 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEX: Continuous Agent Evolution via Forward Learning from Experience
Nov 09, 2025Autonomous agents driven by Large Language Models (LLMs) have revolutionized reasoning and problem-solving but remain static after training, unable to grow with experience as intelligent beings do during deployment. We introduce Forward Learning with EXperience (FLEX), a gradient-free learning paradigm that enables LLM agents to continuously evolve through accumulated experience. Specifically, FLEX cultivates scalable and inheritable evolution by constructing a structured experience library through continual reflection on successes and failures during interaction with the environment. FLEX delivers substantial improvements on mathematical reasoning, chemical retrosynthesis, and protein fitness prediction (up to 23% on AIME25, 10% on USPTO50k, and 14% on ProteinGym). We further identify a clear scaling law of experiential growth and the phenomenon of experience inheritance across agents, marking a step toward scalable and inheritable continuous agent evolution. Project Page: https://flex-gensi-thuair.github.io.
ShortListing Model: A Streamlined SimplexDiffusion for Discrete Variable Generation
Aug 24, 2025Generative modeling of discrete variables is challenging yet crucial for applications in natural language processing and biological sequence design. We introduce the Shortlisting Model (SLM), a novel simplex-based diffusion model inspired by progressive candidate pruning. SLM operates on simplex centroids, reducing generation complexity and enhancing scalability. Additionally, SLM incorporates a flexible implementation of classifier-free guidance, enhancing unconditional generation performance. Extensive experiments on DNA promoter and enhancer design, protein design, character-level and large-vocabulary language modeling demonstrate the competitive performance and strong potential of SLM. Our code can be found at https://github.com/GenSI-THUAIR/SLM
Power Stabilization for AI Training Datacenters
Aug 21, 2025Large Artificial Intelligence (AI) training workloads spanning several tens of thousands of GPUs present unique power management challenges. These arise due to the high variability in power consumption during the training. Given the synchronous nature of these jobs, during every iteration there is a computation-heavy phase, where each GPU works on the local data, and a communication-heavy phase where all the GPUs synchronize on the data. Because compute-heavy phases require much more power than communication phases, large power swings occur. The amplitude of these power swings is ever increasing with the increase in the size of training jobs. An even bigger challenge arises from the frequency spectrum of these power swings which, if harmonized with critical frequencies of utilities, can cause physical damage to the power grid infrastructure. Therefore, to continue scaling AI training workloads safely, we need to stabilize the power of such workloads. This paper introduces the challenge with production data and explores innovative solutions across the stack: software, GPU hardware, and datacenter infrastructure. We present the pros and cons of each of these approaches and finally present a multi-pronged approach to solving the challenge. The proposed solutions are rigorously tested using a combination of real hardware and Microsoft's in-house cloud power simulator, providing critical insights into the efficacy of these interventions under real-world conditions.
MMME: A Spontaneous Multi-Modal Micro-Expression Dataset Enabling Visual-Physiological Fusion
Jun 12, 2025Micro-expressions (MEs) are subtle, fleeting nonverbal cues that reveal an individual's genuine emotional state. Their analysis has attracted considerable interest due to its promising applications in fields such as healthcare, criminal investigation, and human-computer interaction. However, existing ME research is limited to single visual modality, overlooking the rich emotional information conveyed by other physiological modalities, resulting in ME recognition and spotting performance far below practical application needs. Therefore, exploring the cross-modal association mechanism between ME visual features and physiological signals (PS), and developing a multimodal fusion framework, represents a pivotal step toward advancing ME analysis. This study introduces a novel ME dataset, MMME, which, for the first time, enables synchronized collection of facial action signals (MEs), central nervous system signals (EEG), and peripheral PS (PPG, RSP, SKT, EDA, and ECG). By overcoming the constraints of existing ME corpora, MMME comprises 634 MEs, 2,841 macro-expressions (MaEs), and 2,890 trials of synchronized multimodal PS, establishing a robust foundation for investigating ME neural mechanisms and conducting multimodal fusion-based analyses. Extensive experiments validate the dataset's reliability and provide benchmarks for ME analysis, demonstrating that integrating MEs with PS significantly enhances recognition and spotting performance. To the best of our knowledge, MMME is the most comprehensive ME dataset to date in terms of modality diversity. It provides critical data support for exploring the neural mechanisms of MEs and uncovering the visual-physiological synergistic effects, driving a paradigm shift in ME research from single-modality visual analysis to multimodal fusion. The dataset will be publicly available upon acceptance of this paper.
MPFNet: A Multi-Prior Fusion Network with a Progressive Training Strategy for Micro-Expression Recognition
Jun 11, 2025Micro-expression recognition (MER), a critical subfield of affective computing, presents greater challenges than macro-expression recognition due to its brief duration and low intensity. While incorporating prior knowledge has been shown to enhance MER performance, existing methods predominantly rely on simplistic, singular sources of prior knowledge, failing to fully exploit multi-source information. This paper introduces the Multi-Prior Fusion Network (MPFNet), leveraging a progressive training strategy to optimize MER tasks. We propose two complementary encoders: the Generic Feature Encoder (GFE) and the Advanced Feature Encoder (AFE), both based on Inflated 3D ConvNets (I3D) with Coordinate Attention (CA) mechanisms, to improve the model's ability to capture spatiotemporal and channel-specific features. Inspired by developmental psychology, we present two variants of MPFNet--MPFNet-P and MPFNet-C--corresponding to two fundamental modes of infant cognitive development: parallel and hierarchical processing. These variants enable the evaluation of different strategies for integrating prior knowledge. Extensive experiments demonstrate that MPFNet significantly improves MER accuracy while maintaining balanced performance across categories, achieving accuracies of 0.811, 0.924, and 0.857 on the SMIC, CASME II, and SAMM datasets, respectively. To the best of our knowledge, our approach achieves state-of-the-art performance on the SMIC and SAMM datasets.
