 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
Sparse Personalized Text Generation with Multi-Trajectory Reasoning
Apr 27, 2026As Large Language Models (LLMs) advance, personalization has become a key mechanism for tailoring outputs to individual user needs. However, most existing methods rely heavily on dense interaction histories, making them ineffective in cold-start scenarios where such data is sparse or unavailable. While external signals (e.g., content of similar users) can offer a potential remedy, leveraging them effectively remains challenging: raw context is often noisy, and existing methods struggle to reason over heterogeneous data sources. To address these issues, we introduce PAT (Personalization with Aligned Trajectories), a reasoning framework for cold-start LLM personalization. PAT first retrieves information along two complementary trajectories: writing-style cues from stylistically similar users and topic-specific context from preference-aligned users. It then employs a reinforcement learning-based, iterative dual-reasoning mechanism that enables the LLM to jointly refine and integrate these signals. Experimental results across real-world personalization benchmarks show that PAT consistently improves generation quality and alignment under sparse-data conditions, establishing a strong solution to the cold-start personalization problem.
Human-Aligned MLLM Judges for Fine-Grained Image Editing Evaluation: A Benchmark, Framework, and Analysis
Feb 13, 2026Evaluating image editing models remains challenging due to the coarse granularity and limited interpretability of traditional metrics, which often fail to capture aspects important to human perception and intent. Such metrics frequently reward visually plausible outputs while overlooking controllability, edit localization, and faithfulness to user instructions. In this work, we introduce a fine-grained Multimodal Large Language Model (MLLM)-as-a-Judge framework for image editing that decomposes common evaluation notions into twelve fine-grained interpretable factors spanning image preservation, edit quality, and instruction fidelity. Building on this formulation, we present a new human-validated benchmark that integrates human judgments, MLLM-based evaluations, model outputs, and traditional metrics across diverse image editing tasks. Through extensive human studies, we show that the proposed MLLM judges align closely with human evaluations at a fine granularity, supporting their use as reliable and scalable evaluators. We further demonstrate that traditional image editing metrics are often poor proxies for these factors, failing to distinguish over-edited or semantically imprecise outputs, whereas our judges provide more intuitive and informative assessments in both offline and online settings. Together, this work introduces a benchmark, a principled factorization, and empirical evidence positioning fine-grained MLLM judges as a practical foundation for studying, comparing, and improving image editing approaches.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
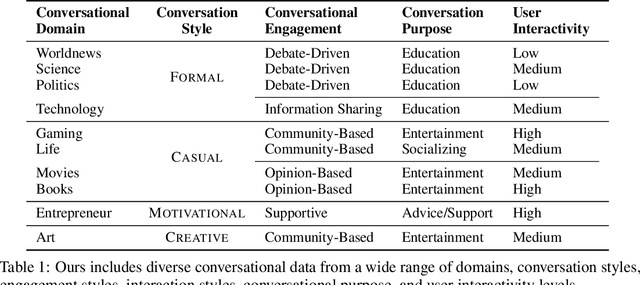


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025



Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Large Language Model-based Augmentation for Imbalanced Node Classification on Text-Attributed Graphs
Oct 22, 2024



Node classification on graphs frequently encounters the challenge of class imbalance, leading to biased performance and posing significant risks in real-world applications. Although several data-centric solutions have been proposed, none of them focus on Text-Attributed Graphs (TAGs), and therefore overlook the potential of leveraging the rich semantics encoded in textual features for boosting the classification of minority nodes. Given this crucial gap, we investigate the possibility of augmenting graph data in the text space, leveraging the textual generation power of Large Language Models (LLMs) to handle imbalanced node classification on TAGs. Specifically, we propose a novel approach called LA-TAG (LLM-based Augmentation on Text-Attributed Graphs), which prompts LLMs to generate synthetic texts based on existing node texts in the graph. Furthermore, to integrate these synthetic text-attributed nodes into the graph, we introduce a text-based link predictor to connect the synthesized nodes with the existing nodes. Our experiments across multiple datasets and evaluation metrics show that our framework significantly outperforms traditional non-textual-based data augmentation strategies and specific node imbalance solutions. This highlights the promise of using LLMs to resolve imbalance issues on TAGs.
Towards Trustworthy Knowledge Graph Reasoning: An Uncertainty Aware Perspective
Oct 11, 2024



