 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL-2.0 Technical Report
Jun 09, 2026We introduce Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model designed to advance long-video understanding and agentic intelligence. To address the challenges of ultra-long contexts, information redundancy, and prohibitive computational costs inherent in hour-level videos, Keye-VL-2.0 is the first to adapt DeepSeek Sparse Attention (DSA) to GQA-based multimodal architectures, enabling lossless 256K context processing while capturing critical frames and long-range temporal dependencies. This architecture is underpinned by a highly optimized training and inference infrastructure, including scalable video I/O, heterogeneous ViT-LM parallelism, and custom DSA kernels that significantly maximize throughput and minimize computational overhead. Furthermore, to overcome the algorithmic dilemma of catastrophic forgetting during multi-task alignment, we introduce Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL. By distilling dense token-level teacher feedback from on-policy rollouts back into the MoE backbone, which activates only 3B parameters, Keye-VL-2.0 natively empowers advanced agent collaboration across Code, Tool, and Search scenarios with multimodal self-correction. Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate that Keye-VL-2.0-30B-A3B achieves state-of-the-art performance among models of similar scale, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench. We release our model checkpoints to accelerate community progress toward scalable and robust multimodal agentic applications.
VCap: Hypergeometric Rewards for Weak-to-Strong Visual Captioning
May 27, 2026Visual captioning requires models to capture visual content faithfully while minimizing both omission and hallucination. As the dominant paradigm for captioning, MLLMs have achieved strong performance through scaling and high-quality data. Recently, RL has emerged as a key route to driving MLLMs toward higher precision and broader coverage, however, existing reward designs for captioning fail to provide fine-grained and reliable signals for factual verification, limiting their effectiveness. To address this, we propose VCap, a Witness-Adjudicator reward that pairs the reference caption (a witness) with the visual signal (an adjudicator). By explicitly verifying factual consistency between the reference and policy-generated captions grounded in the visual signal, VCap delivers a reward signal with hypergeometric-distribution-level precision for caption quality verification. This design enables effective learning even from imperfect references, facilitating weak-to-strong generalization in RL training. In our experiments, an 8B model trained with VCap outperforms open- and closed-source SOTA models on multiple image and video captioning benchmarks. Human evaluation further confirms its strong alignment with factual correctness. Additionally, VCap improves MLLM perceptual capability, generalizes across tasks, and surpasses best-of-N distillation, challenging prior assumptions about RLVR.
ContextRL: Enhancing MLLM's Knowledge Discovery Efficiency with Context-Augmented RL
Feb 26, 2026We propose ContextRL, a novel framework that leverages context augmentation to overcome these bottlenecks. Specifically, to enhance Identifiability, we provide the reward model with full reference solutions as context, enabling fine-grained process verification to filter out false positives (samples with the right answer but low-quality reasoning process). To improve Reachability, we introduce a multi-turn sampling strategy where the reward model generates mistake reports for failed attempts, guiding the policy to "recover" correct responses from previously all-negative groups. Experimental results on 11 perception and reasoning benchmarks show that ContextRL significantly improves knowledge discovery efficiency. Notably, ContextRL enables the Qwen3-VL-8B model to achieve performance comparable to the 32B model, outperforming standard RLVR baselines by a large margin while effectively mitigating reward hacking. Our in-depth analysis reveals the significant potential of contextual information for improving reward model accuracy and document the widespread occurrence of reward hacking, offering valuable insights for future RLVR research.
UniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
VideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos
Feb 08, 2026In long-video understanding, conventional uniform frame sampling often fails to capture key visual evidence, leading to degraded performance and increased hallucinations. To address this, recent agentic thinking-with-videos paradigms have emerged, adopting a localize-clip-answer pipeline in which the model actively identifies relevant video segments, performs dense sampling within those clips, and then produces answers. However, existing methods remain inefficient, suffer from weak localization, and adhere to rigid workflows. To solve these issues, we propose VideoTemp-o3, a unified agentic thinking-with-videos framework that jointly models video grounding and question answering. VideoTemp-o3 exhibits strong localization capability, supports on-demand clipping, and can refine inaccurate localizations. Specifically, in the supervised fine-tuning stage, we design a unified masking mechanism that encourages exploration while preventing noise. For reinforcement learning, we introduce dedicated rewards to mitigate reward hacking. Besides, from the data perspective, we develop an effective pipeline to construct high-quality long video grounded QA data, along with a corresponding benchmark for systematic evaluation across various video durations. Experimental results demonstrate that our method achieves remarkable performance on both long video understanding and grounding.
SpatialReward: Bridging the Perception Gap in Online RL for Image Editing via Explicit Spatial Reasoning
Feb 07, 2026Online Reinforcement Learning (RL) offers a promising avenue for complex image editing but is currently constrained by the scarcity of reliable and fine-grained reward signals. Existing evaluators frequently struggle with a critical perception gap we term "Attention Collapse," where models neglect cross-image comparisons and fail to capture fine-grained details, resulting in inaccurate perception and miscalibrated scores. To address these limitations, we propose SpatialReward, a reward model that enforces precise verification via explicit spatial reasoning. By anchoring reasoning to predicted edit regions, SpatialReward grounds semantic judgments in pixel-level evidence, significantly enhancing evaluative accuracy. Trained on a curated 260k spatial-aware dataset, our model achieves state-of-the-art performance on MMRB2 and EditReward-Bench, and outperforms proprietary evaluators on our proposed MultiEditReward-Bench. Furthermore, SpatialReward serves as a robust signal in online RL, boosting OmniGen2 by +0.90 on GEdit-Bench--surpassing the leading discriminative model and doubling the gain of GPT-4.1 (+0.45). These results demonstrate that spatial reasoning is essential for unlocking effective alignment in image editing.
