 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Neptune: The Long Orbit to Benchmarking Long Video Understanding
Dec 12, 2024



This paper describes a semi-automatic pipeline to generate challenging question-answer-decoy sets for understanding long videos. Many existing video datasets and models are focused on short clips (10s-30s). While some long video datasets do exist, they can often be solved by powerful image models applied per frame (and often to very few frames) in a video, and are usually manually annotated at high cost. In order to mitigate both these problems, we propose a scalable dataset creation pipeline which leverages large models (VLMs and LLMs), to automatically generate dense, time-aligned video captions, as well as tough question answer decoy sets for video segments (up to 15 minutes in length). Our dataset Neptune covers a broad range of long video reasoning abilities and consists of a subset that emphasizes multimodal reasoning. Since existing metrics for open-ended question answering are either rule-based or may rely on proprietary models, we provide a new open source model-based metric GEM to score open-ended responses on Neptune. Benchmark evaluations reveal that most current open-source long video models perform poorly on Neptune, particularly on questions testing temporal ordering, counting and state changes. Through Neptune, we aim to spur the development of more advanced models capable of understanding long videos. The dataset is available at https://github.com/google-deepmind/neptune
Fine-grained Controllable Video Generation via Object Appearance and Context
Dec 05, 2023



Text-to-video generation has shown promising results. However, by taking only natural languages as input, users often face difficulties in providing detailed information to precisely control the model's output. In this work, we propose fine-grained controllable video generation (FACTOR) to achieve detailed control. Specifically, FACTOR aims to control objects' appearances and context, including their location and category, in conjunction with the text prompt. To achieve detailed control, we propose a unified framework to jointly inject control signals into the existing text-to-video model. Our model consists of a joint encoder and adaptive cross-attention layers. By optimizing the encoder and the inserted layer, we adapt the model to generate videos that are aligned with both text prompts and fine-grained control. Compared to existing methods relying on dense control signals such as edge maps, we provide a more intuitive and user-friendly interface to allow object-level fine-grained control. Our method achieves controllability of object appearances without finetuning, which reduces the per-subject optimization efforts for the users. Extensive experiments on standard benchmark datasets and user-provided inputs validate that our model obtains a 70% improvement in controllability metrics over competitive baselines.
Video Summarization: Towards Entity-Aware Captions
Dec 01, 2023



Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.
Superpixel Transformers for Efficient Semantic Segmentation
Oct 02, 2023



Semantic segmentation, which aims to classify every pixel in an image, is a key task in machine perception, with many applications across robotics and autonomous driving. Due to the high dimensionality of this task, most existing approaches use local operations, such as convolutions, to generate per-pixel features. However, these methods are typically unable to effectively leverage global context information due to the high computational costs of operating on a dense image. In this work, we propose a solution to this issue by leveraging the idea of superpixels, an over-segmentation of the image, and applying them with a modern transformer framework. In particular, our model learns to decompose the pixel space into a spatially low dimensional superpixel space via a series of local cross-attentions. We then apply multi-head self-attention to the superpixels to enrich the superpixel features with global context and then directly produce a class prediction for each superpixel. Finally, we directly project the superpixel class predictions back into the pixel space using the associations between the superpixels and the image pixel features. Reasoning in the superpixel space allows our method to be substantially more computationally efficient compared to convolution-based decoder methods. Yet, our method achieves state-of-the-art performance in semantic segmentation due to the rich superpixel features generated by the global self-attention mechanism. Our experiments on Cityscapes and ADE20K demonstrate that our method matches the state of the art in terms of accuracy, while outperforming in terms of model parameters and latency.
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Oct 04, 2022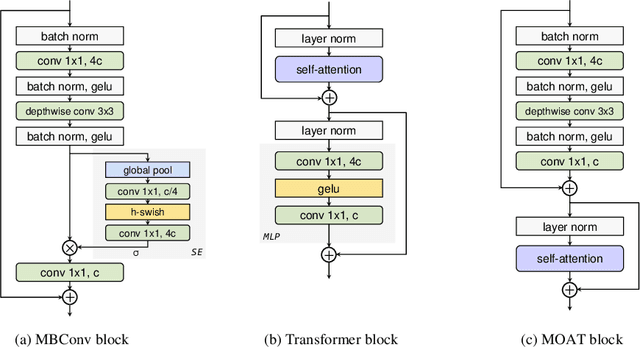

