 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVE-3M: A Large-Scale High-Quality Dataset for Instruction-Guided Video Editing
Dec 16, 2025The quality and diversity of instruction-based image editing datasets are continuously increasing, yet large-scale, high-quality datasets for instruction-based video editing remain scarce. To address this gap, we introduce OpenVE-3M, an open-source, large-scale, and high-quality dataset for instruction-based video editing. It comprises two primary categories: spatially-aligned edits (Global Style, Background Change, Local Change, Local Remove, Local Add, and Subtitles Edit) and non-spatially-aligned edits (Camera Multi-Shot Edit and Creative Edit). All edit types are generated via a meticulously designed data pipeline with rigorous quality filtering. OpenVE-3M surpasses existing open-source datasets in terms of scale, diversity of edit types, instruction length, and overall quality. Furthermore, to address the lack of a unified benchmark in the field, we construct OpenVE-Bench, containing 431 video-edit pairs that cover a diverse range of editing tasks with three key metrics highly aligned with human judgment. We present OpenVE-Edit, a 5B model trained on our dataset that demonstrates remarkable efficiency and effectiveness by setting a new state-of-the-art on OpenVE-Bench, outperforming all prior open-source models including a 14B baseline. Project page is at https://lewandofskee.github.io/projects/OpenVE.
JoVA: Unified Multimodal Learning for Joint Video-Audio Generation
Dec 15, 2025In this paper, we present JoVA, a unified framework for joint video-audio generation. Despite recent encouraging advances, existing methods face two critical limitations. First, most existing approaches can only generate ambient sounds and lack the capability to produce human speech synchronized with lip movements. Second, recent attempts at unified human video-audio generation typically rely on explicit fusion or modality-specific alignment modules, which introduce additional architecture design and weaken the model simplicity of the original transformers. To address these issues, JoVA employs joint self-attention across video and audio tokens within each transformer layer, enabling direct and efficient cross-modal interaction without the need for additional alignment modules. Furthermore, to enable high-quality lip-speech synchronization, we introduce a simple yet effective mouth-area loss based on facial keypoint detection, which enhances supervision on the critical mouth region during training without compromising architectural simplicity. Extensive experiments on benchmarks demonstrate that JoVA outperforms or is competitive with both unified and audio-driven state-of-the-art methods in lip-sync accuracy, speech quality, and overall video-audio generation fidelity. Our results establish JoVA as an elegant framework for high-quality multimodal generation.
SwapText: Image Based Texts Transfer in Scenes
Mar 18, 2020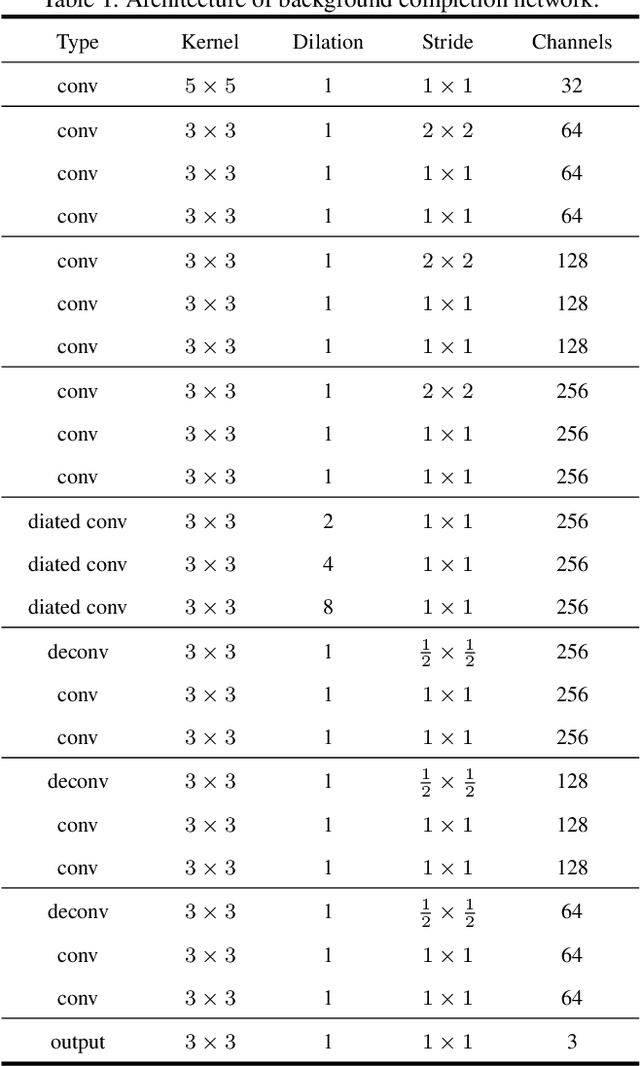
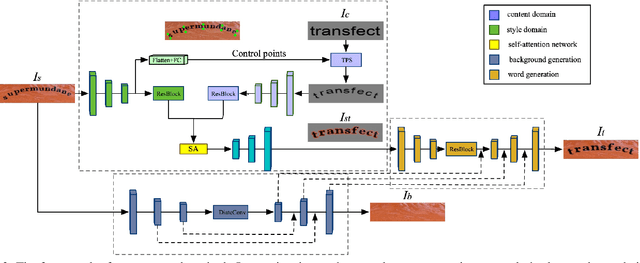
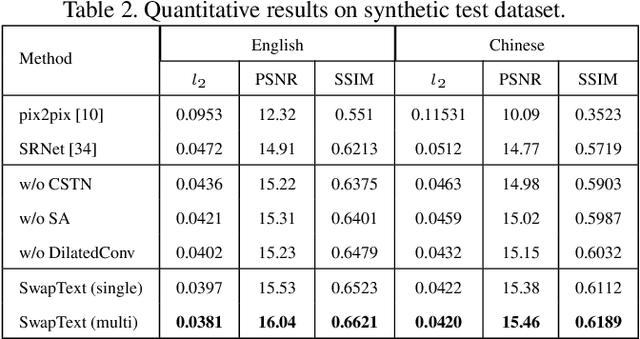
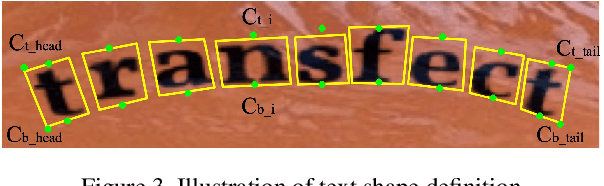
Swapping text in scene images while preserving original fonts, colors, sizes and background textures is a challenging task due to the complex interplay between different factors. In this work, we present SwapText, a three-stage framework to transfer texts across scene images. First, a novel text swapping network is proposed to replace text labels only in the foreground image. Second, a background completion network is learned to reconstruct background images. Finally, the generated foreground image and background image are used to generate the word image by the fusion network. Using the proposing framework, we can manipulate the texts of the input images even with severe geometric distortion. Qualitative and quantitative results are presented on several scene text datasets, including regular and irregular text datasets. We conducted extensive experiments to prove the usefulness of our method such as image based text translation, text image synthesis, etc.
IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection
May 08, 2018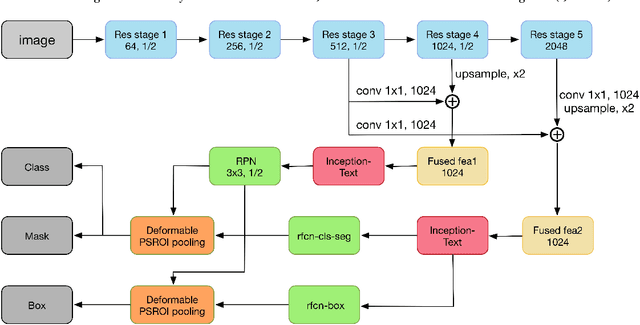
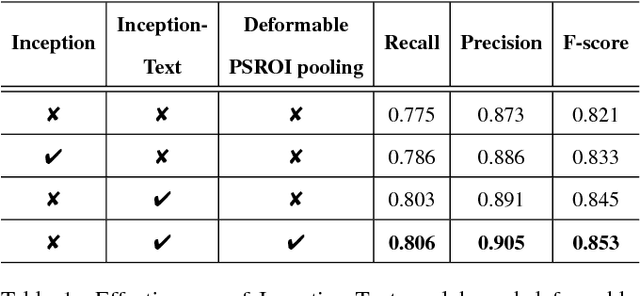
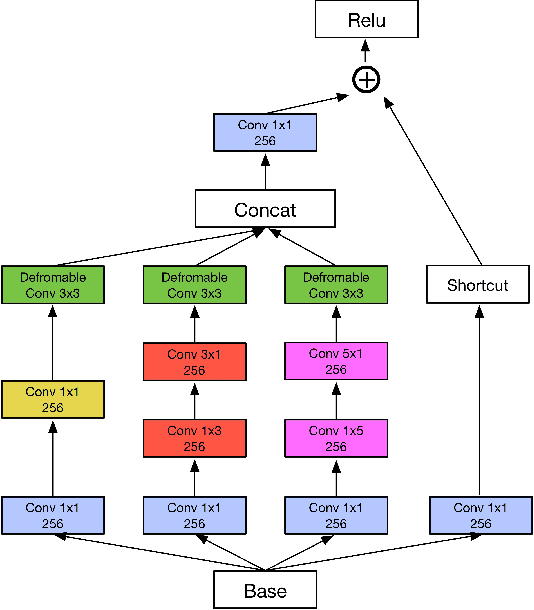
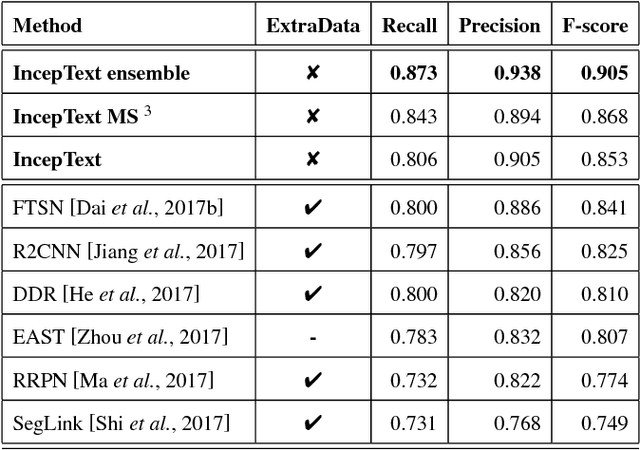
Incidental scene text detection, especially for multi-oriented text regions, is one of the most challenging tasks in many computer vision applications. Different from the common object detection task, scene text often suffers from a large variance of aspect ratio, scale, and orientation. To solve this problem, we propose a novel end-to-end scene text detector IncepText from an instance-aware segmentation perspective. We design a novel Inception-Text module and introduce deformable PSROI pooling to deal with multi-oriented text detection. Extensive experiments on ICDAR2015, RCTW-17, and MSRA-TD500 datasets demonstrate our method's superiority in terms of both effectiveness and efficiency. Our proposed method achieves 1st place result on ICDAR2015 challenge and the state-of-the-art performance on other datasets. Moreover, we have released our implementation as an OCR product which is available for public access.