 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Synthetic SDO/AIA 193 A EUV Images from He I 10830 A Observations with Diffusion Model Translator
Jun 07, 2026Routine full-disk EUV imaging has been available only since the modern era, such as SOHO and SDO. To extend EUV coronal context into earlier periods, we leverage the multi-decade availability of full-disk \HeI{} observations, whose absorption is modulated by coronal irradiance and magnetic topology and is widely used as a proxy for open-field regions. We present a diffusion-based conditional image translation framework, Coronal Hole-aware Diffusion Model Translator (CH-aware DMT), to reconstruct synthetic SDO/AIA 193 Å EUV images from \HeI{} inputs. The model is trained on temporally co-aligned SOLIS \HeI{} and AIA 193 Å pairs spanning 2011--2015 using a month-based split, where January--October are used for training, November is used for validation, and December for testing. On the held-out test set, the reconstructions preserve dominant full-disk EUV morphology (CC=0.92) and recover CH-related low-intensity structure (CC=0.84). We further assess historical applicability by (1) comparing reconstructed AIA 193 Å morphology with SOHO/EIT 195 Å over 2005--2015; (2) comparing reconstructed AIA 193 Å images generated from KPVT \HeI{} inputs against Yohkoh/SXT soft X-ray observations; and (3) evaluating long-term reconstructed disk-integrated emission statistics against observational EUV series and independent solar activity proxies (sunspot number and F10.7 radio flux over 1974--2015). These results indicate that CH-aware DMT conditioned on \HeI{} can provide a physically plausible synthetic AIA 193 Å coronal proxy for historical studies, supporting multi-decade analyses of large-scale coronal evolution before the direct EUV imaging was available.
SAE-SSV: Supervised Steering in Sparse Representation Spaces for Reliable Control of Language Models
May 22, 2025Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but controlling their behavior reliably remains challenging, especially in open-ended generation settings. This paper introduces a novel supervised steering approach that operates in sparse, interpretable representation spaces. We employ sparse autoencoders (SAEs)to obtain sparse latent representations that aim to disentangle semantic attributes from model activations. Then we train linear classifiers to identify a small subspace of task-relevant dimensions in latent representations. Finally, we learn supervised steering vectors constrained to this subspace, optimized to align with target behaviors. Experiments across sentiment, truthfulness, and politics polarity steering tasks with multiple LLMs demonstrate that our supervised steering vectors achieve higher success rates with minimal degradation in generation quality compared to existing methods. Further analysis reveals that a notably small subspace is sufficient for effective steering, enabling more targeted and interpretable interventions.
Denoising Concept Vectors with Sparse Autoencoders for Improved Language Model Steering
May 21, 2025Linear Concept Vectors have proven effective for steering large language models (LLMs). While existing approaches like linear probing and difference-in-means derive these vectors from LLM hidden representations, diverse data introduces noises (i.e., irrelevant features) that challenge steering robustness. To address this, we propose Sparse Autoencoder-Denoised Concept Vectors (SDCV), which uses Sparse Autoencoders to filter out noisy features from hidden representations. When applied to linear probing and difference-in-means, our method improves their steering success rates. We validate our noise hypothesis through counterfactual experiments and feature visualizations.
DeepOFormer: Deep Operator Learning with Domain-informed Features for Fatigue Life Prediction
Mar 28, 2025