Joint Reward Modeling: Internalizing Chain-of-Thought for Efficient Visual Reward Models
Feb 07, 2026Reward models are critical for reinforcement learning from human feedback, as they determine the alignment quality and reliability of generative models. For complex tasks such as image editing, reward models are required to capture global semantic consistency and implicit logical constraints beyond local similarity. Existing reward modeling approaches have clear limitations. Discriminative reward models align well with human preferences but struggle with complex semantics due to limited reasoning supervision. Generative reward models offer stronger semantic understanding and reasoning, but they are costly at inference time and difficult to align directly with human preferences. To this end, we propose Joint Reward Modeling (JRM), which jointly optimizes preference learning and language modeling on a shared vision-language backbone. This approach internalizes the semantic and reasoning capabilities of generative models into efficient discriminative representations, enabling fast and accurate evaluation. JRM achieves state-of-the-art results on MMRB2 and EditReward-Bench, and significantly improves stability and performance in downstream online reinforcement learning. These results show that joint training effectively bridges efficiency and semantic understanding in reward modeling.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Why Distillation can Outperform Zero-RL: The Role of Flexible Reasoning
May 27, 2025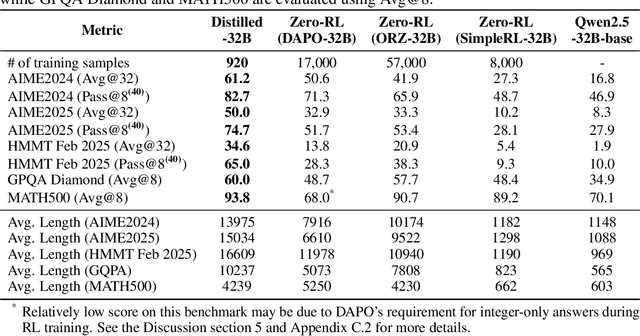
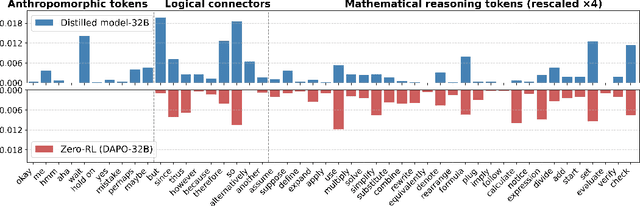

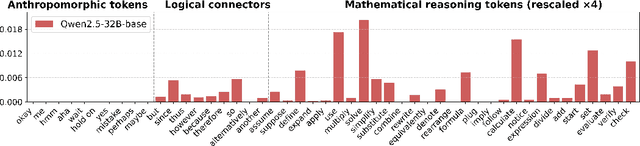
Reinforcement learning (RL) has played an important role in improving the reasoning ability of large language models (LLMs). Some studies apply RL directly to \textit{smaller} base models (known as zero-RL) and also achieve notable progress. However, in this paper, we show that using only 920 examples, a simple distillation method based on the base model can clearly outperform zero-RL, which typically requires much more data and computational cost. By analyzing the token frequency in model outputs, we find that the distilled model shows more flexible reasoning. It uses anthropomorphic tokens and logical connectors much more often than the zero-RL model. Further analysis reveals that distillation enhances the presence of two advanced cognitive behaviors: Multi-Perspective Thinking or Attempting and Metacognitive Awareness. Frequent occurrences of these two advanced cognitive behaviors give rise to flexible reasoning, which is essential for solving complex reasoning problems, while zero-RL fails to significantly boost the frequency of these behaviors.
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
May 05, 2025Multimodal Reward Models (MRMs) play a crucial role in enhancing the performance of Multimodal Large Language Models (MLLMs). While recent advancements have primarily focused on improving the model structure and training data of MRMs, there has been limited exploration into the effectiveness of long-term reasoning capabilities for reward modeling and how to activate these capabilities in MRMs. In this paper, we explore how Reinforcement Learning (RL) can be used to improve reward modeling. Specifically, we reformulate the reward modeling problem as a rule-based RL task. However, we observe that directly applying existing RL algorithms, such as Reinforce++, to reward modeling often leads to training instability or even collapse due to the inherent limitations of these algorithms. To address this issue, we propose the StableReinforce algorithm, which refines the training loss, advantage estimation strategy, and reward design of existing RL methods. These refinements result in more stable training dynamics and superior performance. To facilitate MRM training, we collect 200K preference data from diverse datasets. Our reward model, R1-Reward, trained using the StableReinforce algorithm on this dataset, significantly improves performance on multimodal reward modeling benchmarks. Compared to previous SOTA models, R1-Reward achieves a $8.4\%$ improvement on the VL Reward-Bench and a $14.3\%$ improvement on the Multimodal Reward Bench. Moreover, with more inference compute, R1-Reward's performance is further enhanced, highlighting the potential of RL algorithms in optimizing MRMs.