 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
Learning Robust Real-World Dexterous Grasping Policies via Implicit Shape Augmentation
Oct 24, 2022



Dexterous robotic hands have the capability to interact with a wide variety of household objects to perform tasks like grasping. However, learning robust real world grasping policies for arbitrary objects has proven challenging due to the difficulty of generating high quality training data. In this work, we propose a learning system (ISAGrasp) for leveraging a small number of human demonstrations to bootstrap the generation of a much larger dataset containing successful grasps on a variety of novel objects. Our key insight is to use a correspondence-aware implicit generative model to deform object meshes and demonstrated human grasps in order to generate a diverse dataset of novel objects and successful grasps for supervised learning, while maintaining semantic realism. We use this dataset to train a robust grasping policy in simulation which can be deployed in the real world. We demonstrate grasping performance with a four-fingered Allegro hand in both simulation and the real world, and show this method can handle entirely new semantic classes and achieve a 79% success rate on grasping unseen objects in the real world.
DexTransfer: Real World Multi-fingered Dexterous Grasping with Minimal Human Demonstrations
Sep 28, 2022

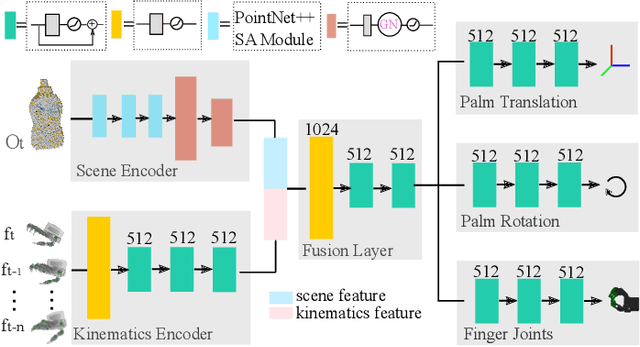
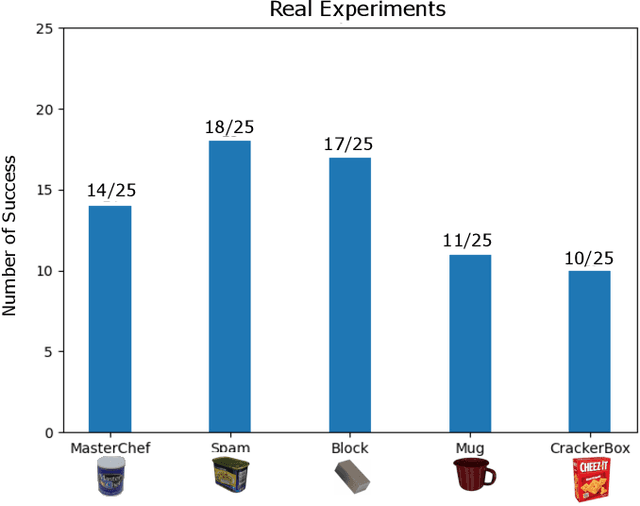
Teaching a multi-fingered dexterous robot to grasp objects in the real world has been a challenging problem due to its high dimensional state and action space. We propose a robot-learning system that can take a small number of human demonstrations and learn to grasp unseen object poses given partially occluded observations. Our system leverages a small motion capture dataset and generates a large dataset with diverse and successful trajectories for a multi-fingered robot gripper. By adding domain randomization, we show that our dataset provides robust grasping trajectories that can be transferred to a policy learner. We train a dexterous grasping policy that takes the point clouds of the object as input and predicts continuous actions to grasp objects from different initial robot states. We evaluate the effectiveness of our system on a 22-DoF floating Allegro Hand in simulation and a 23-DoF Allegro robot hand with a KUKA arm in real world. The policy learned from our dataset can generalize well on unseen object poses in both simulation and the real world
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022
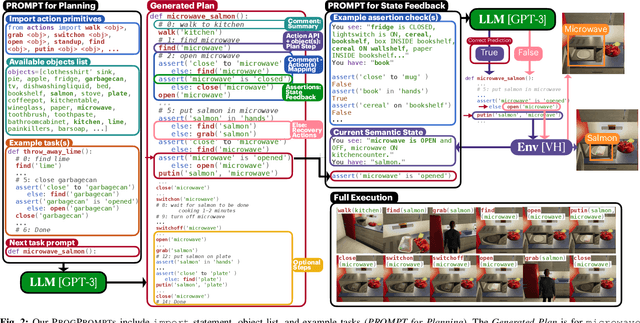


Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io
Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Sep 12, 2022
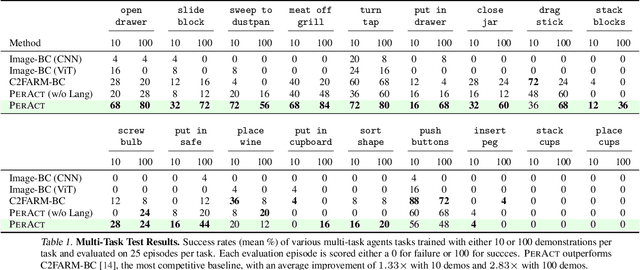
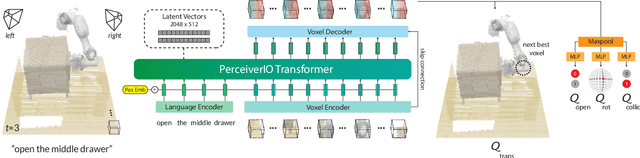
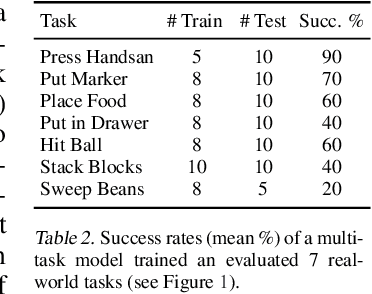
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can we still benefit from Transformers with the right problem formulation? We investigate this question with PerAct, a language-conditioned behavior-cloning agent for multi-task 6-DoF manipulation. PerAct encodes language goals and RGB-D voxel observations with a Perceiver Transformer, and outputs discretized actions by "detecting the next best voxel action". Unlike frameworks that operate on 2D images, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF policies. With this formulation, we train a single multi-task Transformer for 18 RLBench tasks (with 249 variations) and 7 real-world tasks (with 18 variations) from just a few demonstrations per task. Our results show that PerAct significantly outperforms unstructured image-to-action agents and 3D ConvNet baselines for a wide range of tabletop tasks.
Break and Make: Interactive Structural Understanding Using LEGO Bricks
Jul 27, 2022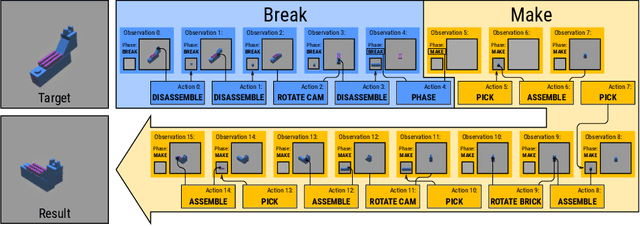
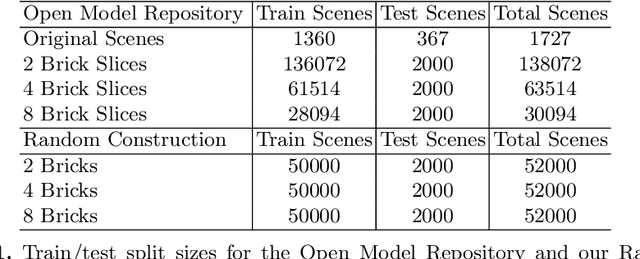
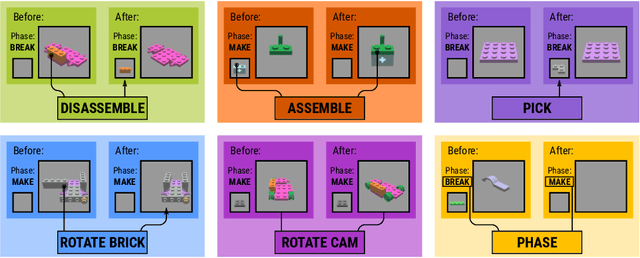
Visual understanding of geometric structures with complex spatial relationships is a fundamental component of human intelligence. As children, we learn how to reason about structure not only from observation, but also by interacting with the world around us -- by taking things apart and putting them back together again. The ability to reason about structure and compositionality allows us to not only build things, but also understand and reverse-engineer complex systems. In order to advance research in interactive reasoning for part-based geometric understanding, we propose a challenging new assembly problem using LEGO bricks that we call Break and Make. In this problem an agent is given a LEGO model and attempts to understand its structure by interactively inspecting and disassembling it. After this inspection period, the agent must then prove its understanding by rebuilding the model from scratch using low-level action primitives. In order to facilitate research on this problem we have built LTRON, a fully interactive 3D simulator that allows learning agents to assemble, disassemble and manipulate LEGO models. We pair this simulator with a new dataset of fan-made LEGO creations that have been uploaded to the internet in order to provide complex scenes containing over a thousand unique brick shapes. We take a first step towards solving this problem using sequence-to-sequence models that provide guidance for how to make progress on this challenging problem. Our simulator and data are available at github.com/aaronwalsman/ltron. Additional training code and PyTorch examples are available at github.com/aaronwalsman/ltron-torch-eccv22.
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