Fatigue life characterizes the duration a material can function before failure under specific environmental conditions, and is traditionally assessed using stress-life (S-N) curves. While machine learning and deep learning offer promising results for fatigue life prediction, they face the overfitting challenge because of the small size of fatigue experimental data in specific materials. To address this challenge, we propose, DeepOFormer, by formulating S-N curve prediction as an operator learning problem. DeepOFormer improves the deep operator learning framework with a transformer-based encoder and a mean L2 relative error loss function. We also consider Stussi, Weibull, and Pascual and Meeker (PM) features as domain-informed features. These features are motivated by empirical fatigue models. To evaluate the performance of our DeepOFormer, we compare it with different deep learning models and XGBoost on a dataset with 54 S-N curves of aluminum alloys. With seven different aluminum alloys selected for testing, our DeepOFormer achieves an R2 of 0.9515, a mean absolute error of 0.2080, and a mean relative error of 0.5077, significantly outperforming state-of-the-art deep/machine learning methods including DeepONet, TabTransformer, and XGBoost, etc. The results highlight that our Deep0Former integrating with domain-informed features substantially improves prediction accuracy and generalization capabilities for fatigue life prediction in aluminum alloys.
CodeV: Issue Resolving with Visual Data
Dec 23, 2024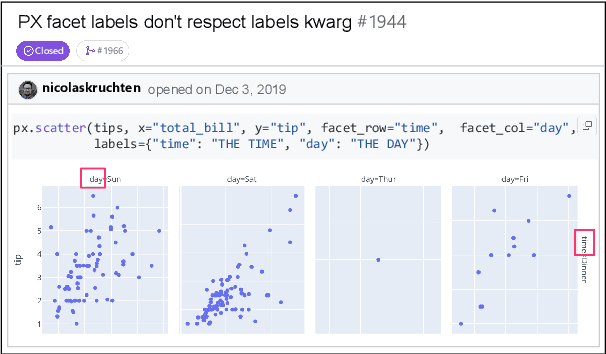
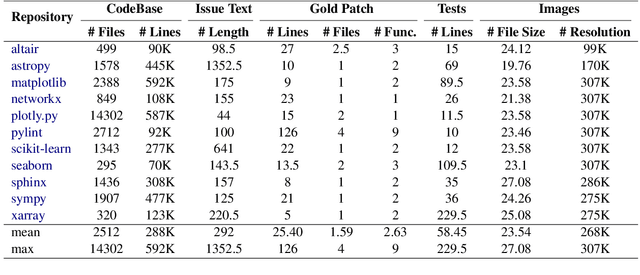


Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.
Deep Computer Vision for Solar Physics Big Data: Opportunities and Challenges
Sep 07, 2024With recent missions such as advanced space-based observatories like the Solar Dynamics Observatory (SDO) and Parker Solar Probe, and ground-based telescopes like the Daniel K. Inouye Solar Telescope (DKIST), the volume, velocity, and variety of data have made solar physics enter a transformative era as solar physics big data (SPBD). With the recent advancement of deep computer vision, there are new opportunities in SPBD for tackling problems that were previously unsolvable. However, there are new challenges arising due to the inherent characteristics of SPBD and deep computer vision models. This vision paper presents an overview of the different types of SPBD, explores new opportunities in applying deep computer vision to SPBD, highlights the unique challenges, and outlines several potential future research directions.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Neural Operator for Accelerating Coronal Magnetic Field Model
May 21, 2024



Studying the sun's outer atmosphere is challenging due to its complex magnetic fields impacting solar activities. Magnetohydrodynamics (MHD) simulations help model these interactions but are extremely time-consuming (usually on a scale of days). Our research applies the Fourier Neural Operator (FNO) to accelerate the coronal magnetic field modeling, specifically, the Bifrost MHD model. We apply Tensorized FNO (TFNO) to generate solutions from partial differential equations (PDEs) over a 3D domain efficiently. TFNO's performance is compared with other deep learning methods, highlighting its accuracy and scalability. Physics analysis confirms that TFNO is reliable and capable of accelerating MHD simulations with high precision. This advancement improves efficiency in data handling, enhances predictive capabilities, and provides a better understanding of magnetic topologies.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Can Programming Languages Boost Each Other via Instruction Tuning?
Sep 03, 2023



When human programmers have mastered a programming language, it would be easier when they learn a new programming language. In this report, we focus on exploring whether programming languages can boost each other during the instruction fine-tuning phase of code large language models. We conduct extensive experiments of 8 popular programming languages (Python, JavaScript, TypeScript, C, C++, Java, Go, HTML) on StarCoder. Results demonstrate that programming languages can significantly improve each other. For example, CodeM-Python 15B trained on Python is able to increase Java by an absolute 17.95% pass@1 on HumanEval-X. More surprisingly, we found that CodeM-HTML 7B trained on the HTML corpus can improve Java by an absolute 15.24% pass@1. Our training data is released at https://github.com/NL2Code/CodeM.