 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODG: Occupancy Prediction Using Dual Gaussians
Jun 12, 2025Occupancy prediction infers fine-grained 3D geometry and semantics from camera images of the surrounding environment, making it a critical perception task for autonomous driving. Existing methods either adopt dense grids as scene representation, which is difficult to scale to high resolution, or learn the entire scene using a single set of sparse queries, which is insufficient to handle the various object characteristics. In this paper, we present ODG, a hierarchical dual sparse Gaussian representation to effectively capture complex scene dynamics. Building upon the observation that driving scenes can be universally decomposed into static and dynamic counterparts, we define dual Gaussian queries to better model the diverse scene objects. We utilize a hierarchical Gaussian transformer to predict the occupied voxel centers and semantic classes along with the Gaussian parameters. Leveraging the real-time rendering capability of 3D Gaussian Splatting, we also impose rendering supervision with available depth and semantic map annotations injecting pixel-level alignment to boost occupancy learning. Extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks demonstrate our proposed method sets new state-of-the-art results while maintaining low inference cost.
BePo: Leveraging Birds Eye View and Sparse Points for Efficient and Accurate 3D Occupancy Prediction
Jun 08, 20253D occupancy provides fine-grained 3D geometry and semantics for scene understanding which is critical for autonomous driving. Most existing methods, however, carry high compute costs, requiring dense 3D feature volume and cross-attention to effectively aggregate information. More recent works have adopted Bird's Eye View (BEV) or sparse points as scene representation with much reduced cost, but still suffer from their respective shortcomings. More concretely, BEV struggles with small objects that often experience significant information loss after being projected to the ground plane. On the other hand, points can flexibly model little objects in 3D, but is inefficient at capturing flat surfaces or large objects. To address these challenges, in this paper, we present a novel 3D occupancy prediction approach, BePo, which combines BEV and sparse points based representations. We propose a dual-branch design: a query-based sparse points branch and a BEV branch. The 3D information learned in the sparse points branch is shared with the BEV stream via cross-attention, which enriches the weakened signals of difficult objects on the BEV plane. The outputs of both branches are finally fused to generate predicted 3D occupancy. We conduct extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks that demonstrate the superiority of our proposed BePo. Moreover, BePo also delivers competitive inference speed when compared to the latest efficient approaches.
FutureDepth: Learning to Predict the Future Improves Video Depth Estimation
Mar 19, 2024



In this paper, we propose a novel video depth estimation approach, FutureDepth, which enables the model to implicitly leverage multi-frame and motion cues to improve depth estimation by making it learn to predict the future at training. More specifically, we propose a future prediction network, F-Net, which takes the features of multiple consecutive frames and is trained to predict multi-frame features one time step ahead iteratively. In this way, F-Net learns the underlying motion and correspondence information, and we incorporate its features into the depth decoding process. Additionally, to enrich the learning of multiframe correspondence cues, we further leverage a reconstruction network, R-Net, which is trained via adaptively masked auto-encoding of multiframe feature volumes. At inference time, both F-Net and R-Net are used to produce queries to work with the depth decoder, as well as a final refinement network. Through extensive experiments on several benchmarks, i.e., NYUDv2, KITTI, DDAD, and Sintel, which cover indoor, driving, and open-domain scenarios, we show that FutureDepth significantly improves upon baseline models, outperforms existing video depth estimation methods, and sets new state-of-the-art (SOTA) accuracy. Furthermore, FutureDepth is more efficient than existing SOTA video depth estimation models and has similar latencies when comparing to monocular models
Neural Mesh Fusion: Unsupervised 3D Planar Surface Understanding
Feb 26, 2024



This paper presents Neural Mesh Fusion (NMF), an efficient approach for joint optimization of polygon mesh from multi-view image observations and unsupervised 3D planar-surface parsing of the scene. In contrast to implicit neural representations, NMF directly learns to deform surface triangle mesh and generate an embedding for unsupervised 3D planar segmentation through gradient-based optimization directly on the surface mesh. The conducted experiments show that NMF obtains competitive results compared to state-of-the-art multi-view planar reconstruction, while not requiring any ground-truth 3D or planar supervision. Moreover, NMF is significantly more computationally efficient compared to implicit neural rendering-based scene reconstruction approaches.
OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding
May 18, 2023



We introduce OpenShape, a method for learning multi-modal joint representations of text, image, and point clouds. We adopt the commonly used multi-modal contrastive learning framework for representation alignment, but with a specific focus on scaling up 3D representations to enable open-world 3D shape understanding. To achieve this, we scale up training data by ensembling multiple 3D datasets and propose several strategies to automatically filter and enrich noisy text descriptions. We also explore and compare strategies for scaling 3D backbone networks and introduce a novel hard negative mining module for more efficient training. We evaluate OpenShape on zero-shot 3D classification benchmarks and demonstrate its superior capabilities for open-world recognition. Specifically, OpenShape achieves a zero-shot accuracy of 46.8% on the 1,156-category Objaverse-LVIS benchmark, compared to less than 10% for existing methods. OpenShape also achieves an accuracy of 85.3% on ModelNet40, outperforming previous zero-shot baseline methods by 20% and performing on par with some fully-supervised methods. Furthermore, we show that our learned embeddings encode a wide range of visual and semantic concepts (e.g., subcategories, color, shape, style) and facilitate fine-grained text-3D and image-3D interactions. Due to their alignment with CLIP embeddings, our learned shape representations can also be integrated with off-the-shelf CLIP-based models for various applications, such as point cloud captioning and point cloud-conditioned image generation.
Factorized Inverse Path Tracing for Efficient and Accurate Material-Lighting Estimation
Apr 12, 2023



Inverse path tracing has recently been applied to joint material and lighting estimation, given geometry and multi-view HDR observations of an indoor scene. However, it has two major limitations: path tracing is expensive to compute, and ambiguities exist between reflection and emission. We propose a novel Factorized Inverse Path Tracing (FIPT) method which utilizes a factored light transport formulation and finds emitters driven by rendering errors. Our algorithm enables accurate material and lighting optimization faster than previous work, and is more effective at resolving ambiguities. The exhaustive experiments on synthetic scenes show that our method (1) outperforms state-of-the-art indoor inverse rendering and relighting methods particularly in the presence of complex illumination effects; (2) speeds up inverse path tracing optimization to less than an hour. We further demonstrate robustness to noisy inputs through material and lighting estimates that allow plausible relighting in a real scene. The source code is available at: https://github.com/lwwu2/fipt
PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image-Language Models
Dec 03, 2022



Generalizable 3D part segmentation is important but challenging in vision and robotics. Training deep models via conventional supervised methods requires large-scale 3D datasets with fine-grained part annotations, which are costly to collect. This paper explores an alternative way for low-shot part segmentation of 3D point clouds by leveraging a pretrained image-language model, GLIP, which achieves superior performance on open-vocabulary 2D detection. We transfer the rich knowledge from 2D to 3D through GLIP-based part detection on point cloud rendering and a novel 2D-to-3D label lifting algorithm. We also utilize multi-view 3D priors and few-shot prompt tuning to boost performance significantly. Extensive evaluation on PartNet and PartNet-Mobility datasets shows that our method enables excellent zero-shot 3D part segmentation. Our few-shot version not only outperforms existing few-shot approaches by a large margin but also achieves highly competitive results compared to the fully supervised counterpart. Furthermore, we demonstrate that our method can be directly applied to iPhone-scanned point clouds without significant domain gaps.
