 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
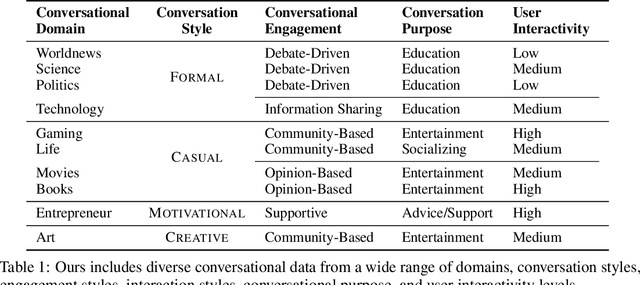


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
Document Attribution: Examining Citation Relationships using Large Language Models
May 09, 2025As Large Language Models (LLMs) are increasingly applied to document-based tasks - such as document summarization, question answering, and information extraction - where user requirements focus on retrieving information from provided documents rather than relying on the model's parametric knowledge, ensuring the trustworthiness and interpretability of these systems has become a critical concern. A central approach to addressing this challenge is attribution, which involves tracing the generated outputs back to their source documents. However, since LLMs can produce inaccurate or imprecise responses, it is crucial to assess the reliability of these citations. To tackle this, our work proposes two techniques. (1) A zero-shot approach that frames attribution as a straightforward textual entailment task. Our method using flan-ul2 demonstrates an improvement of 0.27% and 2.4% over the best baseline of ID and OOD sets of AttributionBench, respectively. (2) We also explore the role of the attention mechanism in enhancing the attribution process. Using a smaller LLM, flan-t5-small, the F1 scores outperform the baseline across almost all layers except layer 4 and layers 8 through 11.
Skill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.
CORG: Generating Answers from Complex, Interrelated Contexts
Apr 25, 2025In a real-world corpus, knowledge frequently recurs across documents but often contains inconsistencies due to ambiguous naming, outdated information, or errors, leading to complex interrelationships between contexts. Previous research has shown that language models struggle with these complexities, typically focusing on single factors in isolation. We classify these relationships into four types: distracting, ambiguous, counterfactual, and duplicated. Our analysis reveals that no single approach effectively addresses all these interrelationships simultaneously. Therefore, we introduce Context Organizer (CORG), a framework that organizes multiple contexts into independently processed groups. This design allows the model to efficiently find all relevant answers while ensuring disambiguation. CORG consists of three key components: a graph constructor, a reranker, and an aggregator. Our results demonstrate that CORG balances performance and efficiency effectively, outperforming existing grouping methods and achieving comparable results to more computationally intensive, single-context approaches.
Towards Visual Text Grounding of Multimodal Large Language Model
Apr 07, 2025

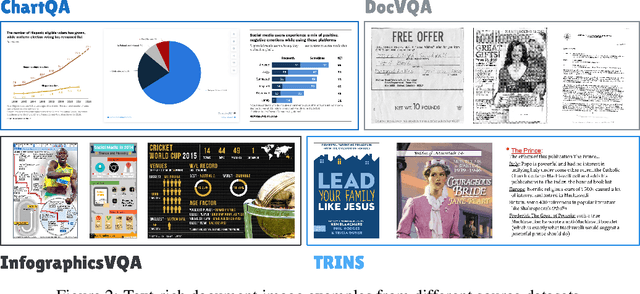

Despite the existing evolution of Multimodal Large Language Models (MLLMs), a non-neglectable limitation remains in their struggle with visual text grounding, especially in text-rich images of documents. Document images, such as scanned forms and infographics, highlight critical challenges due to their complex layouts and textual content. However, current benchmarks do not fully address these challenges, as they mostly focus on visual grounding on natural images, rather than text-rich document images. Thus, to bridge this gap, we introduce TRIG, a novel task with a newly designed instruction dataset for benchmarking and improving the Text-Rich Image Grounding capabilities of MLLMs in document question-answering. Specifically, we propose an OCR-LLM-human interaction pipeline to create 800 manually annotated question-answer pairs as a benchmark and a large-scale training set of 90$ synthetic data based on four diverse datasets. A comprehensive evaluation of various MLLMs on our proposed benchmark exposes substantial limitations in their grounding capability on text-rich images. In addition, we propose two simple and effective TRIG methods based on general instruction tuning and plug-and-play efficient embedding, respectively. By finetuning MLLMs on our synthetic dataset, they promisingly improve spatial reasoning and grounding capabilities.
Efficient Model Selection for Time Series Forecasting via LLMs
Apr 02, 2025



Model selection is a critical step in time series forecasting, traditionally requiring extensive performance evaluations across various datasets. Meta-learning approaches aim to automate this process, but they typically depend on pre-constructed performance matrices, which are costly to build. In this work, we propose to leverage Large Language Models (LLMs) as a lightweight alternative for model selection. Our method eliminates the need for explicit performance matrices by utilizing the inherent knowledge and reasoning capabilities of LLMs. Through extensive experiments with LLaMA, GPT and Gemini, we demonstrate that our approach outperforms traditional meta-learning techniques and heuristic baselines, while significantly reducing computational overhead. These findings underscore the potential of LLMs in efficient model selection for time series forecasting.
Mixture of Structural-and-Textual Retrieval over Text-rich Graph Knowledge Bases
Feb 27, 2025Text-rich Graph Knowledge Bases (TG-KBs) have become increasingly crucial for answering queries by providing textual and structural knowledge. However, current retrieval methods often retrieve these two types of knowledge in isolation without considering their mutual reinforcement and some hybrid methods even bypass structural retrieval entirely after neighboring aggregation. To fill in this gap, we propose a Mixture of Structural-and-Textual Retrieval (MoR) to retrieve these two types of knowledge via a Planning-Reasoning-Organizing framework. In the Planning stage, MoR generates textual planning graphs delineating the logic for answering queries. Following planning graphs, in the Reasoning stage, MoR interweaves structural traversal and textual matching to obtain candidates from TG-KBs. In the Organizing stage, MoR further reranks fetched candidates based on their structural trajectory. Extensive experiments demonstrate the superiority of MoR in harmonizing structural and textual retrieval with insights, including uneven retrieving performance across different query logics and the benefits of integrating structural trajectories for candidate reranking. Our code is available at https://github.com/Yoega/MoR.
Exploring Rewriting Approaches for Different Conversational Tasks
Feb 26, 2025



Conversational assistants often require a question rewriting algorithm that leverages a subset of past interactions to provide a more meaningful (accurate) answer to the user's question or request. However, the exact rewriting approach may often depend on the use case and application-specific tasks supported by the conversational assistant, among other constraints. In this paper, we systematically investigate two different approaches, denoted as rewriting and fusion, on two fundamentally different generation tasks, including a text-to-text generation task and a multimodal generative task that takes as input text and generates a visualization or data table that answers the user's question. Our results indicate that the specific rewriting or fusion approach highly depends on the underlying use case and generative task. In particular, we find that for a conversational question-answering assistant, the query rewriting approach performs best, whereas for a data analysis assistant that generates visualizations and data tables based on the user's conversation with the assistant, the fusion approach works best. Notably, we explore two datasets for the data analysis assistant use case, for short and long conversations, and we find that query fusion always performs better, whereas for the conversational text-based question-answering, the query rewrite approach performs best.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025



Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.