 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Fuse: Empowering Software Agents via Issue-free Trajectory Learning and Entropy-aware RLVR Training
Mar 09, 2026Large language models (LLMs) have transformed the software engineering landscape. Recently, numerous LLM-based agents have been developed to address real-world software issue fixing tasks. Despite their state-of-the-art performance, Despite achieving state-of-the-art performance, these agents face a significant challenge: \textbf{Insufficient high-quality issue descriptions.} Real-world datasets often exhibit misalignments between issue descriptions and their corresponding solutions, introducing noise and ambiguity that mislead automated agents and limit their problem-solving effectiveness. We propose \textbf{\textit{SWE-Fuse}}, an issue-description-aware training framework that fuses issue-description-guided and issue-free samples for training SWE agents. It consists of two key modules: (1) An issue-free-driven trajectory learning module for mitigating potentially misleading issue descriptions while enabling the model to learn step-by-step debugging processes; and (2) An entropy-aware RLVR training module, which adaptively adjusts training dynamics through entropy-driven clipping. It applies relaxed clipping under high entropy to encourage exploration, and stricter clipping under low entropy to ensure training stability. We evaluate SWE-Fuse on the widely studied SWE-bench Verified benchmark shows to demonstrate its effectiveness in solving real-world software problems. Specifically, SWE-Fuse outperforms the best 8B and 32B baselines by 43.0\% and 60.2\% in solve rate, respectively. Furthermore, integrating SWE-Fuse with test-time scaling (TTS) enables further performance improvements, achieving solve rates of 49.8\% and 65.2\% under TTS@8 for the 8B and 32B models, respectively.
SLA-Aware Distributed LLM Inference Across Device-RAN-Cloud
Feb 27, 2026Embodied AI requires sub-second inference near the Radio Access Network (RAN), but deployments span heterogeneous tiers (on-device, RAN-edge, cloud) and must not disrupt real-time baseband processing. We report measurements from a 5G Standalone (SA) AI-RAN testbed using a fixed baseline policy for repeatability. The setup includes an on-device tier, a three-node RAN-edge cluster co-hosting a containerized 5G RAN, and a cloud tier. We find that on-device execution remains multi-second and fails to meet sub-second budgets. At the RAN edge, SLA feasibility is primarily determined by model variant choice: quantized models concentrate below 0.5\,s, while unquantized and some larger quantized models incur deadline misses due to stalls and queuing. In the cloud tier, meeting a 0.5\,s deadline is challenging on the measured WAN path (up to 32.9\% of requests complete within 0.5\,s), but all evaluated variants meet a 1.0\,s deadline (100\% within 1.0\,s). Under saturated downlink traffic and up to $N{=}20$ concurrent inference clients, Multi-Instance GPU (MIG) isolation preserves baseband timing-health proxies, supporting safe co-location under fixed partitioning.
Reasoning and Tool-use Compete in Agentic RL:From Quantifying Interference to Disentangled Tuning
Feb 01, 2026Agentic Reinforcement Learning (ARL) focuses on training large language models (LLMs) to interleave reasoning with external tool execution to solve complex tasks. Most existing ARL methods train a single shared model parameters to support both reasoning and tool use behaviors, implicitly assuming that joint training leads to improved overall agent performance. Despite its widespread adoption, this assumption has rarely been examined empirically. In this paper, we systematically investigate this assumption by introducing a Linear Effect Attribution System(LEAS), which provides quantitative evidence of interference between reasoning and tool-use behaviors. Through an in-depth analysis, we show that these two capabilities often induce misaligned gradient directions, leading to training interference that undermines the effectiveness of joint optimization and challenges the prevailing ARL paradigm. To address this issue, we propose Disentangled Action Reasoning Tuning(DART), a simple and efficient framework that explicitly decouples parameter updates for reasoning and tool-use via separate low-rank adaptation modules. Experimental results show that DART consistently outperforms baseline methods with averaged 6.35 percent improvements and achieves performance comparable to multi-agent systems that explicitly separate tool-use and reasoning using a single model.
