 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Pre-Training for Visuo-Motor Control: Revisiting a Learning-from-Scratch Baseline
Dec 12, 2022We revisit a simple Learning-from-Scratch baseline for visuo-motor control that uses data augmentation and a shallow ConvNet. We find that this baseline has competitive performance with recent methods that leverage frozen visual representations trained on large-scale vision datasets.
MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations
Dec 12, 2022



Poor sample efficiency continues to be the primary challenge for deployment of deep Reinforcement Learning (RL) algorithms for real-world applications, and in particular for visuo-motor control. Model-based RL has the potential to be highly sample efficient by concurrently learning a world model and using synthetic rollouts for planning and policy improvement. However, in practice, sample-efficient learning with model-based RL is bottlenecked by the exploration challenge. In this work, we find that leveraging just a handful of demonstrations can dramatically improve the sample-efficiency of model-based RL. Simply appending demonstrations to the interaction dataset, however, does not suffice. We identify key ingredients for leveraging demonstrations in model learning -- policy pretraining, targeted exploration, and oversampling of demonstration data -- which forms the three phases of our model-based RL framework. We empirically study three complex visuo-motor control domains and find that our method is 150%-250% more successful in completing sparse reward tasks compared to prior approaches in the low data regime (100K interaction steps, 5 demonstrations). Code and videos are available at: https://nicklashansen.github.io/modemrl
PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image-Language Models
Dec 03, 2022



Generalizable 3D part segmentation is important but challenging in vision and robotics. Training deep models via conventional supervised methods requires large-scale 3D datasets with fine-grained part annotations, which are costly to collect. This paper explores an alternative way for low-shot part segmentation of 3D point clouds by leveraging a pretrained image-language model, GLIP, which achieves superior performance on open-vocabulary 2D detection. We transfer the rich knowledge from 2D to 3D through GLIP-based part detection on point cloud rendering and a novel 2D-to-3D label lifting algorithm. We also utilize multi-view 3D priors and few-shot prompt tuning to boost performance significantly. Extensive evaluation on PartNet and PartNet-Mobility datasets shows that our method enables excellent zero-shot 3D part segmentation. Our few-shot version not only outperforms existing few-shot approaches by a large margin but also achieves highly competitive results compared to the fully supervised counterpart. Furthermore, we demonstrate that our method can be directly applied to iPhone-scanned point clouds without significant domain gaps.
