 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
GraphGen: Enhancing Supervised Fine-Tuning for LLMs with Knowledge-Driven Synthetic Data Generation
May 26, 2025Fine-tuning for large language models (LLMs) typically requires substantial amounts of high-quality supervised data, which is both costly and labor-intensive to acquire. While synthetic data generation has emerged as a promising solution, existing approaches frequently suffer from factual inaccuracies, insufficient long-tail coverage, simplistic knowledge structures, and homogenized outputs. To address these challenges, we introduce GraphGen, a knowledge graph-guided framework designed for three key question-answering (QA) scenarios: atomic QA, aggregated QA, and multi-hop QA. It begins by constructing a fine-grained knowledge graph from the source text. It then identifies knowledge gaps in LLMs using the expected calibration error metric, prioritizing the generation of QA pairs that target high-value, long-tail knowledge. Furthermore, GraphGen incorporates multi-hop neighborhood sampling to capture complex relational information and employs style-controlled generation to diversify the resulting QA data. Experimental results on knowledge-intensive tasks under closed-book settings demonstrate that GraphGen outperforms conventional synthetic data methods, offering a more reliable and comprehensive solution to the data scarcity challenge in supervised fine-tuning. The code and data are publicly available at https://github.com/open-sciencelab/GraphGen.
MOSLIM:Align with diverse preferences in prompts through reward classification
May 24, 2025



The multi-objective alignment of Large Language Models (LLMs) is essential for ensuring foundational models conform to diverse human preferences. Current research in this field typically involves either multiple policies or multiple reward models customized for various preferences, or the need to train a preference-specific supervised fine-tuning (SFT) model. In this work, we introduce a novel multi-objective alignment method, MOSLIM, which utilizes a single reward model and policy model to address diverse objectives. MOSLIM provides a flexible way to control these objectives through prompting and does not require preference training during SFT phase, allowing thousands of off-the-shelf models to be directly utilized within this training framework. MOSLIM leverages a multi-head reward model that classifies question-answer pairs instead of scoring them and then optimize policy model with a scalar reward derived from a mapping function that converts classification results from reward model into reward scores. We demonstrate the efficacy of our proposed method across several multi-objective benchmarks and conduct ablation studies on various reward model sizes and policy optimization methods. The MOSLIM method outperforms current multi-objective approaches in most results while requiring significantly fewer GPU computing resources compared with existing policy optimization methods.
SeedBench: A Multi-task Benchmark for Evaluating Large Language Models in Seed Science
May 19, 2025Seed science is essential for modern agriculture, directly influencing crop yields and global food security. However, challenges such as interdisciplinary complexity and high costs with limited returns hinder progress, leading to a shortage of experts and insufficient technological support. While large language models (LLMs) have shown promise across various fields, their application in seed science remains limited due to the scarcity of digital resources, complex gene-trait relationships, and the lack of standardized benchmarks. To address this gap, we introduce SeedBench -- the first multi-task benchmark specifically designed for seed science. Developed in collaboration with domain experts, SeedBench focuses on seed breeding and simulates key aspects of modern breeding processes. We conduct a comprehensive evaluation of 26 leading LLMs, encompassing proprietary, open-source, and domain-specific fine-tuned models. Our findings not only highlight the substantial gaps between the power of LLMs and the real-world seed science problems, but also make a foundational step for research on LLMs for seed design.
NVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Visual Perception For Self Driving
Mar 30, 2023



Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
Confidence Propagation Cluster: Unleash Full Potential of Object Detectors
Dec 10, 2021
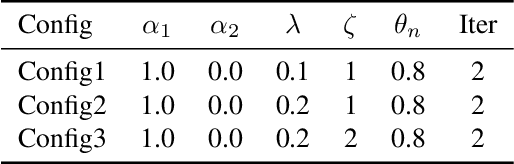

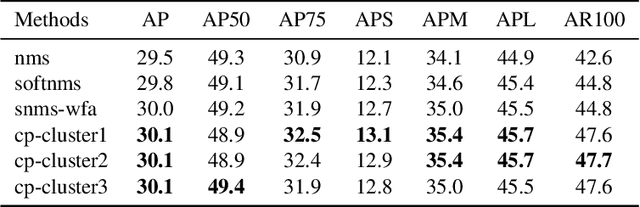
It has been a long history that most object detection methods obtain objects by using the non-maximum suppression (NMS) and its improved versions like Soft-NMS to remove redundant bounding boxes. We challenge those NMS-based methods from three aspects: 1) The bounding box with highest confidence value may not be the true positive having the biggest overlap with the ground-truth box. 2) Not only suppression is required for redundant boxes, but also confidence enhancement is needed for those true positives. 3) Sorting candidate boxes by confidence values is not necessary so that full parallelism is achievable. In this paper, inspired by belief propagation (BP), we propose the Confidence Propagation Cluster (CP-Cluster) to replace NMS-based methods, which is fully parallelizable as well as better in accuracy. In CP-Cluster, we borrow the message passing mechanism from BP to penalize redundant boxes and enhance true positives simultaneously in an iterative way until convergence. We verified the effectiveness of CP-Cluster by applying it to various mainstream detectors such as FasterRCNN, SSD, FCOS, YOLOv3, YOLOv5, Centernet etc. Experiments on MS COCO show that our plug and play method, without retraining detectors, is able to steadily improve average mAP of all those state-of-the-art models with a clear margin from 0.2 to 1.9 respectively when compared with NMS-based methods. Source code is available at https://github.com/shenyi0220/CP-Cluster