, speech quality, and overall video-audio generation fidelity. Our results establish JoVA as an elegant framework for high-quality multimodal generation.
Image Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
SRLR: Symbolic Regression based Logic Recovery to Counter Programmable Logic Controller Attacks
Dec 12, 2025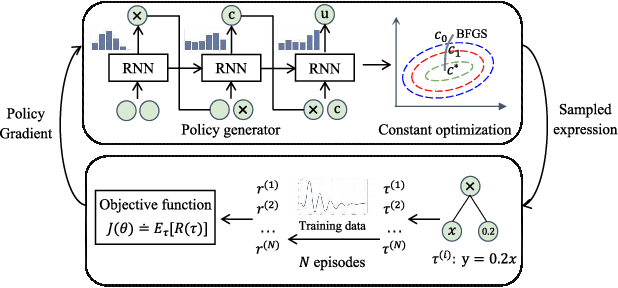
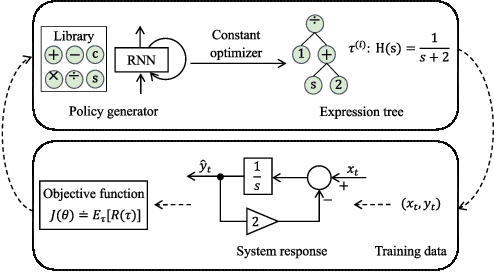
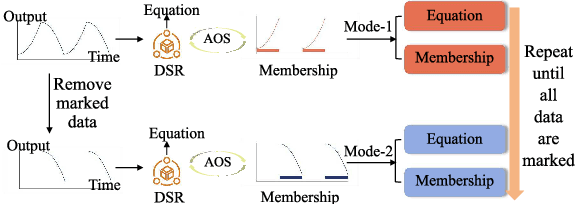
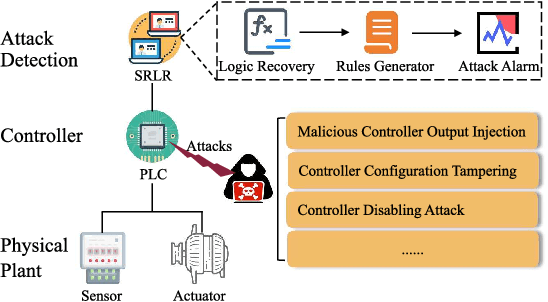
Programmable Logic Controllers (PLCs) are critical components in Industrial Control Systems (ICSs). Their potential exposure to external world makes them susceptible to cyber-attacks. Existing detection methods against controller logic attacks use either specification-based or learnt models. However, specification-based models require experts' manual efforts or access to PLC's source code, while machine learning-based models often fall short of providing explanation for their decisions. We design SRLR -- a it Symbolic Regression based Logic Recovery} solution to identify the logic of a PLC based only on its inputs and outputs. The recovered logic is used to generate explainable rules for detecting controller logic attacks. SRLR enhances the latest deep symbolic regression methods using the following ICS-specific properties: (1) some important ICS control logic is best represented in frequency domain rather than time domain; (2) an ICS controller can operate in multiple modes, each using different logic, where mode switches usually do not happen frequently; (3) a robust controller usually filters out outlier inputs as ICS sensor data can be noisy; and (4) with the above factors captured, the degree of complexity of the formulas is reduced, making effective search possible. Thanks to these enhancements, SRLR consistently outperforms all existing methods in a variety of ICS settings that we evaluate. In terms of the recovery accuracy, SRLR's gain can be as high as 39% in some challenging environment. We also evaluate SRLR on a distribution grid containing hundreds of voltage regulators, demonstrating its stability in handling large-scale, complex systems with varied configurations.
* 27 pages, 20 figures. This article was accepted by IEEE Transactions on Information Forensics and Security. DOI: 10.1109/TIFS.2025.3634027
FLEX: Continuous Agent Evolution via Forward Learning from Experience
Nov 09, 2025Autonomous agents driven by Large Language Models (LLMs) have revolutionized reasoning and problem-solving but remain static after training, unable to grow with experience as intelligent beings do during deployment. We introduce Forward Learning with EXperience (FLEX), a gradient-free learning paradigm that enables LLM agents to continuously evolve through accumulated experience. Specifically, FLEX cultivates scalable and inheritable evolution by constructing a structured experience library through continual reflection on successes and failures during interaction with the environment. FLEX delivers substantial improvements on mathematical reasoning, chemical retrosynthesis, and protein fitness prediction (up to 23% on AIME25, 10% on USPTO50k, and 14% on ProteinGym). We further identify a clear scaling law of experiential growth and the phenomenon of experience inheritance across agents, marking a step toward scalable and inheritable continuous agent evolution. Project Page: https://flex-gensi-thuair.github.io.