 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMix-2: Establishing Protein as a Native Modality in Large Language Models
May 29, 2026We present AMix-2, a protein-text foundation model that establishes protein as a native modality in large language models (LLMs), unifying protein understanding and sequence design within a single foundation model. AMix-2 is built upon two key ideas: (1) a unified protein-text formulation that embeds natural language and protein sequence in a shared token space, enabling one model to perform biological reasoning and conditional design instead of separate downstream task-specialized models; and (2) a block-wise diffusion language modeling backbone that combines causal generation across blocks with bidirectional context and iterative refinement within blocks. This scheme better matches the intrinsic nature of proteins than a strict left-to-right factorization. To evaluate protein foundation models under realistic generalization settings, we further introduce ProteinArena, a comprehensive benchmark with time-aware and homology-aware protocols across various understanding and design tasks, and with baselines covering classical bioinformatics tools, protein-specialized models and LLMs. On ProteinArena, AMix-2 outperforms frontier LLMs and demonstrates competitive performance to task-specific protein models. Controlled experiments further show that the diffusion-based paradigm generally surpasses its autoregressive counterpart, highlighting the advantage of flexible generation order for protein sequences. We release both AMix-2 and ProteinArena to facilitate open research in protein foundation models.
Enhancing Spatial Reasoning in Large Language Models for Metal-Organic Frameworks Structure Prediction
Jan 14, 2026Metal-organic frameworks (MOFs) are porous crystalline materials with broad applications such as carbon capture and drug delivery, yet accurately predicting their 3D structures remains a significant challenge. While Large Language Models (LLMs) have shown promise in generating crystals, their application to MOFs is hindered by MOFs' high atomic complexity. Inspired by the success of block-wise paradigms in deep generative models, we pioneer the use of LLMs in this domain by introducing MOF-LLM, the first LLM framework specifically adapted for block-level MOF structure prediction. To effectively harness LLMs for this modular assembly task, our training paradigm integrates spatial-aware continual pre-training (CPT), structural supervised fine-tuning (SFT), and matching-driven reinforcement learning (RL). By incorporating explicit spatial priors and optimizing structural stability via Soft Adaptive Policy Optimization (SAPO), our approach substantially enhances the spatial reasoning capability of a Qwen-3 8B model for accurate MOF structure prediction. Comprehensive experiments demonstrate that MOF-LLM outperforms state-of-the-art denoising-based and LLM-based methods while exhibiting superior sampling efficiency.
MoMa: A Modular Deep Learning Framework for Material Property Prediction
Feb 21, 2025



Deep learning methods for material property prediction have been widely explored to advance materials discovery. However, the prevailing pre-train then fine-tune paradigm often fails to address the inherent diversity and disparity of material tasks. To overcome these challenges, we introduce MoMa, a Modular framework for Materials that first trains specialized modules across a wide range of tasks and then adaptively composes synergistic modules tailored to each downstream scenario. Evaluation across 17 datasets demonstrates the superiority of MoMa, with a substantial 14% average improvement over the strongest baseline. Few-shot and continual learning experiments further highlight MoMa's potential for real-world applications. Pioneering a new paradigm of modular material learning, MoMa will be open-sourced to foster broader community collaboration.
A Periodic Bayesian Flow for Material Generation
Feb 04, 2025



Generative modeling of crystal data distribution is an important yet challenging task due to the unique periodic physical symmetry of crystals. Diffusion-based methods have shown early promise in modeling crystal distribution. More recently, Bayesian Flow Networks were introduced to aggregate noisy latent variables, resulting in a variance-reduced parameter space that has been shown to be advantageous for modeling Euclidean data distributions with structural constraints (Song et al., 2023). Inspired by this, we seek to unlock its potential for modeling variables located in non-Euclidean manifolds e.g. those within crystal structures, by overcoming challenging theoretical issues. We introduce CrysBFN, a novel crystal generation method by proposing a periodic Bayesian flow, which essentially differs from the original Gaussian-based BFN by exhibiting non-monotonic entropy dynamics. To successfully realize the concept of periodic Bayesian flow, CrysBFN integrates a new entropy conditioning mechanism and empirically demonstrates its significance compared to time-conditioning. Extensive experiments over both crystal ab initio generation and crystal structure prediction tasks demonstrate the superiority of CrysBFN, which consistently achieves new state-of-the-art on all benchmarks. Surprisingly, we found that CrysBFN enjoys a significant improvement in sampling efficiency, e.g., ~100x speedup 10 v.s. 2000 steps network forwards) compared with previous diffusion-based methods on MP-20 dataset. Code is available at https://github.com/wu-han-lin/CrysBFN.
Cobra Effect in Reference-Free Image Captioning Metrics
Feb 18, 2024