DexPoint: Generalizable Point Cloud Reinforcement Learning for Sim-to-Real Dexterous Manipulation
Nov 18, 2022We propose a sim-to-real framework for dexterous manipulation which can generalize to new objects of the same category in the real world. The key of our framework is to train the manipulation policy with point cloud inputs and dexterous hands. We propose two new techniques to enable joint learning on multiple objects and sim-to-real generalization: (i) using imagined hand point clouds as augmented inputs; and (ii) designing novel contact-based rewards. We empirically evaluate our method using an Allegro Hand to grasp novel objects in both simulation and real world. To the best of our knowledge, this is the first policy learning-based framework that achieves such generalization results with dexterous hands. Our project page is available at https://yzqin.github.io/dexpoint
On the Feasibility of Cross-Task Transfer with Model-Based Reinforcement Learning
Oct 19, 2022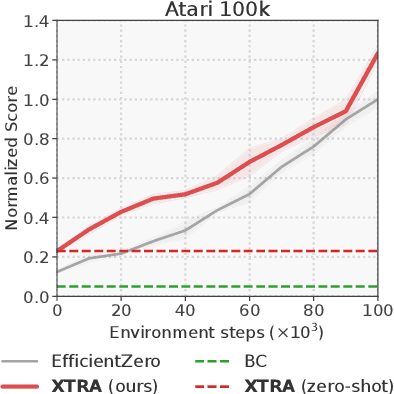
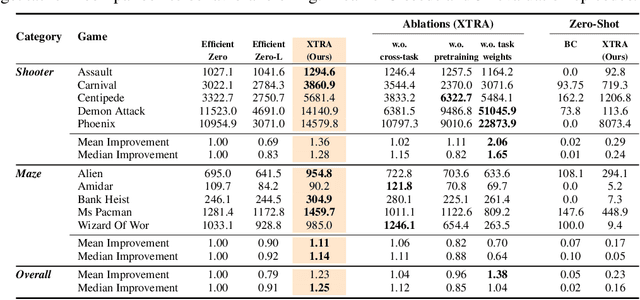
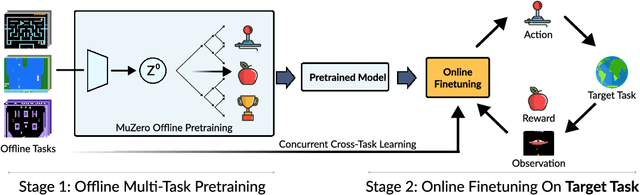
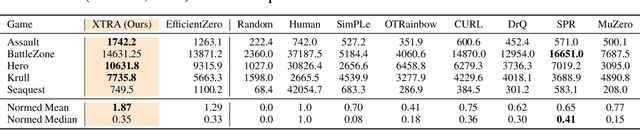
Reinforcement Learning (RL) algorithms can solve challenging control problems directly from image observations, but they often require millions of environment interactions to do so. Recently, model-based RL algorithms have greatly improved sample-efficiency by concurrently learning an internal model of the world, and supplementing real environment interactions with imagined rollouts for policy improvement. However, learning an effective model of the world from scratch is challenging, and in stark contrast to humans that rely heavily on world understanding and visual cues for learning new skills. In this work, we investigate whether internal models learned by modern model-based RL algorithms can be leveraged to solve new, distinctly different tasks faster. We propose Model-Based Cross-Task Transfer (XTRA), a framework for sample-efficient online RL with scalable pretraining and finetuning of learned world models. By offline multi-task pretraining and online cross-task finetuning, we achieve substantial improvements on the Atari100k benchmark over a baseline trained from scratch; we improve mean performance of model-based algorithm EfficientZero by 23%, and by as much as 71% in some instances. Project page: https://nicklashansen.github.io/xtra.
LESS: Label-Efficient Semantic Segmentation for LiDAR Point Clouds
Oct 14, 2022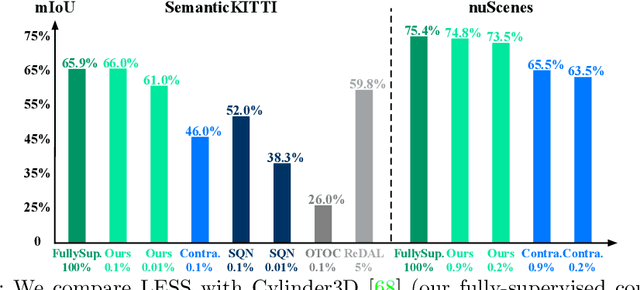
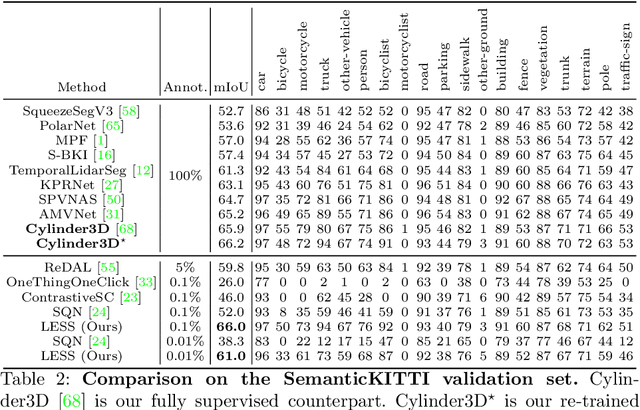
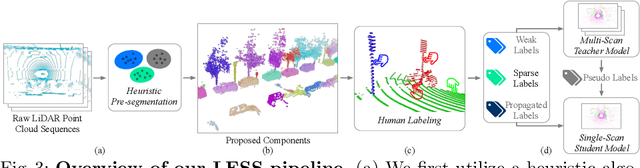
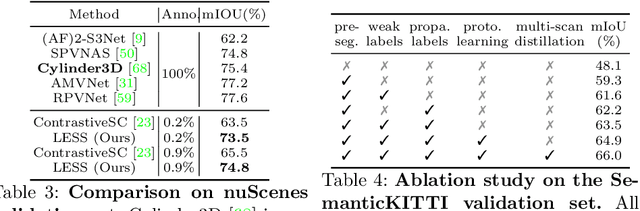