SRLR: Symbolic Regression based Logic Recovery to Counter Programmable Logic Controller Attacks
Dec 12, 2025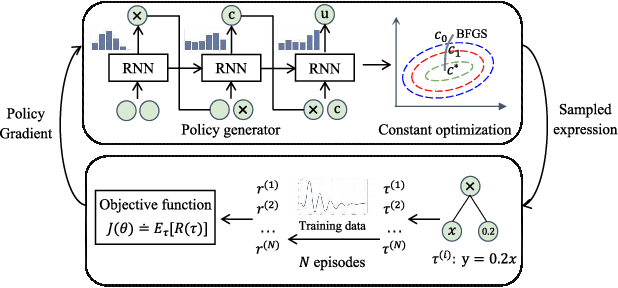
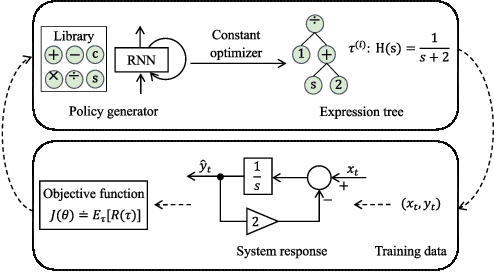
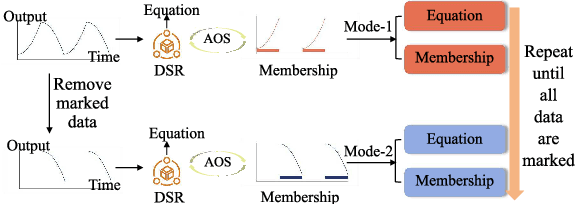
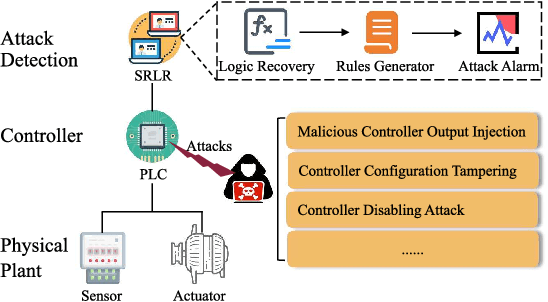
Programmable Logic Controllers (PLCs) are critical components in Industrial Control Systems (ICSs). Their potential exposure to external world makes them susceptible to cyber-attacks. Existing detection methods against controller logic attacks use either specification-based or learnt models. However, specification-based models require experts' manual efforts or access to PLC's source code, while machine learning-based models often fall short of providing explanation for their decisions. We design SRLR -- a it Symbolic Regression based Logic Recovery} solution to identify the logic of a PLC based only on its inputs and outputs. The recovered logic is used to generate explainable rules for detecting controller logic attacks. SRLR enhances the latest deep symbolic regression methods using the following ICS-specific properties: (1) some important ICS control logic is best represented in frequency domain rather than time domain; (2) an ICS controller can operate in multiple modes, each using different logic, where mode switches usually do not happen frequently; (3) a robust controller usually filters out outlier inputs as ICS sensor data can be noisy; and (4) with the above factors captured, the degree of complexity of the formulas is reduced, making effective search possible. Thanks to these enhancements, SRLR consistently outperforms all existing methods in a variety of ICS settings that we evaluate. In terms of the recovery accuracy, SRLR's gain can be as high as 39% in some challenging environment. We also evaluate SRLR on a distribution grid containing hundreds of voltage regulators, demonstrating its stability in handling large-scale, complex systems with varied configurations.
* 27 pages, 20 figures. This article was accepted by IEEE Transactions on Information Forensics and Security. DOI: 10.1109/TIFS.2025.3634027
Featureless Wireless Communications using Enhanced Autoencoder
Jul 10, 2025



Artificial intelligence (AI) techniques, particularly autoencoders (AEs), have gained significant attention in wireless communication systems. This paper investigates using an AE to generate featureless signals with a low probability of detection and interception (LPD/LPI). Firstly, we introduce a novel loss function that adds a KL divergence term to the categorical cross entropy, enhancing the noise like characteristics of AE-generated signals while preserving block error rate (BLER). Secondly, to support long source message blocks for the AE's inputs, we replace one-hot inputs of source blocks with binary inputs pre-encoded by conventional error correction coding schemes. The AE's outputs are then decoded back to the source blocks using the same scheme. This design enables the AE to learn the coding structure, yielding superior BLER performance on coded blocks and the BLER of the source blocks is further decreased by the error correction decoder. Moreover, we also validate the AE based communication system in the over-the-air communication. Experimental results demonstrate that our proposed methods improve the featureless properties of AE signals and significantly reduce the BLER of message blocks, underscoring the promise of our AE-based approach for secure and reliable wireless communication systems.
Towards VM Rescheduling Optimization Through Deep Reinforcement Learning
May 23, 2025Modern industry-scale data centers need to manage a large number of virtual machines (VMs). Due to the continual creation and release of VMs, many small resource fragments are scattered across physical machines (PMs). To handle these fragments, data centers periodically reschedule some VMs to alternative PMs, a practice commonly referred to as VM rescheduling. Despite the increasing importance of VM rescheduling as data centers grow in size, the problem remains understudied. We first show that, unlike most combinatorial optimization tasks, the inference time of VM rescheduling algorithms significantly influences their performance, due to dynamic VM state changes during this period. This causes existing methods to scale poorly. Therefore, we develop a reinforcement learning system for VM rescheduling, VM2RL, which incorporates a set of customized techniques, such as a two-stage framework that accommodates diverse constraints and workload conditions, a feature extraction module that captures relational information specific to rescheduling, as well as a risk-seeking evaluation enabling users to optimize the trade-off between latency and accuracy. We conduct extensive experiments with data from an industry-scale data center. Our results show that VM2RL can achieve a performance comparable to the optimal solution but with a running time of seconds. Code and datasets are open-sourced: https://github.com/zhykoties/VMR2L_eurosys, https://drive.google.com/drive/folders/1PfRo1cVwuhH30XhsE2Np3xqJn2GpX5qy.
