 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimentation Accelerator: Interpretable Insights and Creative Recommendations for A/B Testing with Content-Aware ranking
Feb 14, 2026Modern online experimentation faces two bottlenecks: scarce traffic forces tough choices on which variants to test, and post-hoc insight extraction is manual, inconsistent, and often content-agnostic. Meanwhile, organizations underuse historical A/B results and rich content embeddings that could guide prioritization and creative iteration. We present a unified framework to (i) prioritize which variants to test, (ii) explain why winners win, and (iii) surface targeted opportunities for new, higher-potential variants. Leveraging treatment embeddings and historical outcomes, we train a CTR ranking model with fixed effects for contextual shifts that scores candidates while balancing value and content diversity. For better interpretability and understanding, we project treatments onto curated semantic marketing attributes and re-express the ranker in this space via a sign-consistent, sparse constrained Lasso, yielding per-attribute coefficients and signed contributions for visual explanations, top-k drivers, and natural-language insights. We then compute an opportunity index combining attribute importance (from the ranker) with under-expression in the current experiment to flag missing, high-impact attributes. Finally, LLMs translate ranked opportunities into concrete creative suggestions and estimate both learning and conversion potential, enabling faster, more informative, and more efficient test cycles. These components have been built into a real Adobe product, called \textit{Experimentation Accelerator}, to provide AI-based insights and opportunities to scale experimentation for customers. We provide an evaluation of the performance of the proposed framework on some real-world experiments by Adobe business customers that validate the high quality of the generation pipeline.
Dialectics for Artificial Intelligence
Dec 23, 2025



Can artificial intelligence discover, from raw experience and without human supervision, concepts that humans have discovered? One challenge is that human concepts themselves are fluid: conceptual boundaries can shift, split, and merge as inquiry progresses (e.g., Pluto is no longer considered a planet). To make progress, we need a definition of "concept" that is not merely a dictionary label, but a structure that can be revised, compared, and aligned across agents. We propose an algorithmic-information viewpoint that treats a concept as an information object defined only through its structural relation to an agent's total experience. The core constraint is determination: a set of parts forms a reversible consistency relation if any missing part is recoverable from the others (up to the standard logarithmic slack in Kolmogorov-style identities). This reversibility prevents "concepts" from floating free of experience and turns concept existence into a checkable structural claim. To judge whether a decomposition is natural, we define excess information, measuring the redundancy overhead introduced by splitting experience into multiple separately described parts. On top of these definitions, we formulate dialectics as an optimization dynamics: as new patches of information appear (or become contested), competing concepts bid to explain them via shorter conditional descriptions, driving systematic expansion, contraction, splitting, and merging. Finally, we formalize low-cost concept transmission and multi-agent alignment using small grounds/seeds that allow another agent to reconstruct the same concept under a shared protocol, making communication a concrete compute-bits trade-off.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
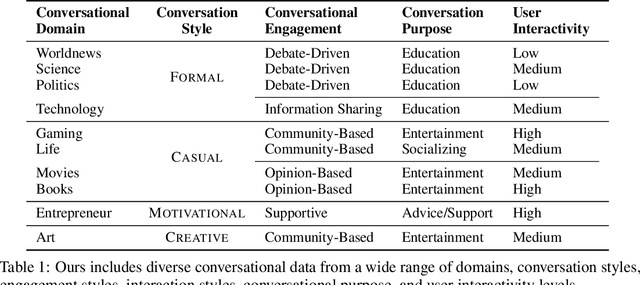


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
Exploring Rewriting Approaches for Different Conversational Tasks
Feb 26, 2025