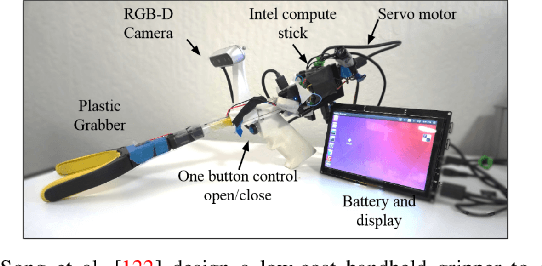
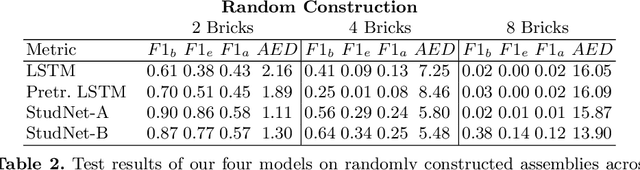
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Neural Motion Fields: Encoding Grasp Trajectories as Implicit Value Functions
Jun 29, 2022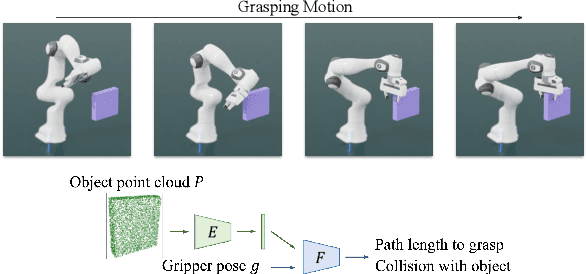