Semantic segmentation of LiDAR point clouds is an important task in autonomous driving. However, training deep models via conventional supervised methods requires large datasets which are costly to label. It is critical to have label-efficient segmentation approaches to scale up the model to new operational domains or to improve performance on rare cases. While most prior works focus on indoor scenes, we are one of the first to propose a label-efficient semantic segmentation pipeline for outdoor scenes with LiDAR point clouds. Our method co-designs an efficient labeling process with semi/weakly supervised learning and is applicable to nearly any 3D semantic segmentation backbones. Specifically, we leverage geometry patterns in outdoor scenes to have a heuristic pre-segmentation to reduce the manual labeling and jointly design the learning targets with the labeling process. In the learning step, we leverage prototype learning to get more descriptive point embeddings and use multi-scan distillation to exploit richer semantics from temporally aggregated point clouds to boost the performance of single-scan models. Evaluated on the SemanticKITTI and the nuScenes datasets, we show that our proposed method outperforms existing label-efficient methods. With extremely limited human annotations (e.g., 0.1% point labels), our proposed method is even highly competitive compared to the fully supervised counterpart with 100% labels.
Abstract-to-Executable Trajectory Translation for One-Shot Task Generalization
Oct 14, 2022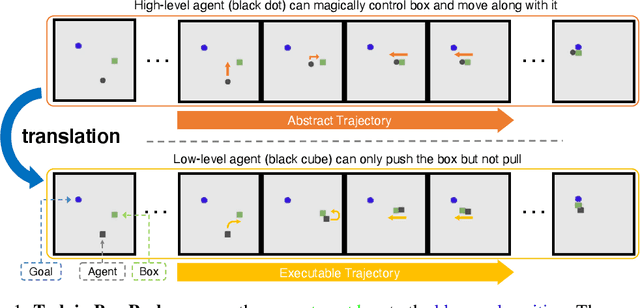
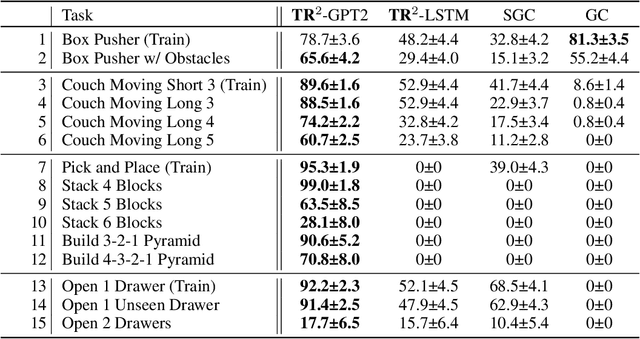
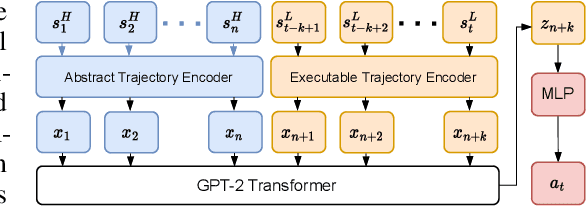
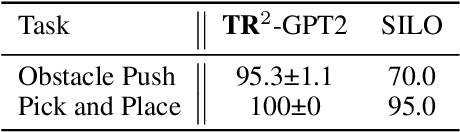
Training long-horizon robotic policies in complex physical environments is essential for many applications, such as robotic manipulation. However, learning a policy that can generalize to unseen tasks is challenging. In this work, we propose to achieve one-shot task generalization by decoupling plan generation and plan execution. Specifically, our method solves complex long-horizon tasks in three steps: build a paired abstract environment by simplifying geometry and physics, generate abstract trajectories, and solve the original task by an abstract-to-executable trajectory translator. In the abstract environment, complex dynamics such as physical manipulation are removed, making abstract trajectories easier to generate. However, this introduces a large domain gap between abstract trajectories and the actual executed trajectories as abstract trajectories lack low-level details and are not aligned frame-to-frame with the executed trajectory. In a manner reminiscent of language translation, our approach leverages a seq-to-seq model to overcome the large domain gap between the abstract and executable trajectories, enabling the low-level policy to follow the abstract trajectory. Experimental results on various unseen long-horizon tasks with different robot embodiments demonstrate the practicability of our methods to achieve one-shot task generalization.