Conversational assistants often require a question rewriting algorithm that leverages a subset of past interactions to provide a more meaningful (accurate) answer to the user's question or request. However, the exact rewriting approach may often depend on the use case and application-specific tasks supported by the conversational assistant, among other constraints. In this paper, we systematically investigate two different approaches, denoted as rewriting and fusion, on two fundamentally different generation tasks, including a text-to-text generation task and a multimodal generative task that takes as input text and generates a visualization or data table that answers the user's question. Our results indicate that the specific rewriting or fusion approach highly depends on the underlying use case and generative task. In particular, we find that for a conversational question-answering assistant, the query rewriting approach performs best, whereas for a data analysis assistant that generates visualizations and data tables based on the user's conversation with the assistant, the fusion approach works best. Notably, we explore two datasets for the data analysis assistant use case, for short and long conversations, and we find that query fusion always performs better, whereas for the conversational text-based question-answering, the query rewrite approach performs best.
Towards Optimal Multi-draft Speculative Decoding
Feb 26, 2025Large Language Models (LLMs) have become an indispensable part of natural language processing tasks. However, autoregressive sampling has become an efficiency bottleneck. Multi-Draft Speculative Decoding (MDSD) is a recent approach where, when generating each token, a small draft model generates multiple drafts, and the target LLM verifies them in parallel, ensuring that the final output conforms to the target model distribution. The two main design choices in MDSD are the draft sampling method and the verification algorithm. For a fixed draft sampling method, the optimal acceptance rate is a solution to an optimal transport problem, but the complexity of this problem makes it difficult to solve for the optimal acceptance rate and measure the gap between existing verification algorithms and the theoretical upper bound. This paper discusses the dual of the optimal transport problem, providing a way to efficiently compute the optimal acceptance rate. For the first time, we measure the theoretical upper bound of MDSD efficiency for vocabulary sizes in the thousands and quantify the gap between existing verification algorithms and this bound. We also compare different draft sampling methods based on their optimal acceptance rates. Our results show that the draft sampling method strongly influences the optimal acceptance rate, with sampling without replacement outperforming sampling with replacement. Additionally, existing verification algorithms do not reach the theoretical upper bound for both without replacement and with replacement sampling. Our findings suggest that carefully designed draft sampling methods can potentially improve the optimal acceptance rate and enable the development of verification algorithms that closely match the theoretical upper bound.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
GUI Agents: A Survey
Dec 18, 2024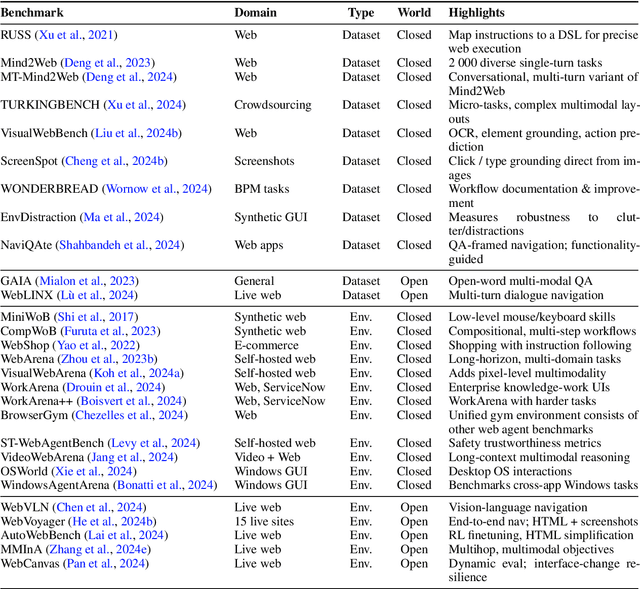
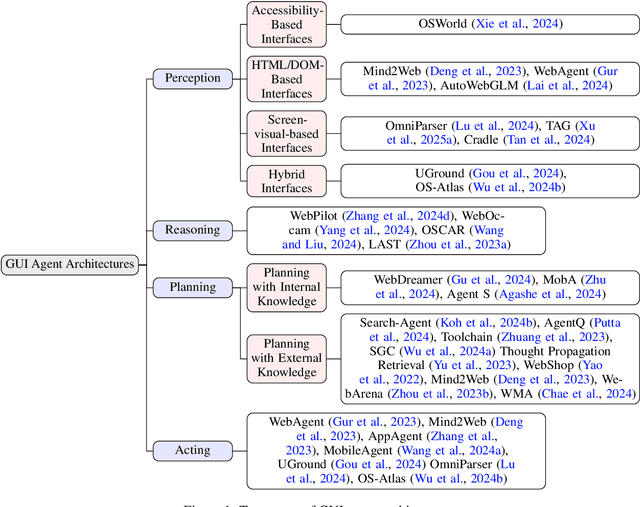

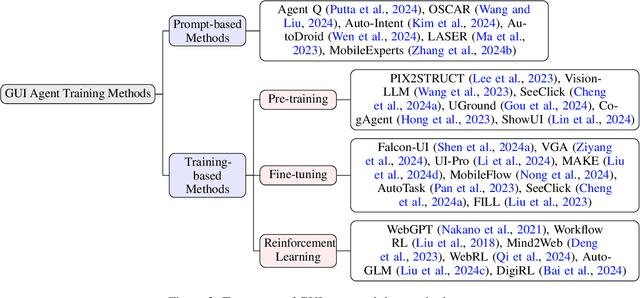
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
Fast and scalable Wasserstein-1 neural optimal transport solver for single-cell perturbation prediction
Nov 01, 2024



Predicting single-cell perturbation responses requires mapping between two unpaired single-cell data distributions. Optimal transport (OT) theory provides a principled framework for constructing such mappings by minimizing transport cost. Recently, Wasserstein-2 ($W_2$) neural optimal transport solvers (\textit{e.g.}, CellOT) have been employed for this prediction task. However, $W_2$ OT relies on the general Kantorovich dual formulation, which involves optimizing over two conjugate functions, leading to a complex min-max optimization problem that converges slowly. To address these challenges, we propose a novel solver based on the Wasserstein-1 ($W_1$) dual formulation. Unlike $W_2$, the $W_1$ dual simplifies the optimization to a maximization problem over a single 1-Lipschitz function, thus eliminating the need for time-consuming min-max optimization. While solving the $W_1$ dual only reveals the transport direction and does not directly provide a unique optimal transport map, we incorporate an additional step using adversarial training to determine an appropriate transport step size, effectively recovering the transport map. Our experiments demonstrate that the proposed $W_1$ neural optimal transport solver can mimic the $W_2$ OT solvers in finding a unique and ``monotonic" map on 2D datasets. Moreover, the $W_1$ OT solver achieves performance on par with or surpasses $W_2$ OT solvers on real single-cell perturbation datasets. Furthermore, we show that $W_1$ OT solver achieves $25 \sim 45\times$ speedup, scales better on high dimensional transportation task, and can be directly applied on single-cell RNA-seq dataset with highly variable genes. Our implementation and experiments are open-sourced at \url{https://github.com/poseidonchan/w1ot}.