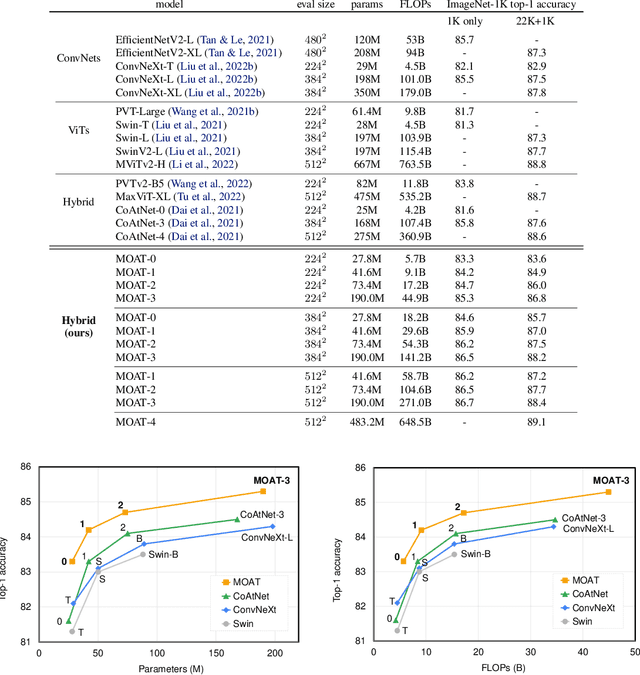
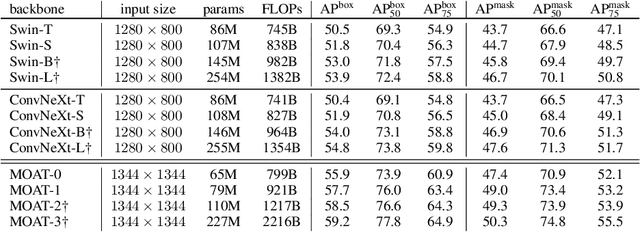
This paper presents MOAT, a family of neural networks that build on top of MObile convolution (i.e., inverted residual blocks) and ATtention. Unlike the current works that stack separate mobile convolution and transformer blocks, we effectively merge them into a MOAT block. Starting with a standard Transformer block, we replace its multi-layer perceptron with a mobile convolution block, and further reorder it before the self-attention operation. The mobile convolution block not only enhances the network representation capacity, but also produces better downsampled features. Our conceptually simple MOAT networks are surprisingly effective, achieving 89.1% top-1 accuracy on ImageNet-1K with ImageNet-22K pretraining. Additionally, MOAT can be seamlessly applied to downstream tasks that require large resolution inputs by simply converting the global attention to window attention. Thanks to the mobile convolution that effectively exchanges local information between pixels (and thus cross-windows), MOAT does not need the extra window-shifting mechanism. As a result, on COCO object detection, MOAT achieves 59.2% box AP with 227M model parameters (single-scale inference, and hard NMS), and on ADE20K semantic segmentation, MOAT attains 57.6% mIoU with 496M model parameters (single-scale inference). Finally, the tiny-MOAT family, obtained by simply reducing the channel sizes, also surprisingly outperforms several mobile-specific transformer-based models on ImageNet. We hope our simple yet effective MOAT will inspire more seamless integration of convolution and self-attention. Code is made publicly available.
k-means Mask Transformer
Jul 08, 2022
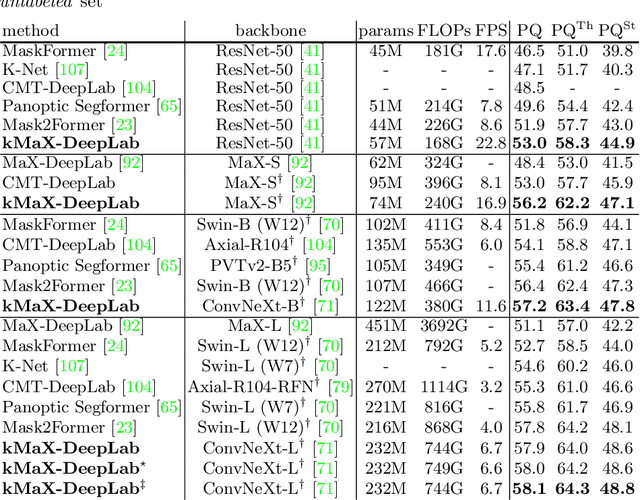
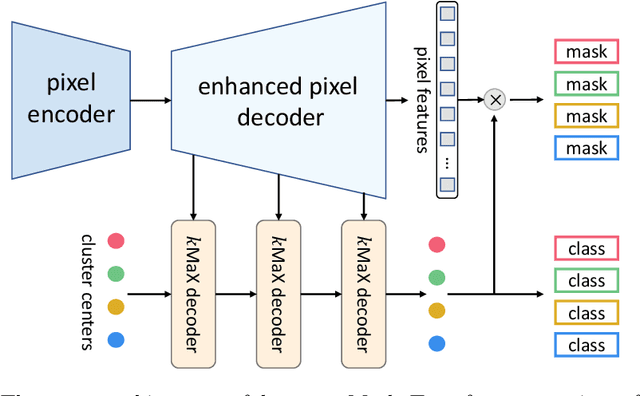
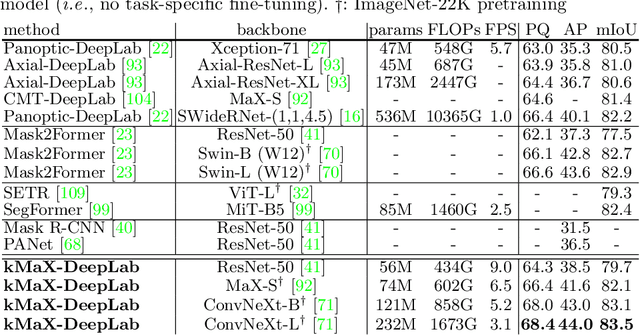
The rise of transformers in vision tasks not only advances network backbone designs, but also starts a brand-new page to achieve end-to-end image recognition (e.g., object detection and panoptic segmentation). Originated from Natural Language Processing (NLP), transformer architectures, consisting of self-attention and cross-attention, effectively learn long-range interactions between elements in a sequence. However, we observe that most existing transformer-based vision models simply borrow the idea from NLP, neglecting the crucial difference between languages and images, particularly the extremely large sequence length of spatially flattened pixel features. This subsequently impedes the learning in cross-attention between pixel features and object queries. In this paper, we rethink the relationship between pixels and object queries and propose to reformulate the cross-attention learning as a clustering process. Inspired by the traditional k-means clustering algorithm, we develop a k-means Mask Xformer (kMaX-DeepLab) for segmentation tasks, which not only improves the state-of-the-art, but also enjoys a simple and elegant design. As a result, our kMaX-DeepLab achieves a new state-of-the-art performance on COCO val set with 58.0% PQ, and Cityscapes val set with 68.4% PQ, 44.0% AP, and 83.5% mIoU without test-time augmentation or external dataset. We hope our work can shed some light on designing transformers tailored for vision tasks. Code and models are available at https://github.com/google-research/deeplab2
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
Jun 17, 2022
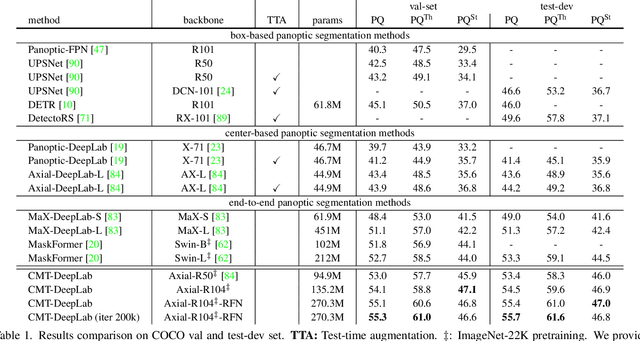
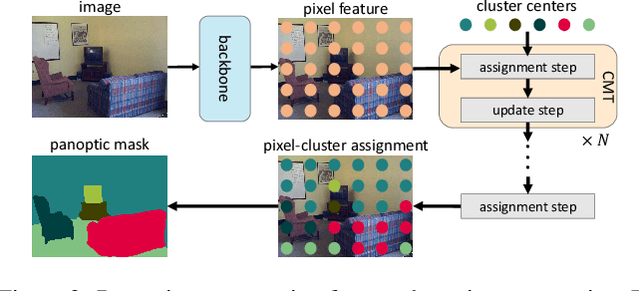

