 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024



Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
Sep 25, 2023



Closed-set 3D perception models trained on only a pre-defined set of object categories can be inadequate for safety critical applications such as autonomous driving where new object types can be encountered after deployment. In this paper, we present a multi-modal auto labeling pipeline capable of generating amodal 3D bounding boxes and tracklets for training models on open-set categories without 3D human labels. Our pipeline exploits motion cues inherent in point cloud sequences in combination with the freely available 2D image-text pairs to identify and track all traffic participants. Compared to the recent studies in this domain, which can only provide class-agnostic auto labels limited to moving objects, our method can handle both static and moving objects in the unsupervised manner and is able to output open-vocabulary semantic labels thanks to the proposed vision-language knowledge distillation. Experiments on the Waymo Open Dataset show that our approach outperforms the prior work by significant margins on various unsupervised 3D perception tasks.
MoDAR: Using Motion Forecasting for 3D Object Detection in Point Cloud Sequences
Jun 05, 2023



Occluded and long-range objects are ubiquitous and challenging for 3D object detection. Point cloud sequence data provide unique opportunities to improve such cases, as an occluded or distant object can be observed from different viewpoints or gets better visibility over time. However, the efficiency and effectiveness in encoding long-term sequence data can still be improved. In this work, we propose MoDAR, using motion forecasting outputs as a type of virtual modality, to augment LiDAR point clouds. The MoDAR modality propagates object information from temporal contexts to a target frame, represented as a set of virtual points, one for each object from a waypoint on a forecasted trajectory. A fused point cloud of both raw sensor points and the virtual points can then be fed to any off-the-shelf point-cloud based 3D object detector. Evaluated on the Waymo Open Dataset, our method significantly improves prior art detectors by using motion forecasting from extra-long sequences (e.g. 18 seconds), achieving new state of the arts, while not adding much computation overhead.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
Apr 04, 2023



Modeling the 3D world from sensor data for simulation is a scalable way of developing testing and validation environments for robotic learning problems such as autonomous driving. However, manually creating or re-creating real-world-like environments is difficult, expensive, and not scalable. Recent generative model techniques have shown promising progress to address such challenges by learning 3D assets using only plentiful 2D images -- but still suffer limitations as they leverage either human-curated image datasets or renderings from manually-created synthetic 3D environments. In this paper, we introduce GINA-3D, a generative model that uses real-world driving data from camera and LiDAR sensors to create realistic 3D implicit neural assets of diverse vehicles and pedestrians. Compared to the existing image datasets, the real-world driving setting poses new challenges due to occlusions, lighting-variations and long-tail distributions. GINA-3D tackles these challenges by decoupling representation learning and generative modeling into two stages with a learned tri-plane latent structure, inspired by recent advances in generative modeling of images. To evaluate our approach, we construct a large-scale object-centric dataset containing over 520K images of vehicles and pedestrians from the Waymo Open Dataset, and a new set of 80K images of long-tail instances such as construction equipment, garbage trucks, and cable cars. We compare our model with existing approaches and demonstrate that it achieves state-of-the-art performance in quality and diversity for both generated images and geometries.
NeRDi: Single-View NeRF Synthesis with Language-Guided Diffusion as General Image Priors
Dec 06, 2022