Recently, Knowledge Graphs (KGs) have been successfully coupled with Large Language Models (LLMs) to mitigate their hallucinations and enhance their reasoning capability, such as in KG-based retrieval-augmented frameworks. However, current KG-LLM frameworks lack rigorous uncertainty estimation, limiting their reliable deployment in high-stakes applications. Directly incorporating uncertainty quantification into KG-LLM frameworks presents challenges due to their complex architectures and the intricate interactions between the knowledge graph and language model components. To address this gap, we propose a new trustworthy KG-LLM framework, Uncertainty Aware Knowledge-Graph Reasoning (UAG), which incorporates uncertainty quantification into the KG-LLM framework. We design an uncertainty-aware multi-step reasoning framework that leverages conformal prediction to provide a theoretical guarantee on the prediction set. To manage the error rate of the multi-step process, we additionally introduce an error rate control module to adjust the error rate within the individual components. Extensive experiments show that our proposed UAG can achieve any pre-defined coverage rate while reducing the prediction set/interval size by 40% on average over the baselines.
Augmenting Textual Generation via Topology Aware Retrieval
May 27, 2024



Despite the impressive advancements of Large Language Models (LLMs) in generating text, they are often limited by the knowledge contained in the input and prone to producing inaccurate or hallucinated content. To tackle these issues, Retrieval-augmented Generation (RAG) is employed as an effective strategy to enhance the available knowledge base and anchor the responses in reality by pulling additional texts from external databases. In real-world applications, texts are often linked through entities within a graph, such as citations in academic papers or comments in social networks. This paper exploits these topological relationships to guide the retrieval process in RAG. Specifically, we explore two kinds of topological connections: proximity-based, focusing on closely connected nodes, and role-based, which looks at nodes sharing similar subgraph structures. Our empirical research confirms their relevance to text relationships, leading us to develop a Topology-aware Retrieval-augmented Generation framework. This framework includes a retrieval module that selects texts based on their topological relationships and an aggregation module that integrates these texts into prompts to stimulate LLMs for text generation. We have curated established text-attributed networks and conducted comprehensive experiments to validate the effectiveness of this framework, demonstrating its potential to enhance RAG with topological awareness.
MechAgents: Large language model multi-agent collaborations can solve mechanics problems, generate new data, and integrate knowledge
Nov 14, 2023



Solving mechanics problems using numerical methods requires comprehensive intelligent capability of retrieving relevant knowledge and theory, constructing and executing codes, analyzing the results, a task that has thus far mainly been reserved for humans. While emerging AI methods can provide effective approaches to solve end-to-end problems, for instance via the use of deep surrogate models or various data analytics strategies, they often lack physical intuition since knowledge is baked into the parametric complement through training, offering less flexibility when it comes to incorporating mathematical or physical insights. By leveraging diverse capabilities of multiple dynamically interacting large language models (LLMs), we can overcome the limitations of conventional approaches and develop a new class of physics-inspired generative machine learning platform, here referred to as MechAgents. A set of AI agents can solve mechanics tasks, here demonstrated for elasticity problems, via autonomous collaborations. A two-agent team can effectively write, execute and self-correct code, in order to apply finite element methods to solve classical elasticity problems in various flavors (different boundary conditions, domain geometries, meshes, small/finite deformation and linear/hyper-elastic constitutive laws, and others). For more complex tasks, we construct a larger group of agents with enhanced division of labor among planning, formulating, coding, executing and criticizing the process and results. The agents mutually correct each other to improve the overall team-work performance in understanding, formulating and validating the solution. Our framework shows the potential of synergizing the intelligence of language models, the reliability of physics-based modeling, and the dynamic collaborations among diverse agents, opening novel avenues for automation of solving engineering problems.
ForceGen: End-to-end de novo protein generation based on nonlinear mechanical unfolding responses using a protein language diffusion model
Oct 16, 2023



Through evolution, nature has presented a set of remarkable protein materials, including elastins, silks, keratins and collagens with superior mechanical performances that play crucial roles in mechanobiology. However, going beyond natural designs to discover proteins that meet specified mechanical properties remains challenging. Here we report a generative model that predicts protein designs to meet complex nonlinear mechanical property-design objectives. Our model leverages deep knowledge on protein sequences from a pre-trained protein language model and maps mechanical unfolding responses to create novel proteins. Via full-atom molecular simulations for direct validation, we demonstrate that the designed proteins are novel, and fulfill the targeted mechanical properties, including unfolding energy and mechanical strength, as well as the detailed unfolding force-separation curves. Our model offers rapid pathways to explore the enormous mechanobiological protein sequence space unconstrained by biological synthesis, using mechanical features as target to enable the discovery of protein materials with superior mechanical properties.