We propose Clustering Mask Transformer (CMT-DeepLab), a transformer-based framework for panoptic segmentation designed around clustering. It rethinks the existing transformer architectures used in segmentation and detection; CMT-DeepLab considers the object queries as cluster centers, which fill the role of grouping the pixels when applied to segmentation. The clustering is computed with an alternating procedure, by first assigning pixels to the clusters by their feature affinity, and then updating the cluster centers and pixel features. Together, these operations comprise the Clustering Mask Transformer (CMT) layer, which produces cross-attention that is denser and more consistent with the final segmentation task. CMT-DeepLab improves the performance over prior art significantly by 4.4% PQ, achieving a new state-of-the-art of 55.7% PQ on the COCO test-dev set.
Waymo Open Dataset: Panoramic Video Panoptic Segmentation
Jun 15, 2022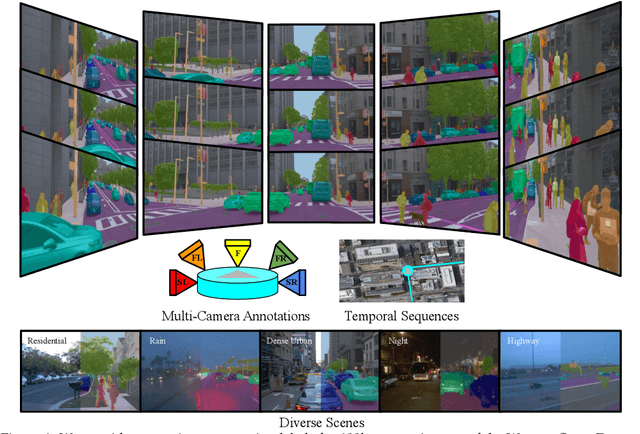