2D-to-3D reconstruction is an ill-posed problem, yet humans are good at solving this problem due to their prior knowledge of the 3D world developed over years. Driven by this observation, we propose NeRDi, a single-view NeRF synthesis framework with general image priors from 2D diffusion models. Formulating single-view reconstruction as an image-conditioned 3D generation problem, we optimize the NeRF representations by minimizing a diffusion loss on its arbitrary view renderings with a pretrained image diffusion model under the input-view constraint. We leverage off-the-shelf vision-language models and introduce a two-section language guidance as conditioning inputs to the diffusion model. This is essentially helpful for improving multiview content coherence as it narrows down the general image prior conditioned on the semantic and visual features of the single-view input image. Additionally, we introduce a geometric loss based on estimated depth maps to regularize the underlying 3D geometry of the NeRF. Experimental results on the DTU MVS dataset show that our method can synthesize novel views with higher quality even compared to existing methods trained on this dataset. We also demonstrate our generalizability in zero-shot NeRF synthesis for in-the-wild images.
Improving the Intra-class Long-tail in 3D Detection via Rare Example Mining
Oct 15, 2022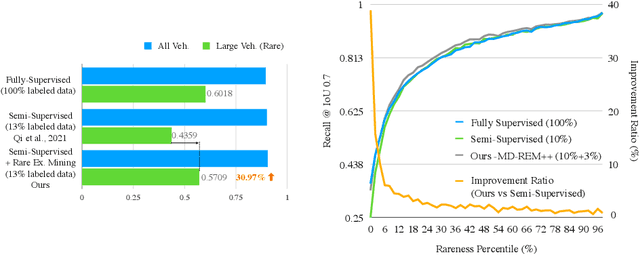
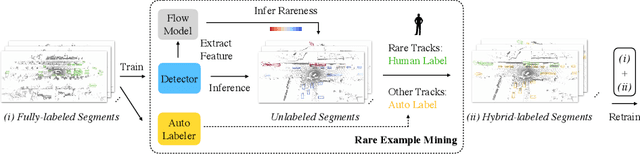
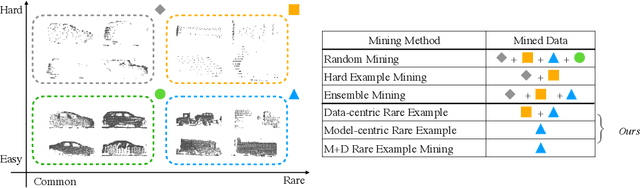
Continued improvements in deep learning architectures have steadily advanced the overall performance of 3D object detectors to levels on par with humans for certain tasks and datasets, where the overall performance is mostly driven by common examples. However, even the best performing models suffer from the most naive mistakes when it comes to rare examples that do not appear frequently in the training data, such as vehicles with irregular geometries. Most studies in the long-tail literature focus on class-imbalanced classification problems with known imbalanced label counts per class, but they are not directly applicable to the intra-class long-tail examples in problems with large intra-class variations such as 3D object detection, where instances with the same class label can have drastically varied properties such as shapes and sizes. Other works propose to mitigate this problem using active learning based on the criteria of uncertainty, difficulty, or diversity. In this study, we identify a new conceptual dimension - rareness - to mine new data for improving the long-tail performance of models. We show that rareness, as opposed to difficulty, is the key to data-centric improvements for 3D detectors, since rareness is the result of a lack in data support while difficulty is related to the fundamental ambiguity in the problem. We propose a general and effective method to identify the rareness of objects based on density estimation in the feature space using flow models, and propose a principled cost-aware formulation for mining rare object tracks, which improves overall model performance, but more importantly - significantly improves the performance for rare objects (by 30.97\%
Motion Inspired Unsupervised Perception and Prediction in Autonomous Driving
Oct 14, 2022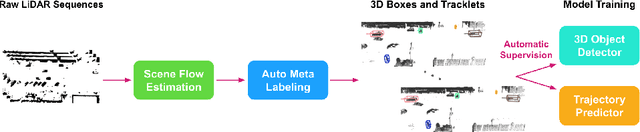
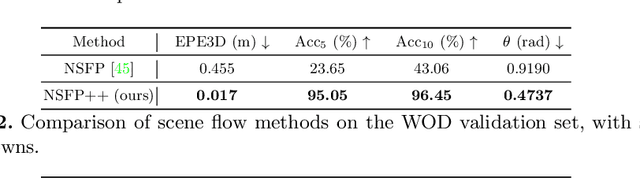