Transform Network Architectures for Deep Learning based End-to-End Image/Video Coding in Subsampled Color Spaces
Feb 27, 2021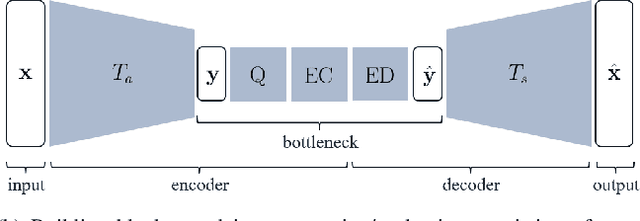
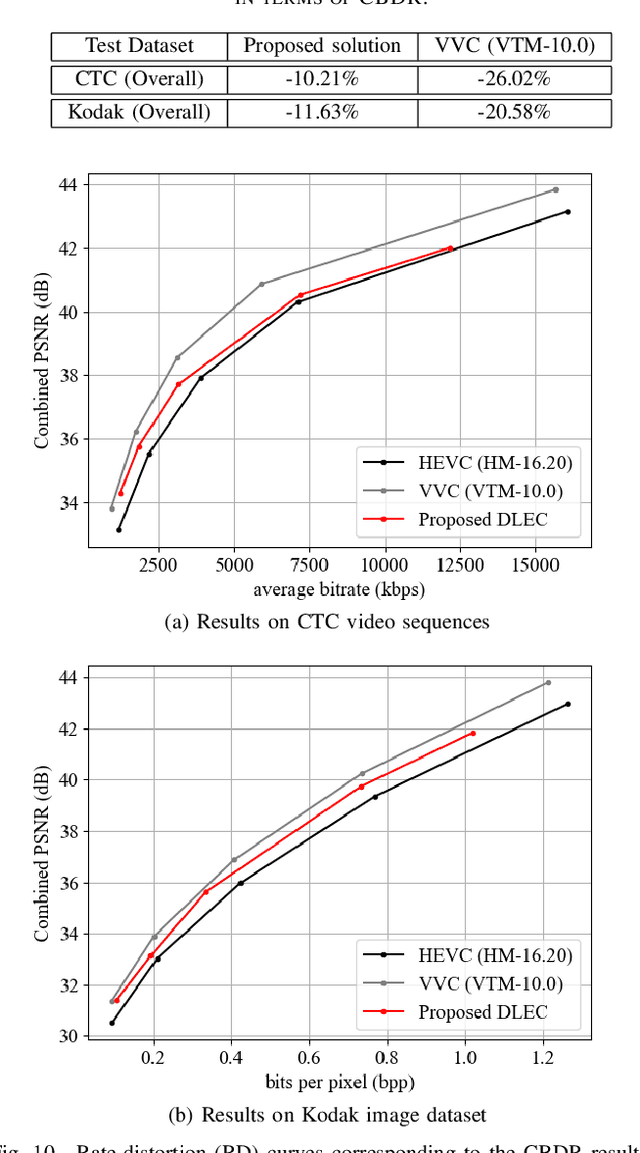
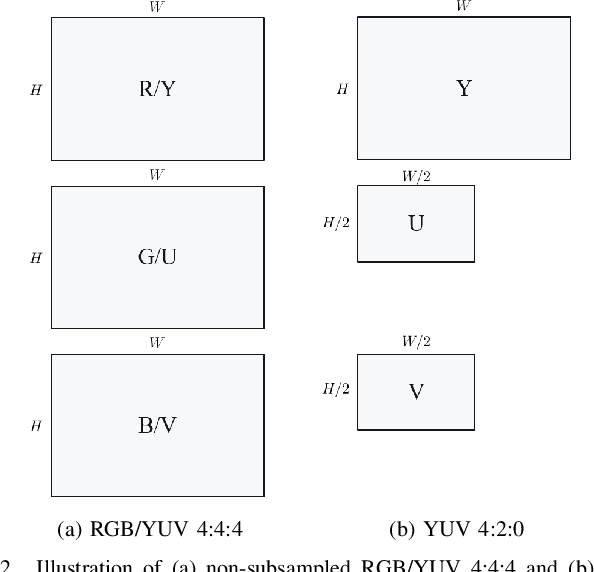

Most of the existing deep learning based end-to-end image/video coding (DLEC) architectures are designed for non-subsampled RGB color format. However, in order to achieve a superior coding performance, many state-of-the-art block-based compression standards such as High Efficiency Video Coding (HEVC/H.265) and Versatile Video Coding (VVC/H.266) are designed primarily for YUV 4:2:0 format, where U and V components are subsampled by considering the human visual system. This paper investigates various DLEC designs to support YUV 4:2:0 format by comparing their performance against the main profiles of HEVC and VVC standards under a common evaluation framework. Moreover, a new transform network architecture is proposed to improve the efficiency of coding YUV 4:2:0 data. The experimental results on YUV 4:2:0 datasets show that the proposed architecture significantly outperforms naive extensions of existing architectures designed for RGB format and achieves about 10% average BD-rate improvement over the intra-frame coding in HEVC.
