 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXmix: Unified Generative Pretraining for Vision Language Models in Medical Imaging
Apr 24, 2026Recent medical multimodal foundation models are built as multimodal LLMs (MLLMs) by connecting a CLIP-pretrained vision encoder to an LLM using LLaVA-style finetuning. This two-stage, decoupled approach introduces a projection layer that can distort visual features. This is especially concerning in medical imaging where subtle cues are essential for accurate diagnoses. In contrast, early-fusion generative approaches such as Chameleon eliminate the projection bottleneck by processing image and text tokens within a single unified sequence, enabling joint representation learning that leverages the inductive priors of language models. We present CheXmix, a unified early-fusion generative model trained on a large corpus of chest X-rays paired with radiology reports. We expand on Chameleon's autoregressive framework by introducing a two-stage multimodal generative pretraining strategy that combines the representational strengths of masked autoencoders with MLLMs. The resulting models are highly flexible, supporting both discriminative and generative tasks at both coarse and fine-grained scales. Our approach outperforms well-established generative models across all masking ratios by 6.0% and surpasses CheXagent by 8.6% on AUROC at high image masking ratios on the CheXpert classification task. We further inpaint images over 51.0% better than text-only generative models and outperform CheXagent by 45% on the GREEN metric for radiology report generation. These results demonstrate that CheXmix captures fine-grained information across a broad spectrum of chest X-ray tasks. Our code is at: https://github.com/StanfordMIMI/CheXmix.
Cite-While-You-Generate: Training-Free Evidence Attribution for Multimodal Clinical Summarization
Jan 23, 2026Trustworthy clinical summarization requires not only fluent generation but also transparency about where each statement comes from. We propose a training-free framework for generation-time source attribution that leverages decoder attentions to directly cite supporting text spans or images, overcoming the limitations of post-hoc or retraining-based methods. We introduce two strategies for multimodal attribution: a raw image mode, which directly uses image patch attentions, and a caption-as-span mode, which substitutes images with generated captions to enable purely text-based alignment. Evaluations on two representative domains: clinician-patient dialogues (CliConSummation) and radiology reports (MIMIC-CXR), show that our approach consistently outperforms embedding-based and self-attribution baselines, improving both text-level and multimodal attribution accuracy (e.g., +15% F1 over embedding baselines). Caption-based attribution achieves competitive performance with raw-image attention while being more lightweight and practical. These findings highlight attention-guided attribution as a promising step toward interpretable and deployable clinical summarization systems.
JEDA: Query-Free Clinical Order Search from Ambient Dialogues
Oct 16, 2025Clinical conversations mix explicit directives (order a chest X-ray) with implicit reasoning (the cough worsened overnight, we should check for pneumonia). Many systems rely on LLM rewriting, adding latency, instability, and opacity that hinder real-time ordering. We present JEDA (Joint Embedding for Direct and Ambient clinical orders), a domain-initialized bi-encoder that retrieves canonical orders directly and, in a query-free mode, encodes a short rolling window of ambient dialogue to trigger retrieval. Initialized from PubMedBERT and fine-tuned with a duplicate-safe contrastive objective, JEDA aligns heterogeneous expressions of intent to shared order concepts. Training uses constrained LLM guidance to tie each signed order to complementary formulations (command only, context only, command+context, context+reasoning), producing clearer inter-order separation, tighter query extendash order coupling, and stronger generalization. The query-free mode is noise-resilient, reducing sensitivity to disfluencies and ASR errors by conditioning on a short window rather than a single utterance. Deployed in practice, JEDA yields large gains and substantially outperforms its base encoder and recent open embedders (Linq Embed Mistral, SFR Embedding, GTE Qwen, BGE large, Embedding Gemma). The result is a fast, interpretable, LLM-free retrieval layer that links ambient context to actionable clinical orders in real time.
Permissioned LLMs: Enforcing Access Control in Large Language Models
May 28, 2025