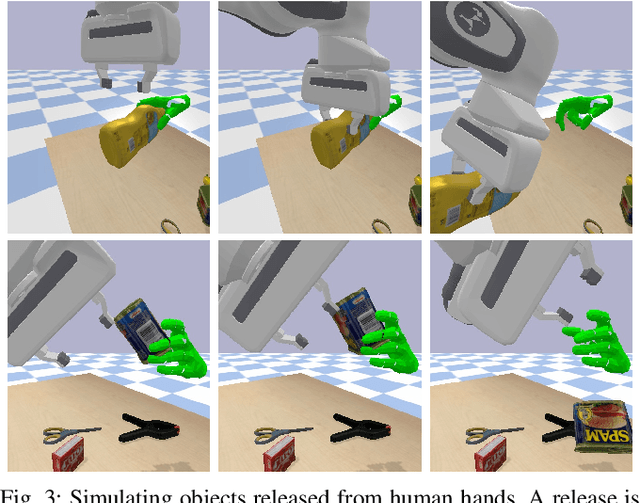
The pipeline of current robotic pick-and-place methods typically consists of several stages: grasp pose detection, finding inverse kinematic solutions for the detected poses, planning a collision-free trajectory, and then executing the open-loop trajectory to the grasp pose with a low-level tracking controller. While these grasping methods have shown good performance on grasping static objects on a table-top, the problem of grasping dynamic objects in constrained environments remains an open problem. We present Neural Motion Fields, a novel object representation which encodes both object point clouds and the relative task trajectories as an implicit value function parameterized by a neural network. This object-centric representation models a continuous distribution over the SE(3) space and allows us to perform grasping reactively by leveraging sampling-based MPC to optimize this value function.
HandoverSim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers
May 19, 2022


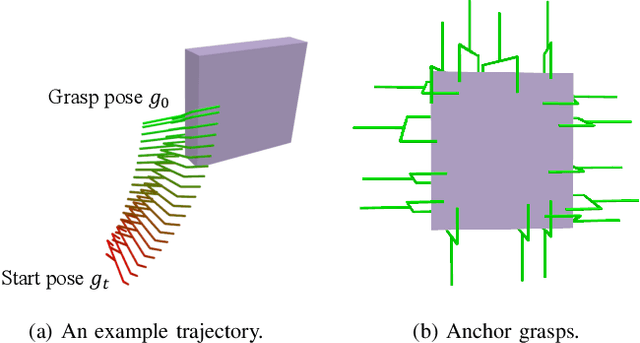
We introduce a new simulation benchmark "HandoverSim" for human-to-robot object handovers. To simulate the giver's motion, we leverage a recent motion capture dataset of hand grasping of objects. We create training and evaluation environments for the receiver with standardized protocols and metrics. We analyze the performance of a set of baselines and show a correlation with a real-world evaluation. Code is open sourced at https://handover-sim.github.io.
Factory: Fast Contact for Robotic Assembly
May 07, 2022
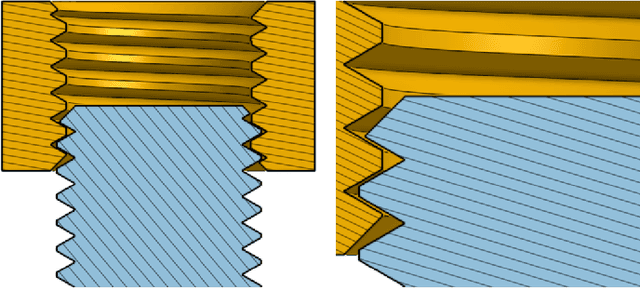


Robotic assembly is one of the oldest and most challenging applications of robotics. In other areas of robotics, such as perception and grasping, simulation has rapidly accelerated research progress, particularly when combined with modern deep learning. However, accurately, efficiently, and robustly simulating the range of contact-rich interactions in assembly remains a longstanding challenge. In this work, we present Factory, a set of physics simulation methods and robot learning tools for such applications. We achieve real-time or faster simulation of a wide range of contact-rich scenes, including simultaneous simulation of 1000 nut-and-bolt interactions. We provide $60$ carefully-designed part models, 3 robotic assembly environments, and 7 robot controllers for training and testing virtual robots. Finally, we train and evaluate proof-of-concept reinforcement learning policies for nut-and-bolt assembly. We aim for Factory to open the doors to using simulation for robotic assembly, as well as many other contact-rich applications in robotics. Please see https://sites.google.com/nvidia.com/factory for supplementary content, including videos.