 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
Mar 16, 2026Recent advancements extend Multimodal Large Language Models (MLLMs) beyond standard visual question answering to utilizing external tools for advanced visual tasks. Despite this progress, precisely executing and effectively composing diverse tools for complex tasks remain persistent bottleneck. Constrained by sparse tool-sets and simple tool-use trajectories, existing benchmarks fail to capture complex and diverse tool interactions, falling short in evaluating model performance under practical, real-world conditions. To bridge this gap, we introduce VisualToolChain-Bench~(VTC-Bench), a comprehensive benchmark designed to evaluate tool-use proficiency in MLLMs. To align with realistic computer vision pipelines, our framework features 32 diverse OpenCV-based visual operations. This rich tool-set enables extensive combinations, allowing VTC-Bench to rigorously assess multi-tool composition and long-horizon, multi-step plan execution. For precise evaluation, we provide 680 curated problems structured across a nine-category cognitive hierarchy, each with ground-truth execution trajectories. Extensive experiments on 19 leading MLLMs reveal critical limitations in current models' visual agentic capabilities. Specifically, models struggle to adapt to diverse tool-sets and generalize to unseen operations, with the leading model Gemini-3.0-Pro only achieving 51\% on our benchmark. Furthermore, multi-tool composition remains a persistent challenge. When facing complex tasks, models struggle to formulate efficient execution plans, relying heavily on a narrow, suboptimal subset of familiar functions rather than selecting the optimal tools. By identifying these fundamental challenges, VTC-Bench establishes a rigorous baseline to guide the development of more generalized visual agentic models.
ContextRL: Enhancing MLLM's Knowledge Discovery Efficiency with Context-Augmented RL
Feb 26, 2026We propose ContextRL, a novel framework that leverages context augmentation to overcome these bottlenecks. Specifically, to enhance Identifiability, we provide the reward model with full reference solutions as context, enabling fine-grained process verification to filter out false positives (samples with the right answer but low-quality reasoning process). To improve Reachability, we introduce a multi-turn sampling strategy where the reward model generates mistake reports for failed attempts, guiding the policy to "recover" correct responses from previously all-negative groups. Experimental results on 11 perception and reasoning benchmarks show that ContextRL significantly improves knowledge discovery efficiency. Notably, ContextRL enables the Qwen3-VL-8B model to achieve performance comparable to the 32B model, outperforming standard RLVR baselines by a large margin while effectively mitigating reward hacking. Our in-depth analysis reveals the significant potential of contextual information for improving reward model accuracy and document the widespread occurrence of reward hacking, offering valuable insights for future RLVR research.
MCIE: Multimodal LLM-Driven Complex Instruction Image Editing with Spatial Guidance
Feb 08, 2026Recent advances in instruction-based image editing have shown remarkable progress. However, existing methods remain limited to relatively simple editing operations, hindering real-world applications that require complex and compositional instructions. In this work, we address these limitations from the perspectives of architectural design, data, and evaluation protocols. Specifically, we identify two key challenges in current models: insufficient instruction compliance and background inconsistency. To this end, we propose MCIE-E1, a Multimodal Large Language Model-Driven Complex Instruction Image Editing method that integrates two key modules: a spatial-aware cross-attention module and a background-consistent cross-attention module. The former enhances