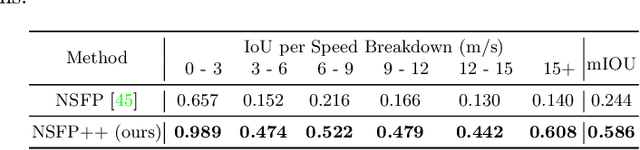
Learning-based perception and prediction modules in modern autonomous driving systems typically rely on expensive human annotation and are designed to perceive only a handful of predefined object categories. This closed-set paradigm is insufficient for the safety-critical autonomous driving task, where the autonomous vehicle needs to process arbitrarily many types of traffic participants and their motion behaviors in a highly dynamic world. To address this difficulty, this paper pioneers a novel and challenging direction, i.e., training perception and prediction models to understand open-set moving objects, with no human supervision. Our proposed framework uses self-learned flow to trigger an automated meta labeling pipeline to achieve automatic supervision. 3D detection experiments on the Waymo Open Dataset show that our method significantly outperforms classical unsupervised approaches and is even competitive to the counterpart with supervised scene flow. We further show that our approach generates highly promising results in open-set 3D detection and trajectory prediction, confirming its potential in closing the safety gap of fully supervised systems.
LESS: Label-Efficient Semantic Segmentation for LiDAR Point Clouds
Oct 14, 2022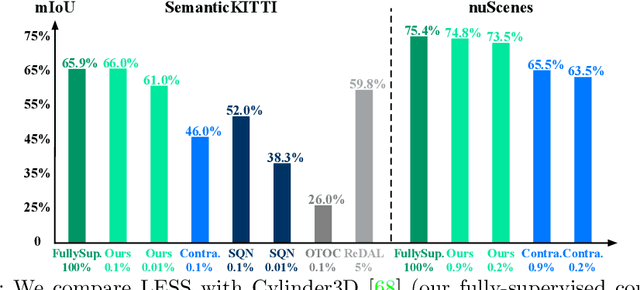
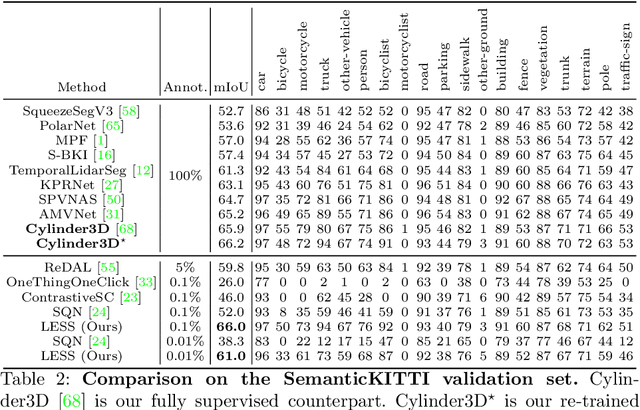
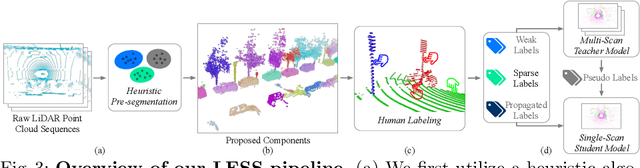
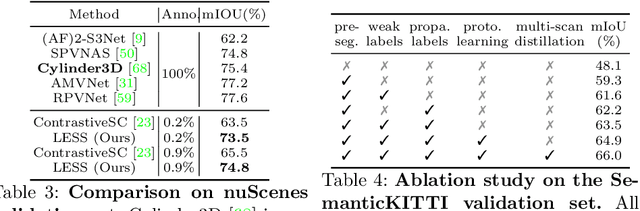
Semantic segmentation of LiDAR point clouds is an important task in autonomous driving. However, training deep models via conventional supervised methods requires large datasets which are costly to label. It is critical to have label-efficient segmentation approaches to scale up the model to new operational domains or to improve performance on rare cases. While most prior works focus on indoor scenes, we are one of the first to propose a label-efficient semantic segmentation pipeline for outdoor scenes with LiDAR point clouds. Our method co-designs an efficient labeling process with semi/weakly supervised learning and is applicable to nearly any 3D semantic segmentation backbones. Specifically, we leverage geometry patterns in outdoor scenes to have a heuristic pre-segmentation to reduce the manual labeling and jointly design the learning targets with the labeling process. In the learning step, we leverage prototype learning to get more descriptive point embeddings and use multi-scan distillation to exploit richer semantics from temporally aggregated point clouds to boost the performance of single-scan models. Evaluated on the SemanticKITTI and the nuScenes datasets, we show that our proposed method outperforms existing label-efficient methods. With extremely limited human annotations (e.g., 0.1% point labels), our proposed method is even highly competitive compared to the fully supervised counterpart with 100% labels.
LidarNAS: Unifying and Searching Neural Architectures for 3D Point Clouds
Oct 10, 2022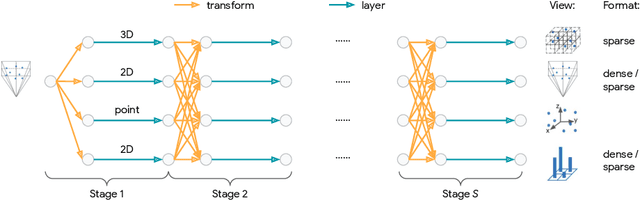
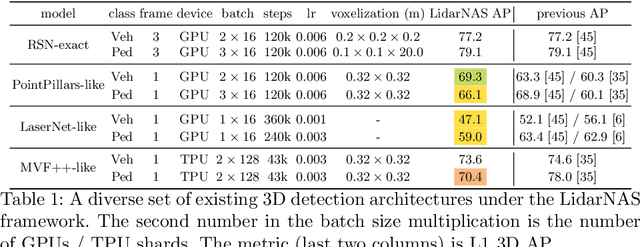

