 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Improving Long-Range Navigation with Spatially-Enhanced Recurrent Memory via End-to-End Reinforcement Learning
Jun 06, 2025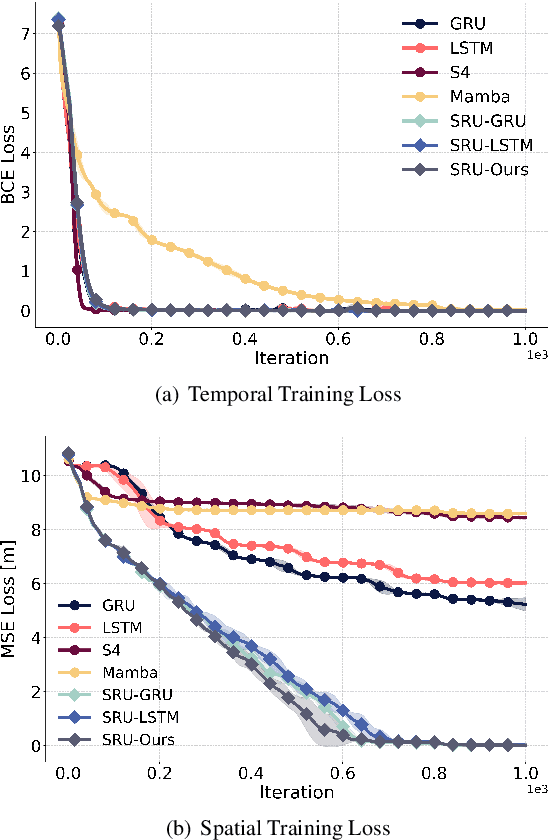
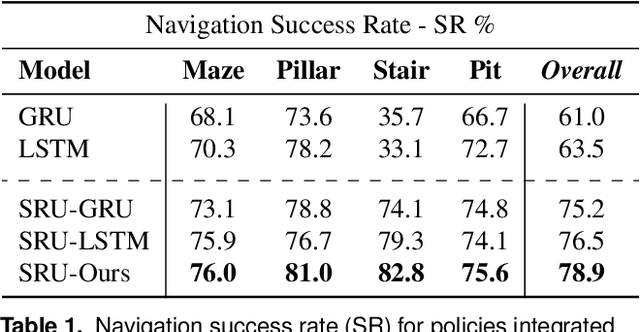
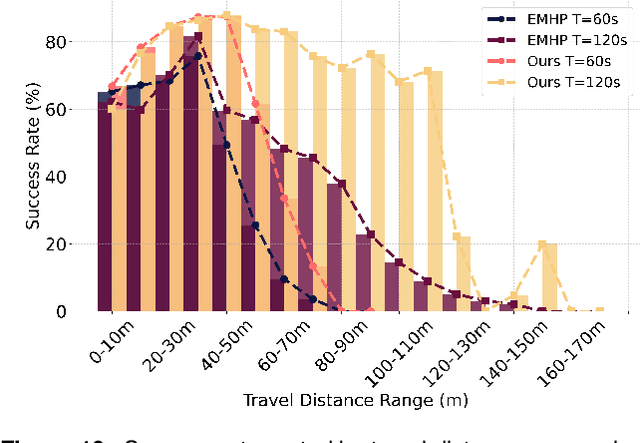

Recent advancements in robot navigation, especially with end-to-end learning approaches like reinforcement learning (RL), have shown remarkable efficiency and effectiveness. Yet, successful navigation still relies on two key capabilities: mapping and planning, whether explicit or implicit. Classical approaches use explicit mapping pipelines to register ego-centric observations into a coherent map frame for the planner. In contrast, end-to-end learning achieves this implicitly, often through recurrent neural networks (RNNs) that fuse current and past observations into a latent space for planning. While architectures such as LSTM and GRU capture temporal dependencies, our findings reveal a key limitation: their inability to perform effective spatial memorization. This skill is essential for transforming and integrating sequential observations from varying perspectives to build spatial representations that support downstream planning. To address this, we propose Spatially-Enhanced Recurrent Units (SRUs), a simple yet effective modification to existing RNNs, designed to enhance spatial memorization capabilities. We introduce an attention-based architecture with SRUs, enabling long-range navigation using a single forward-facing stereo camera. Regularization techniques are employed to ensure robust end-to-end recurrent training via RL. Experimental results show our approach improves long-range navigation by 23.5% compared to existing RNNs. Furthermore, with SRU memory, our method outperforms the RL baseline with explicit mapping and memory modules, achieving a 29.6% improvement in diverse environments requiring long-horizon mapping and memorization. Finally, we address the sim-to-real gap by leveraging large-scale pretraining on synthetic depth data, enabling zero-shot transfer to diverse and complex real-world environments.