Learning to Construct Implicit Communication Channel
Nov 03, 2024



Effective communication is an essential component in collaborative multi-agent systems. Situations where explicit messaging is not feasible have been common in human society throughout history, which motivate the study of implicit communication. Previous works on learning implicit communication mostly rely on theory of mind (ToM), where agents infer the mental states and intentions of others by interpreting their actions. However, ToM-based methods become less effective in making accurate inferences in complex tasks. In this work, we propose the Implicit Channel Protocol (ICP) framework, which allows agents to construct implicit communication channels similar to the explicit ones. ICP leverages a subset of actions, denoted as the scouting actions, and a mapping between information and these scouting actions that encodes and decodes the messages. We propose training algorithms for agents to message and act, including learning with a randomly initialized information map and with a delayed information map. The efficacy of ICP has been tested on the tasks of Guessing Number, Revealing Goals, and Hanabi, where ICP significantly outperforms baseline methods through more efficient information transmission.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
1st Place Solution for ECCV 2022 OOD-CV Challenge Object Detection Track
Jan 12, 2023



OOD-CV challenge is an out-of-distribution generalization task. To solve this problem in object detection track, we propose a simple yet effective Generalize-then-Adapt (G&A) framework, which is composed of a two-stage domain generalization part and a one-stage domain adaptation part. The domain generalization part is implemented by a Supervised Model Pretraining stage using source data for model warm-up and a Weakly Semi-Supervised Model Pretraining stage using both source data with box-level label and auxiliary data (ImageNet-1K) with image-level label for performance boosting. The domain adaptation part is implemented as a Source-Free Domain Adaptation paradigm, which only uses the pre-trained model and the unlabeled target data to further optimize in a self-supervised training manner. The proposed G&A framework help us achieve the first place on the object detection leaderboard of the OOD-CV challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
Improving Visual Speech Enhancement Network by Learning Audio-visual Affinity with Multi-head Attention
Jun 30, 2022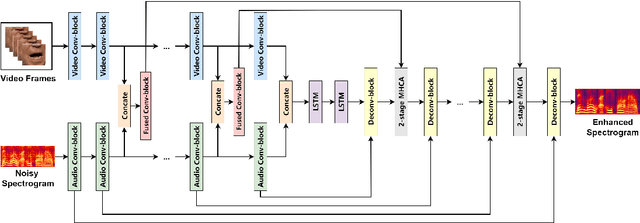
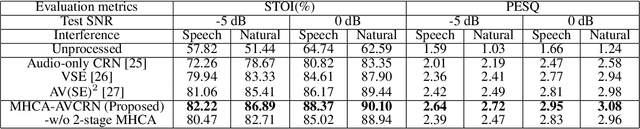
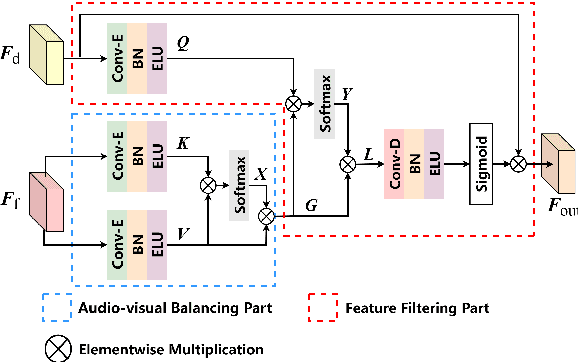

Audio-visual speech enhancement system is regarded as one of promising solutions for isolating and enhancing speech of desired speaker. Typical methods focus on predicting clean speech spectrum via a naive convolution neural network based encoder-decoder architecture, and these methods a) are not adequate to use data fully, b) are unable to effectively balance audio-visual features. The proposed model alleviates these drawbacks by a) applying a model that fuses audio and visual features layer by layer in encoding phase, and that feeds fused audio-visual features to each corresponding decoder layer, and more importantly, b) introducing a 2-stage multi-head cross attention (MHCA) mechanism to infer audio-visual speech enhancement for balancing the fused audio-visual features and eliminating irrelevant features. This paper proposes attentional audio-visual multi-layer feature fusion model, in which MHCA units are applied to feature mapping at every layer of decoder. The proposed model demonstrates the superior performance of the network against the state-of-the-art models.