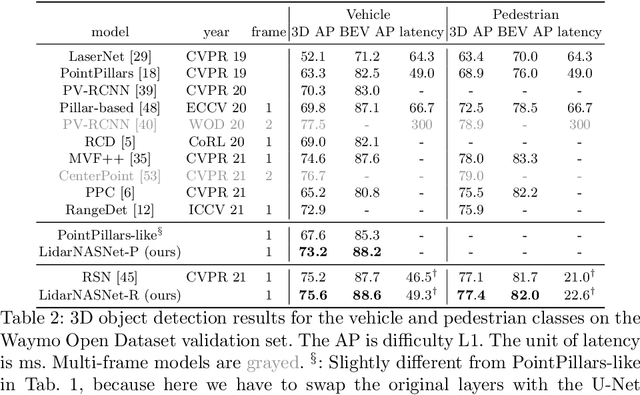
Developing neural models that accurately understand objects in 3D point clouds is essential for the success of robotics and autonomous driving. However, arguably due to the higher-dimensional nature of the data (as compared to images), existing neural architectures exhibit a large variety in their designs, including but not limited to the views considered, the format of the neural features, and the neural operations used. Lack of a unified framework and interpretation makes it hard to put these designs in perspective, as well as systematically explore new ones. In this paper, we begin by proposing a unified framework of such, with the key idea being factorizing the neural networks into a series of view transforms and neural layers. We demonstrate that this modular framework can reproduce a variety of existing works while allowing a fair comparison of backbone designs. Then, we show how this framework can easily materialize into a concrete neural architecture search (NAS) space, allowing a principled NAS-for-3D exploration. In performing evolutionary NAS on the 3D object detection task on the Waymo Open Dataset, not only do we outperform the state-of-the-art models, but also report the interesting finding that NAS tends to discover the same macro-level architecture concept for both the vehicle and pedestrian classes.