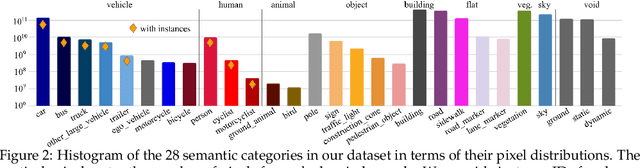
Panoptic image segmentation is the computer vision task of finding groups of pixels in an image and assigning semantic classes and object instance identifiers to them. Research in image segmentation has become increasingly popular due to its critical applications in robotics and autonomous driving. The research community thereby relies on publicly available benchmark dataset to advance the state-of-the-art in computer vision. Due to the high costs of densely labeling the images, however, there is a shortage of publicly available ground truth labels that are suitable for panoptic segmentation. The high labeling costs also make it challenging to extend existing datasets to the video domain and to multi-camera setups. We therefore present the Waymo Open Dataset: Panoramic Video Panoptic Segmentation Dataset, a large-scale dataset that offers high-quality panoptic segmentation labels for autonomous driving. We generate our dataset using the publicly available Waymo Open Dataset, leveraging the diverse set of camera images. Our labels are consistent over time for video processing and consistent across multiple cameras mounted on the vehicles for full panoramic scene understanding. Specifically, we offer labels for 28 semantic categories and 2,860 temporal sequences that were captured by five cameras mounted on autonomous vehicles driving in three different geographical locations, leading to a total of 100k labeled camera images. To the best of our knowledge, this makes our dataset an order of magnitude larger than existing datasets that offer video panoptic segmentation labels. We further propose a new benchmark for Panoramic Video Panoptic Segmentation and establish a number of strong baselines based on the DeepLab family of models. We will make the benchmark and the code publicly available. Find the dataset at https://waymo.com/open.