instruction-following capability by explicitly aligning semantic instructions with spatial regions through spatial guidance during the denoising process, while the latter preserves features in unedited regions to maintain background consistency. To enable effective training, we construct a dedicated data pipeline to mitigate the scarcity of complex instruction-based image editing datasets, combining fine-grained automatic filtering via a powerful MLLM with rigorous human validation. Finally, to comprehensively evaluate complex instruction-based image editing, we introduce CIE-Bench, a new benchmark with two new evaluation metrics. Experimental results on CIE-Bench demonstrate that MCIE-E1 consistently outperforms previous state-of-the-art methods in both quantitative and qualitative assessments, achieving a 23.96% improvement in instruction compliance.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
OmniEarth-Bench: Towards Holistic Evaluation of Earth's Six Spheres and Cross-Spheres Interactions with Multimodal Observational Earth Data
May 29, 2025Existing benchmarks for Earth science multimodal learning exhibit critical limitations in systematic coverage of geosystem components and cross-sphere interactions, often constrained to isolated subsystems (only in Human-activities sphere or atmosphere) with limited evaluation dimensions (less than 16 tasks). To address these gaps, we introduce OmniEarth-Bench, the first comprehensive multimodal benchmark spanning all six Earth science spheres (atmosphere, lithosphere, Oceansphere, cryosphere, biosphere and Human-activities sphere) and cross-spheres with one hundred expert-curated evaluation dimensions. Leveraging observational data from satellite sensors and in-situ measurements, OmniEarth-Bench integrates 29,779 annotations across four tiers: perception, general reasoning, scientific knowledge reasoning and chain-of-thought (CoT) reasoning. This involves the efforts of 2-5 experts per sphere to establish authoritative evaluation dimensions and curate relevant observational datasets, 40 crowd-sourcing annotators to assist experts for annotations, and finally, OmniEarth-Bench is validated via hybrid expert-crowd workflows to reduce label ambiguity. Experiments on 9 state-of-the-art MLLMs reveal that even the most advanced models struggle with our benchmarks, where none of them reach 35\% accuracy. Especially, in some cross-spheres tasks, the performance of leading models like GPT-4o drops to 0.0\%. OmniEarth-Bench sets a new standard for geosystem-aware AI, advancing both scientific discovery and practical applications in environmental monitoring and disaster prediction. The dataset, source code, and trained models were released.
Why Distillation can Outperform Zero-RL: The Role of Flexible Reasoning
May 27, 2025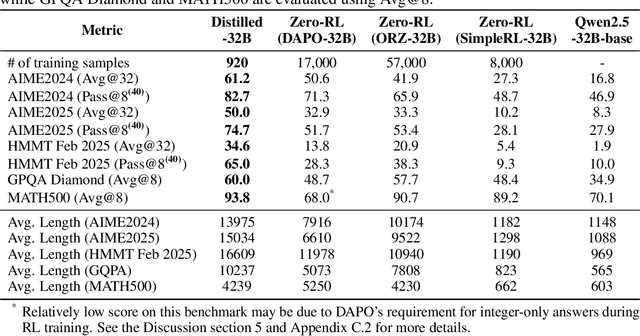
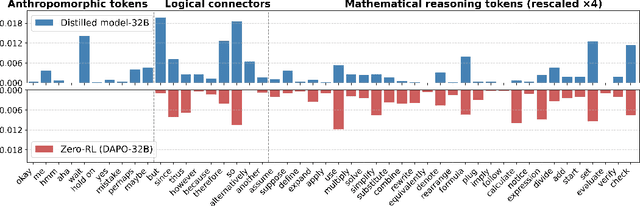

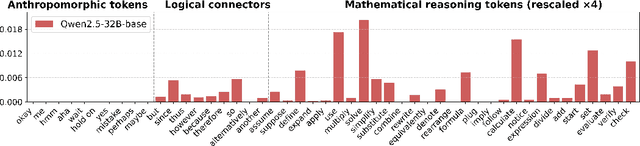
Reinforcement learning (RL) has played an important role in improving the reasoning ability of large language models (LLMs). Some studies apply RL directly to \textit{smaller} base models (known as zero-RL) and also achieve notable progress. However, in this paper, we show that using only 920 examples, a simple distillation method based on the base model can clearly outperform zero-RL, which typically requires much more data and computational cost. By analyzing the token frequency in model outputs, we find that the distilled model shows more flexible reasoning. It uses anthropomorphic tokens and logical connectors much more often than the zero-RL model. Further analysis reveals that distillation enhances the presence of two advanced cognitive behaviors: Multi-Perspective Thinking or Attempting and Metacognitive Awareness. Frequent occurrences of these two advanced cognitive behaviors give rise to flexible reasoning, which is essential for solving complex reasoning problems, while zero-RL fails to significantly boost the frequency of these behaviors.