Progressive Neural Image Compression with Nested Quantization and Latent Ordering
Feb 04, 2021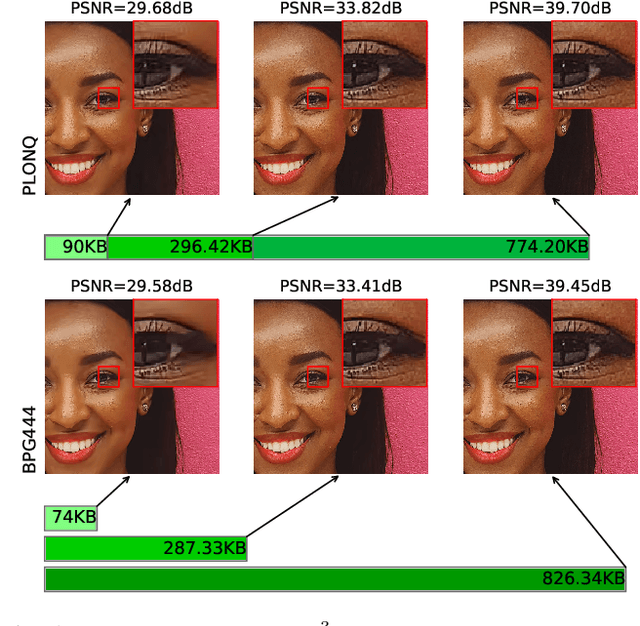

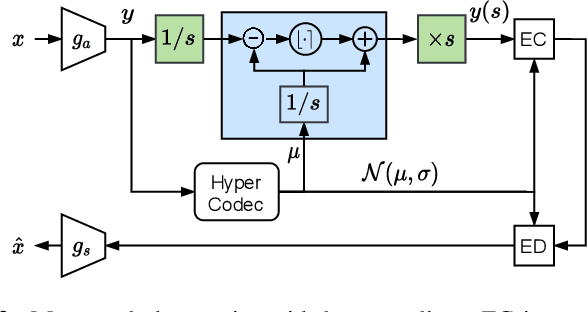
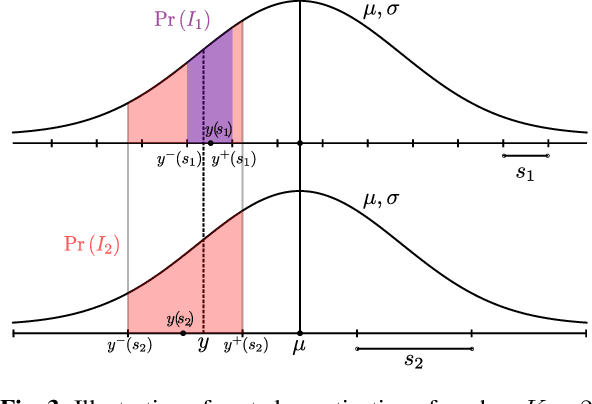
We present PLONQ, a progressive neural image compression scheme which pushes the boundary of variable bitrate compression by allowing quality scalable coding with a single bitstream. In contrast to existing learned variable bitrate solutions which produce separate bitstreams for each quality, it enables easier rate-control and requires less storage. Leveraging the latent scaling based variable bitrate solution, we introduce nested quantization, a method that defines multiple quantization levels with nested quantization grids, and progressively refines all latents from the coarsest to the finest quantization level. To achieve finer progressiveness in between any two quantization levels, latent elements are incrementally refined with an importance ordering defined in the rate-distortion sense. To the best of our knowledge, PLONQ is the first learning-based progressive image coding scheme and it outperforms SPIHT, a well-known wavelet-based progressive image codec.