NGA: Non-autoregressive Generative Auction with Global Externalities for Advertising Systems
Jun 06, 2025


Online advertising auctions are fundamental to internet commerce, demanding solutions that not only maximize revenue but also ensure incentive compatibility, high-quality user experience, and real-time efficiency. While recent learning-based auction frameworks have improved context modeling by capturing intra-list dependencies among ads, they remain limited in addressing global externalities and often suffer from inefficiencies caused by sequential processing. In this work, we introduce the Non-autoregressive Generative Auction with global externalities (NGA), a novel end-to-end framework designed for industrial online advertising. NGA explicitly models global externalities by jointly capturing the relationships among ads as well as the effects of adjacent organic content. To further enhance efficiency, NGA utilizes a non-autoregressive, constraint-based decoding strategy and a parallel multi-tower evaluator for unified list-wise reward and payment computation. Extensive offline experiments and large-scale online A/B testing on commercial advertising platforms demonstrate that NGA consistently outperforms existing methods in both effectiveness and efficiency.
Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models
May 27, 2025Large Multimodal Models (LMMs) have recently demonstrated remarkable visual understanding performance on both vision-language and vision-centric tasks. However, they often fall short in integrating advanced, task-specific capabilities for compositional reasoning, which hinders their progress toward truly competent general vision models. To address this, we present a unified visual reasoning mechanism that enables LMMs to solve complicated compositional problems by leveraging their intrinsic capabilities (e.g. grounding and visual understanding capabilities). Different from the previous shortcut learning mechanism, our approach introduces a human-like understanding-thinking-answering process, allowing the model to complete all steps in a single pass forwarding without the need for multiple inferences or external tools. This design bridges the gap between foundational visual capabilities and general question answering, encouraging LMMs to generate faithful and traceable responses for complex visual reasoning. Meanwhile, we curate 334K visual instruction samples covering both general scenes and text-rich scenes and involving multiple foundational visual capabilities. Our trained model, Griffon-R, has the ability of end-to-end automatic understanding, self-thinking, and reasoning answers. Comprehensive experiments show that Griffon-R not only achieves advancing performance on complex visual reasoning benchmarks including VSR and CLEVR, but also enhances multimodal capabilities across various benchmarks like MMBench and ScienceQA. Data, models, and codes will be release at https://github.com/jefferyZhan/Griffon/tree/master/Griffon-R soon.
Why Distillation can Outperform Zero-RL: The Role of Flexible Reasoning
May 27, 2025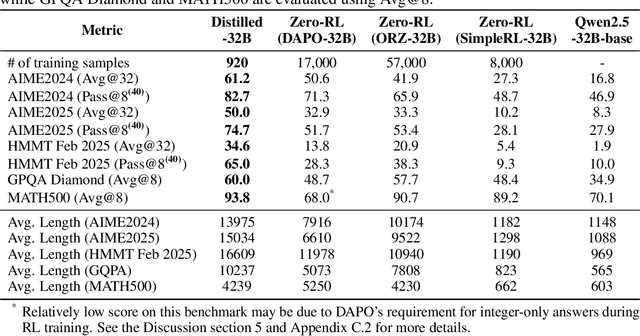
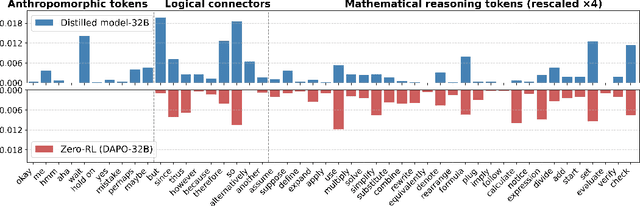

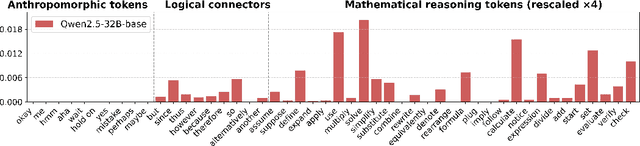
Reinforcement learning (RL) has played an important role in improving the reasoning ability of large language models (LLMs). Some studies apply RL directly to \textit{smaller} base models (known as zero-RL) and also achieve notable progress. However, in this paper, we show that using only 920 examples, a simple distillation method based on the base model can clearly outperform zero-RL, which typically requires much more data and computational cost. By analyzing the token frequency in model outputs, we find that the distilled model shows more flexible reasoning. It uses anthropomorphic tokens and logical connectors much more often than the zero-RL model. Further analysis reveals that distillation enhances the presence of two advanced cognitive behaviors: Multi-Perspective Thinking or Attempting and Metacognitive Awareness. Frequent occurrences of these two advanced cognitive behaviors give rise to flexible reasoning, which is essential for solving complex reasoning problems, while zero-RL fails to significantly boost the frequency of these behaviors.
rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset
May 27, 2025Advancing code reasoning in large language models (LLMs) is fundamentally limited by the scarcity of high-difficulty datasets, especially those with verifiable input-output test cases necessary for rigorous solution validation at scale. We introduce rStar-Coder, which significantly improves LLM code reasoning capabilities by constructing a large-scale, verified dataset of 418K competition-level code problems, 580K long-reasoning solutions along with rich test cases of varying difficulty. This is achieved through three core contributions: (1) we curate competitive programming code problems and oracle solutions to synthesize new, solvable problems; (2) we introduce a reliable input-output test case synthesis pipeline that decouples the generation into a three-step input generation method and a mutual verification mechanism for effective output labeling; (3) we augment problems with high-quality, test-case-verified long-reasoning solutions. Extensive experiments on Qwen models (1.5B-14B) across various code reasoning benchmarks demonstrate the superiority of rStar-Coder dataset, achieving leading performance comparable to frontier reasoning LLMs with much smaller model sizes. On LiveCodeBench, rStar-Coder improves Qwen2.5-7B from 17.4% to an impressive 57.3%, and Qwen2.5-14B from 23.3% to 62.5%, surpassing o3-mini (low) by3.1%. On the more challenging USA Computing Olympiad, our 7B model achieves an average pass@1 accuracy of 16.15%, outperforming the frontier-level QWQ-32B. Code and the dataset will be released at https://github.com/microsoft/rStar.
FieldWorkArena: Agentic AI Benchmark for Real Field Work Tasks
May 26, 2025This paper proposes FieldWorkArena, a benchmark for agentic AI targeting real-world field work. With the recent increase in demand for agentic AI, they are required to monitor and report safety and health incidents, as well as manufacturing-related incidents, that may occur in real-world work environments. Existing agentic AI benchmarks have been limited to evaluating web tasks and are insufficient for evaluating agents in real-world work environments, where complexity increases significantly. In this paper, we define a new action space that agentic AI should possess for real world work environment benchmarks and improve the evaluation function from previous methods to assess the performance of agentic AI in diverse real-world tasks. The dataset consists of videos captured on-site and documents actually used in factories and warehouses, and tasks were created based on interviews with on-site workers and managers. Evaluation results confirmed that performance evaluation considering the characteristics of Multimodal LLM (MLLM) such as GPT-4o is feasible. Additionally, the effectiveness and limitations of the proposed new evaluation method were identified. The complete dataset (HuggingFace) and evaluation program (GitHub) can be downloaded from the following website: https://en-documents.research.global.fujitsu.com/fieldworkarena/.
Beyond Cascaded Architectures: An End-to-end Generative Framework for Industrial Advertising
May 26, 2025



Traditional online industrial advertising systems suffer from the limitations of multi-stage cascaded architectures, which often discard high-potential candidates prematurely and distribute decision logic across disconnected modules. While recent generative recommendation approaches provide end-to-end solutions, they fail to address critical advertising requirements of key components for real-world deployment, such as explicit bidding, creative selection, ad allocation, and payment computation. To bridge this gap, we introduce End-to-End Generative Advertising (EGA), the first unified framework that holistically models user interests, point-of-interest (POI) and creative generation, ad allocation, and payment optimization within a single generative model. Our approach employs hierarchical tokenization and multi-token prediction to jointly generate POI recommendations and ad creatives, while a permutation-aware reward model and token-level bidding strategy ensure alignment with both user experiences and advertiser objectives. Additionally, we decouple allocation from payment using a differentiable ex-post regret minimization mechanism, guaranteeing approximate incentive compatibility at the POI level. Through extensive offline evaluations and large-scale online experiments on real-world advertising platforms, we demonstrate that EGA significantly outperforms traditional cascaded systems in both performance and practicality. Our results highlight its potential as a pioneering fully generative advertising solution, paving the way for next-generation industrial ad systems.
Denoising Concept Vectors with Sparse Autoencoders for Improved Language Model Steering
May 21, 2025Linear Concept Vectors have proven effective for steering large language models (LLMs). While existing approaches like linear probing and difference-in-means derive these vectors from LLM hidden representations, diverse data introduces noises (i.e., irrelevant features) that challenge steering robustness. To address this, we propose Sparse Autoencoder-Denoised Concept Vectors (SDCV), which uses Sparse Autoencoders to filter out noisy features from hidden representations. When applied to linear probing and difference-in-means, our method improves their steering success rates. We validate our noise hypothesis through counterfactual experiments and feature visualizations.
SeedBench: A Multi-task Benchmark for Evaluating Large Language Models in Seed Science
May 19, 2025Seed science is essential for modern agriculture, directly influencing crop yields and global food security. However, challenges such as interdisciplinary complexity and high costs with limited returns hinder progress, leading to a shortage of experts and insufficient technological support. While large language models (LLMs) have shown promise across various fields, their application in seed science remains limited due to the scarcity of digital resources, complex gene-trait relationships, and the lack of standardized benchmarks. To address this gap, we introduce SeedBench -- the first multi-task benchmark specifically designed for seed science. Developed in collaboration with domain experts, SeedBench focuses on seed breeding and simulates key aspects of modern breeding processes. We conduct a comprehensive evaluation of 26 leading LLMs, encompassing proprietary, open-source, and domain-specific fine-tuned models. Our findings not only highlight the substantial gaps between the power of LLMs and the real-world seed science problems, but also make a foundational step for research on LLMs for seed design.