Fuzzy Logic Guided Reward Function Variation: An Oracle for Testing Reinforcement Learning Programs
Jun 28, 2024



Reinforcement Learning (RL) has gained significant attention across various domains. However, the increasing complexity of RL programs presents testing challenges, particularly the oracle problem: defining the correctness of the RL program. Conventional human oracles struggle to cope with the complexity, leading to inefficiencies and potential unreliability in RL testing. To alleviate this problem, we propose an automated oracle approach that leverages RL properties using fuzzy logic. Our oracle quantifies an agent's behavioral compliance with reward policies and analyzes its trend over training episodes. It labels an RL program as "Buggy" if the compliance trend violates expectations derived from RL characteristics. We evaluate our oracle on RL programs with varying complexities and compare it with human oracles. Results show that while human oracles perform well in simpler testing scenarios, our fuzzy oracle demonstrates superior performance in complex environments. The proposed approach shows promise in addressing the oracle problem for RL testing, particularly in complex cases where manual testing falls short. It offers a potential solution to improve the efficiency, reliability, and scalability of RL program testing. This research takes a step towards automated testing of RL programs and highlights the potential of fuzzy logic-based oracles in tackling the oracle problem.
A Bug or a Suggestion? An Automatic Way to Label Issues
Sep 03, 2019
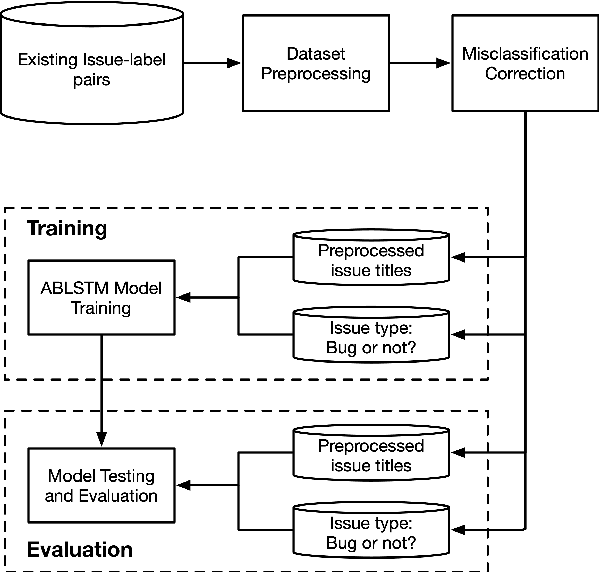
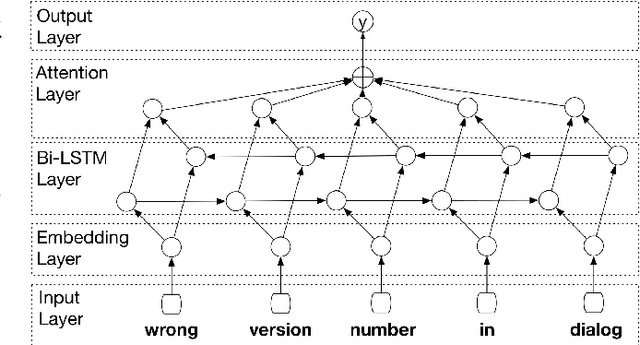
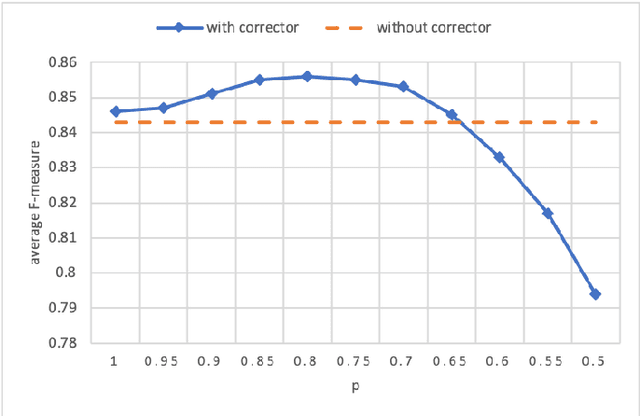
More and more users and developers are using Issue Tracking Systems (ITSs) to report issues, including bugs, feature requests, enhancement suggestions, etc. Different information, however, is gathered from users when issues are reported on different ITSs, which presents considerable challenges for issue classification tools to work effectively across the ITSs. Besides, bugs often take higher priority when it comes to classifying the issues, while existing approaches to issue classification seldom focus on distinguishing bugs and the other non-bug issues, leading to suboptimal accuracy in bug identification. In this paper, we propose a deep learning-based approach to automatically identify bug-reporting issues across various ITSs. The approach implements the k-NN algorithm to detect and correct misclassifications in data extracted from the ITSs, and trains an attention-based bi-directional long short-term memory (ABLSTM) network using a dataset of over 1.2 million labelled issues to identify bug reports. Experimental evaluation shows that our approach achieved an F-measure of 85.6\% in distinguishing bugs and other issues, significantly outperforming the other benchmark and state-of-the-art approaches examined in the experiment.