Physics-Constrained Deep Learning for High-dimensional Surrogate Modeling and Uncertainty Quantification without Labeled Data
Jan 18, 2019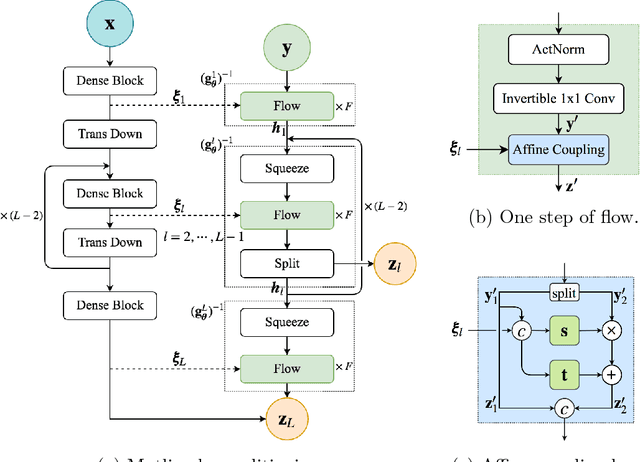
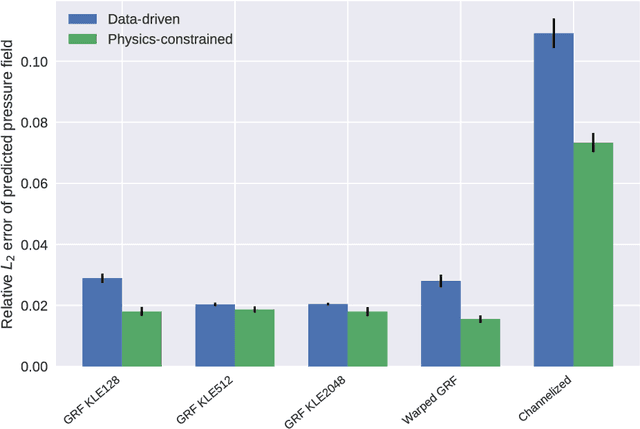
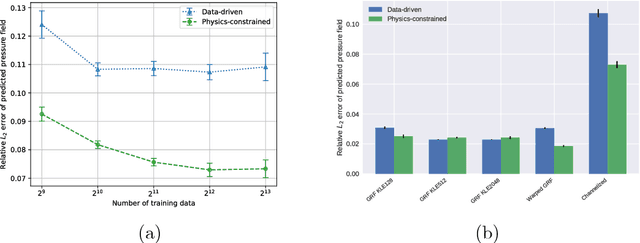
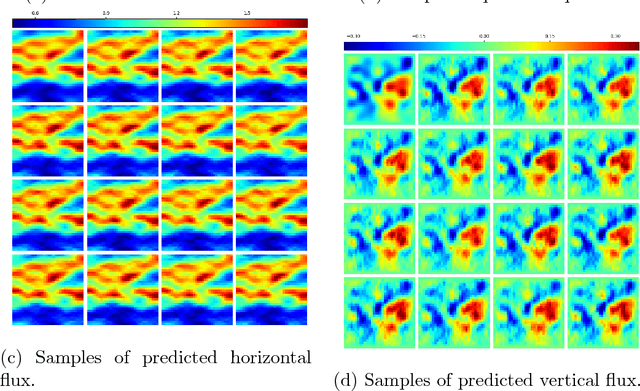
Surrogate modeling and uncertainty quantification tasks for PDE systems are most often considered as supervised learning problems where input and output data pairs are used for training. The construction of such emulators is by definition a small data problem which poses challenges to deep learning approaches that have been developed to operate in the big data regime. Even in cases where such models have been shown to have good predictive capability in high dimensions, they fail to address constraints in the data implied by the PDE model. This paper provides a methodology that incorporates the governing equations of the physical model in the loss/likelihood functions. The resulting physics-constrained, deep learning models are trained without any labeled data (e.g. employing only input data) and provide comparable predictive responses with data-driven models while obeying the constraints of the problem at hand. This work employs a convolutional encoder-decoder neural network approach as well as a conditional flow-based generative model for the solution of PDEs, surrogate model construction, and uncertainty quantification tasks. The methodology is posed as a minimization problem of the reverse Kullback-Leibler (KL) divergence between the model predictive density and the reference conditional density, where the later is defined as the Boltzmann-Gibbs distribution at a given inverse temperature with the underlying potential relating to the PDE system of interest. The generalization capability of these models to out-of-distribution input is considered. Quantification and interpretation of the predictive uncertainty is provided for a number of problems.