Frame Mining: a Free Lunch for Learning Robotic Manipulation from 3D Point Clouds
Oct 14, 2022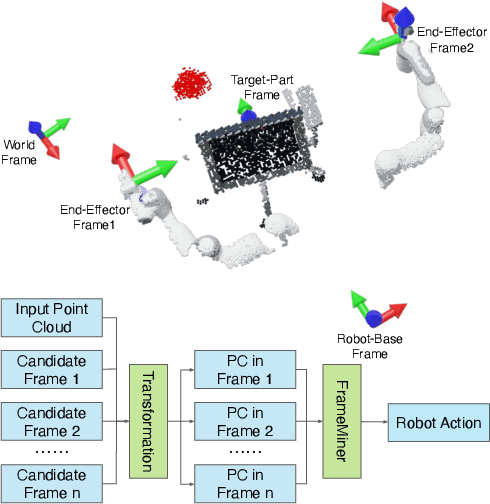
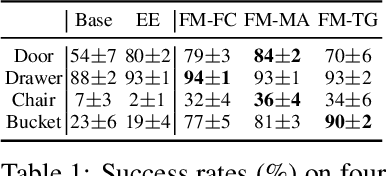
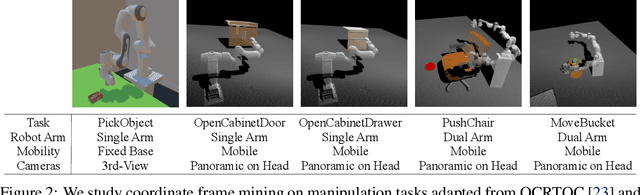
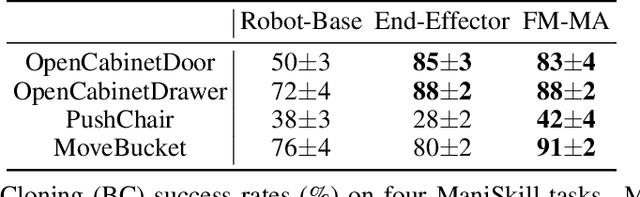
We study how choices of input point cloud coordinate frames impact learning of manipulation skills from 3D point clouds. There exist a variety of coordinate frame choices to normalize captured robot-object-interaction point clouds. We find that different frames have a profound effect on agent learning performance, and the trend is similar across 3D backbone networks. In particular, the end-effector frame and the target-part frame achieve higher training efficiency than the commonly used world frame and robot-base frame in many tasks, intuitively because they provide helpful alignments among point clouds across time steps and thus can simplify visual module learning. Moreover, the well-performing frames vary across tasks, and some tasks may benefit from multiple frame candidates. We thus propose FrameMiners to adaptively select candidate frames and fuse their merits in a task-agnostic manner. Experimentally, FrameMiners achieves on-par or significantly higher performance than the best single-frame version on five fully physical manipulation tasks adapted from ManiSkill and OCRTOC. Without changing existing camera placements or adding extra cameras, point cloud frame mining can serve as a free lunch to improve 3D manipulation learning.