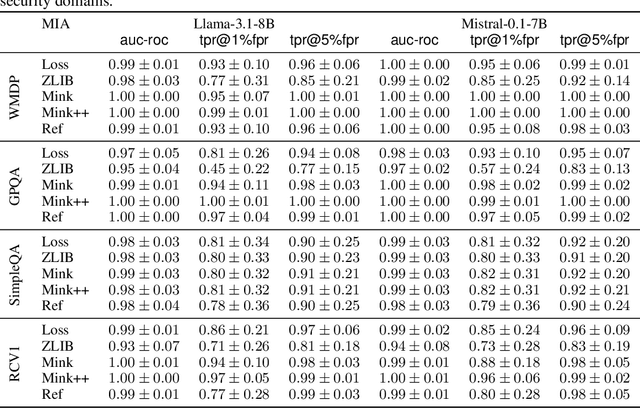
In enterprise settings, organizational data is segregated, siloed and carefully protected by elaborate access control frameworks. These access control structures can completely break down if an LLM fine-tuned on the siloed data serves requests, for downstream tasks, from individuals with disparate access privileges. We propose Permissioned LLMs (PermLLM), a new class of LLMs that superimpose the organizational data access control structures on query responses they generate. We formalize abstractions underpinning the means to determine whether access control enforcement happens correctly over LLM query responses. Our formalism introduces the notion of a relevant response that can be used to prove whether a PermLLM mechanism has been implemented correctly. We also introduce a novel metric, called access advantage, to empirically evaluate the efficacy of a PermLLM mechanism. We introduce three novel PermLLM mechanisms that build on Parameter Efficient Fine-Tuning to achieve the desired access control. We furthermore present two instantiations of access advantage--(i) Domain Distinguishability Index (DDI) based on Membership Inference Attacks, and (ii) Utility Gap Index (UGI) based on LLM utility evaluation. We demonstrate the efficacy of our PermLLM mechanisms through extensive experiments on four public datasets (GPQA, RCV1, SimpleQA, and WMDP), in addition to evaluating the validity of DDI and UGI metrics themselves for quantifying access control in LLMs.
RedactOR: An LLM-Powered Framework for Automatic Clinical Data De-Identification
May 23, 2025Ensuring clinical data privacy while preserving utility is critical for AI-driven healthcare and data analytics. Existing de-identification (De-ID) methods, including rule-based techniques, deep learning models, and large language models (LLMs), often suffer from recall errors, limited generalization, and inefficiencies, limiting their real-world applicability. We propose a fully automated, multi-modal framework, RedactOR for de-identifying structured and unstructured electronic health records, including clinical audio records. Our framework employs cost-efficient De-ID strategies, including intelligent routing, hybrid rule and LLM based approaches, and a two-step audio redaction approach. We present a retrieval-based entity relexicalization approach to ensure consistent substitutions of protected entities, thereby enhancing data coherence for downstream applications. We discuss key design desiderata, de-identification and relexicalization methodology, and modular architecture of RedactX and its integration with the Oracle Health Clinical AI system. Evaluated on the i2b2 2014 De-ID dataset using standard metrics with strict recall, our approach achieves competitive performance while optimizing token usage to reduce LLM costs. Finally, we discuss key lessons and insights from deployment in real-world AI- driven healthcare data pipelines.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025



Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Measuring Distributional Shifts in Text: The Advantage of Language Model-Based Embeddings
Dec 04, 2023