VLM as Policy: Common-Law Content Moderation Framework for Short Video Platform
Apr 21, 2025Exponentially growing short video platforms (SVPs) face significant challenges in moderating content detrimental to users' mental health, particularly for minors. The dissemination of such content on SVPs can lead to catastrophic societal consequences. Although substantial efforts have been dedicated to moderating such content, existing methods suffer from critical limitations: (1) Manual review is prone to human bias and incurs high operational costs. (2) Automated methods, though efficient, lack nuanced content understanding, resulting in lower accuracy. (3) Industrial moderation regulations struggle to adapt to rapidly evolving trends due to long update cycles. In this paper, we annotate the first SVP content moderation benchmark with authentic user/reviewer feedback to fill the absence of benchmark in this field. Then we evaluate various methods on the benchmark to verify the existence of the aforementioned limitations. We further propose our common-law content moderation framework named KuaiMod to address these challenges. KuaiMod consists of three components: training data construction, offline adaptation, and online deployment & refinement. Leveraging large vision language model (VLM) and Chain-of-Thought (CoT) reasoning, KuaiMod adequately models video toxicity based on sparse user feedback and fosters dynamic moderation policy with rapid update speed and high accuracy. Offline experiments and large-scale online A/B test demonstrates the superiority of KuaiMod: KuaiMod achieves the best moderation performance on our benchmark. The deployment of KuaiMod reduces the user reporting rate by 20% and its application in video recommendation increases both Daily Active User (DAU) and APP Usage Time (AUT) on several Kuaishou scenarios. We have open-sourced our benchmark at https://kuaimod.github.io.
InstructEngine: Instruction-driven Text-to-Image Alignment
Apr 14, 2025



Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF) has been extensively utilized for preference alignment of text-to-image models. Existing methods face certain limitations in terms of both data and algorithm. For training data, most approaches rely on manual annotated preference data, either by directly fine-tuning the generators or by training reward models to provide training signals. However, the high annotation cost makes them difficult to scale up, the reward model consumes extra computation and cannot guarantee accuracy. From an algorithmic perspective, most methods neglect the value of text and only take the image feedback as a comparative signal, which is inefficient and sparse. To alleviate these drawbacks, we propose the InstructEngine framework. Regarding annotation cost, we first construct a taxonomy for text-to-image generation, then develop an automated data construction pipeline based on it. Leveraging advanced large multimodal models and human-defined rules, we generate 25K text-image preference pairs. Finally, we introduce cross-validation alignment method, which refines data efficiency by organizing semantically analogous samples into mutually comparable pairs. Evaluations on DrawBench demonstrate that InstructEngine improves SD v1.5 and SDXL's performance by 10.53% and 5.30%, outperforming state-of-the-art baselines, with ablation study confirming the benefits of InstructEngine's all components. A win rate of over 50% in human reviews also proves that InstructEngine better aligns with human preferences.
DAMO: Data- and Model-aware Alignment of Multi-modal LLMs
Feb 04, 2025



Direct Preference Optimization (DPO) has shown effectiveness in aligning multi-modal large language models (MLLM) with human preferences. However, existing methods exhibit an imbalanced responsiveness to the data of varying hardness, tending to overfit on the easy-to-distinguish data while underfitting on the hard-to-distinguish data. In this paper, we propose Data- and Model-aware DPO (DAMO) to dynamically adjust the optimization process from two key aspects: (1) a data-aware strategy that incorporates data hardness, and (2) a model-aware strategy that integrates real-time model responses. By combining the two strategies, DAMO enables the model to effectively adapt to data with varying levels of hardness. Extensive experiments on five benchmarks demonstrate that DAMO not only significantly enhances the trustworthiness, but also improves the effectiveness over general tasks. For instance, on the Object HalBench, our DAMO-7B reduces response-level and mentioned-level hallucination by 90.0% and 95.3%, respectively, surpassing the performance of GPT-4V.
Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
Dec 17, 2024



The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at https://mdi-benchmark.github.io/