A Real2Sim2Real Method for Robust Object Grasping with Neural Surface Reconstruction
Oct 06, 2022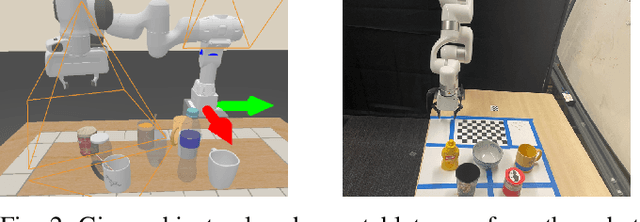
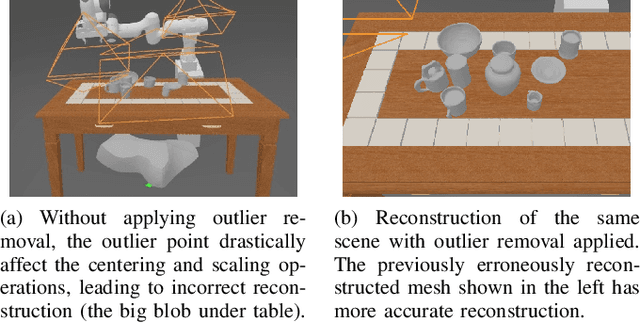


Recent 3D-based manipulation methods either directly predict the grasp pose using 3D neural networks, or solve the grasp pose using similar objects retrieved from shape databases. However, the former faces generalizability challenges when testing with new robot arms or unseen objects; and the latter assumes that similar objects exist in the databases. We hypothesize that recent 3D modeling methods provides a path towards building digital replica of the evaluation scene that affords physical simulation and supports robust manipulation algorithm learning. We propose to reconstruct high-quality meshes from real-world point clouds using state-of-the-art neural surface reconstruction method (the Real2Sim step). Because most simulators take meshes for fast simulation, the reconstructed meshes enable grasp pose labels generation without human efforts. The generated labels can train grasp network that performs robustly in the real evaluation scene (the Sim2Real step). In synthetic and real experiments, we show that the Real2Sim2Real pipeline performs better than baseline grasp networks trained with a large dataset and a grasp sampling method with retrieval-based reconstruction. The benefit of the Real2Sim2Real pipeline comes from 1) decoupling scene modeling and grasp sampling into sub-problems, and 2) both sub-problems can be solved with sufficiently high quality using recent 3D learning algorithms and mesh-based physical simulation techniques.
Multi-skill Mobile Manipulation for Object Rearrangement
Sep 06, 2022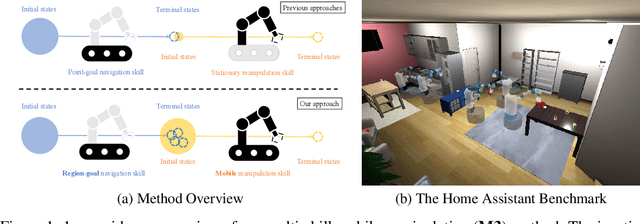



We study a modular approach to tackle long-horizon mobile manipulation tasks for object rearrangement, which decomposes a full task into a sequence of subtasks. To tackle the entire task, prior work chains multiple stationary manipulation skills with a point-goal navigation skill, which are learned individually on subtasks. Although more effective than monolithic end-to-end RL policies, this framework suffers from compounding errors in skill chaining, e.g., navigating to a bad location where a stationary manipulation skill can not reach its target to manipulate. To this end, we propose that the manipulation skills should include mobility to have flexibility in interacting with the target object from multiple locations and at the same time the navigation skill could have multiple end points which lead to successful manipulation. We operationalize these ideas by implementing mobile manipulation skills rather than stationary ones and training a navigation skill trained with region goal instead of point goal. We evaluate our multi-skill mobile manipulation method M3 on 3 challenging long-horizon mobile manipulation tasks in the Home Assistant Benchmark (HAB), and show superior performance as compared to the baselines.