An essential part of monitoring machine learning models in production is measuring input and output data drift. In this paper, we present a system for measuring distributional shifts in natural language data and highlight and investigate the potential advantage of using large language models (LLMs) for this problem. Recent advancements in LLMs and their successful adoption in different domains indicate their effectiveness in capturing semantic relationships for solving various natural language processing problems. The power of LLMs comes largely from the encodings (embeddings) generated in the hidden layers of the corresponding neural network. First we propose a clustering-based algorithm for measuring distributional shifts in text data by exploiting such embeddings. Then we study the effectiveness of our approach when applied to text embeddings generated by both LLMs and classical embedding algorithms. Our experiments show that general-purpose LLM-based embeddings provide a high sensitivity to data drift compared to other embedding methods. We propose drift sensitivity as an important evaluation metric to consider when comparing language models. Finally, we present insights and lessons learned from deploying our framework as part of the Fiddler ML Monitoring platform over a period of 18 months.
Designing Closed-Loop Models for Task Allocation
May 31, 2023Automatically assigning tasks to people is challenging because human performance can vary across tasks for many reasons. This challenge is further compounded in real-life settings in which no oracle exists to assess the quality of human decisions and task assignments made. Instead, we find ourselves in a "closed" decision-making loop in which the same fallible human decisions we rely on in practice must also be used to guide task allocation. How can imperfect and potentially biased human decisions train an accurate allocation model? Our key insight is to exploit weak prior information on human-task similarity to bootstrap model training. We show that the use of such a weak prior can improve task allocation accuracy, even when human decision-makers are fallible and biased. We present both theoretical analysis and empirical evaluation over synthetic data and a social media toxicity detection task. Results demonstrate the efficacy of our approach.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022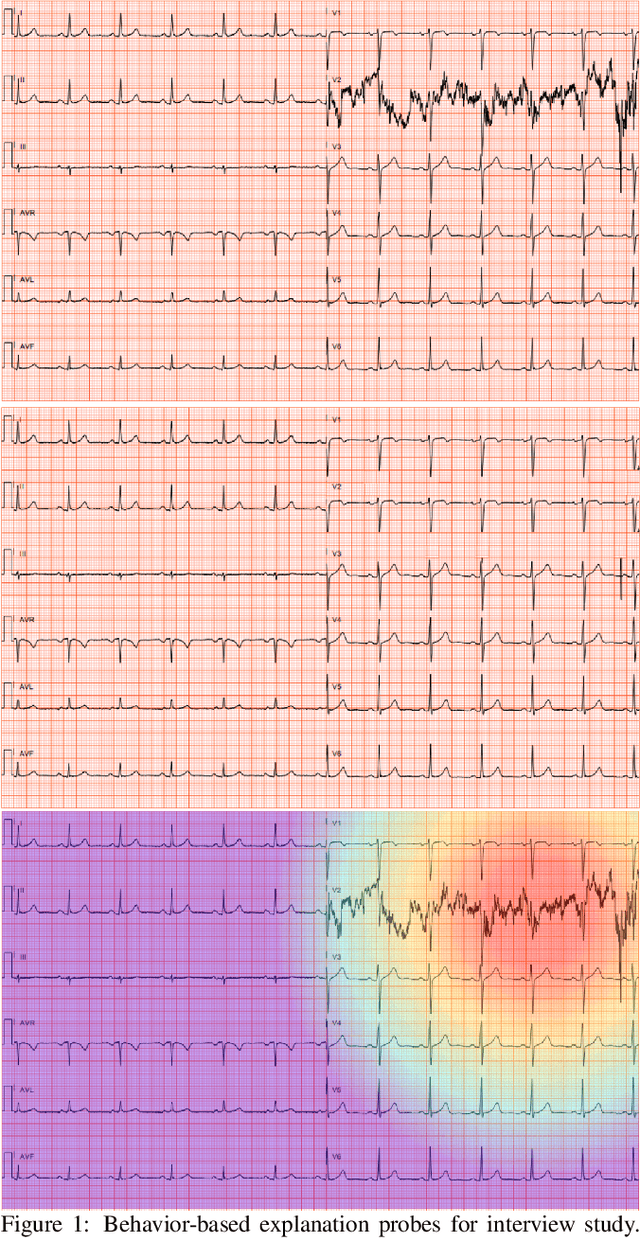

When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
Visual Auditor: Interactive Visualization for Detection and Summarization of Model Biases
Jun 25, 2022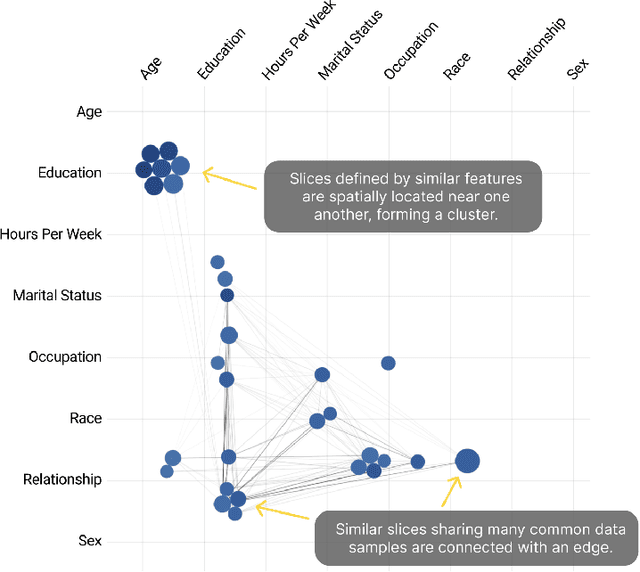

As machine learning (ML) systems become increasingly widespread, it is necessary to audit these systems for biases prior to their deployment. Recent research has developed algorithms for effectively identifying intersectional bias in the form of interpretable, underperforming subsets (or slices) of the data. However, these solutions and their insights are limited without a tool for visually understanding and interacting with the results of these algorithms. We propose Visual Auditor, an interactive visualization tool for auditing and summarizing model biases. Visual Auditor assists model validation by providing an interpretable overview of intersectional bias (bias that is present when examining populations defined by multiple features), details about relationships between problematic data slices, and a comparison between underperforming and overperforming data slices in a model. Our open-source tool runs directly in both computational notebooks and web browsers, making model auditing accessible and easily integrated into current ML development workflows. An observational user study in collaboration with domain experts at Fiddler AI highlights that our tool can help ML practitioners identify and understand model biases.