Evaluating the compatibility between textual descriptions and corresponding images represents a core endeavor within multi-modal research. In recent years, a proliferation of reference-free methods, leveraging visual-language pre-trained models (VLMs), has emerged. Empirical evidence has substantiated that these innovative approaches exhibit a higher correlation with human judgment, marking a significant advancement in the field. However, does a higher correlation with human evaluations alone sufficiently denote the complete of a metric? In response to this question, in this paper, we study if there are any deficiencies in reference-free metrics. Specifically, inspired by the Cobra Effect, we utilize metric scores as rewards to direct the captioning model toward generating descriptions that closely align with the metric's criteria. If a certain metric has flaws, it will be exploited by the model and reflected in the generated sentences. Our findings reveal that descriptions guided by these metrics contain significant flaws, e.g. incoherent statements and excessive repetition. Subsequently, we propose a novel method termed Self-Improving to rectify the identified shortcomings within these metrics. We employ GPT-4V as an evaluative tool to assess generated sentences and the result reveals that our approach achieves state-of-the-art (SOTA) performance. In addition, we also introduce a challenging evaluation benchmark called Flaws Caption to evaluate reference-free image captioning metrics comprehensively. Our code is available at https://github.com/aaronma2020/robust_captioning_metric
M2DF: Multi-grained Multi-curriculum Denoising Framework for Multimodal Aspect-based Sentiment Analysis
Oct 23, 2023



Multimodal Aspect-based Sentiment Analysis (MABSA) is a fine-grained Sentiment Analysis task, which has attracted growing research interests recently. Existing work mainly utilizes image information to improve the performance of MABSA task. However, most of the studies overestimate the importance of images since there are many noise images unrelated to the text in the dataset, which will have a negative impact on model learning. Although some work attempts to filter low-quality noise images by setting thresholds, relying on thresholds will inevitably filter out a lot of useful image information. Therefore, in this work, we focus on whether the negative impact of noisy images can be reduced without modifying the data. To achieve this goal, we borrow the idea of Curriculum Learning and propose a Multi-grained Multi-curriculum Denoising Framework (M2DF), which can achieve denoising by adjusting the order of training data. Extensive experimental results show that our framework consistently outperforms state-of-the-art work on three sub-tasks of MABSA.
Energy-based Unknown Intent Detection with Data Manipulation
Jul 27, 2021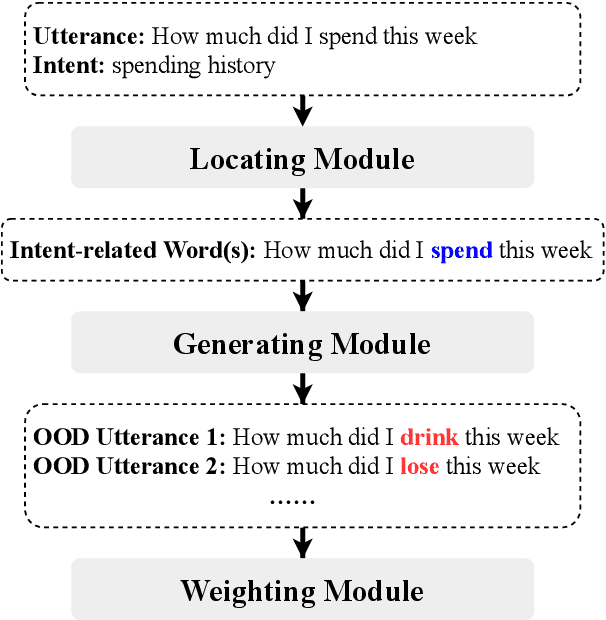
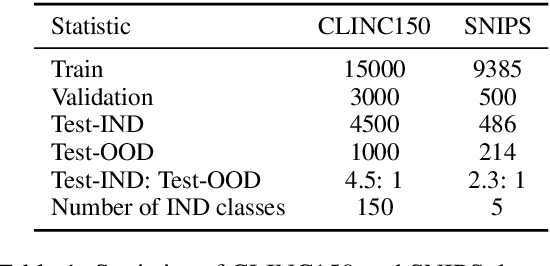
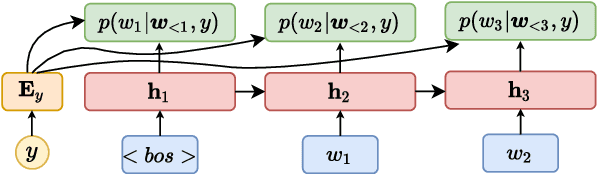
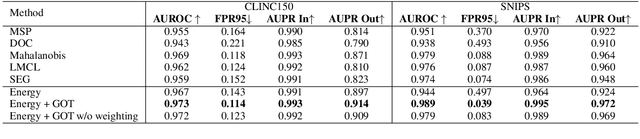
Unknown intent detection aims to identify the out-of-distribution (OOD) utterance whose intent has never appeared in the training set. In this paper, we propose using energy scores for this task as the energy score is theoretically aligned with the density of the input and can be derived from any classifier. However, high-quality OOD utterances are required during the training stage in order to shape the energy gap between OOD and in-distribution (IND), and these utterances are difficult to collect in practice. To tackle this problem, we propose a data manipulation framework to Generate high-quality OOD utterances with importance weighTs (GOT). Experimental results show that the energy-based detector fine-tuned by GOT can achieve state-of-the-art results on two benchmark datasets.