 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Continuum Robot Shape and External Load State Estimation on SE(3)
Jan 08, 2026Previous on-manifold approaches to continuum robot state estimation have typically adopted simplified Cosserat rod models, which cannot directly account for actuation inputs or external loads. We introduce a general framework that incorporates uncertainty models for actuation (e.g., tendon tensions), applied forces and moments, process noise, boundary conditions, and arbitrary backbone measurements. By adding temporal priors across time steps, our method additionally performs joint estimation in both the spatial (arclength) and temporal domains, enabling full \textit{spacetime} state estimation. Discretizing the arclength domain yields a factor graph representation of the continuum robot model, which can be exploited for fast batch sparse nonlinear optimization in the style of SLAM. The framework is general and applies to a broad class of continuum robots; as illustrative cases, we show (i) tendon-driven robots in simulation, where we demonstrate real-time kinematics with uncertainty, tip force sensing from position feedback, and distributed load estimation from backbone strain, and (ii) a surgical concentric tube robot in experiment, where we validate accurate kinematics and tip force estimation, highlighting potential for surgical palpation.
The Reality Gap in Robotics: Challenges, Solutions, and Best Practices
Oct 23, 2025Machine learning has facilitated significant advancements across various robotics domains, including navigation, locomotion, and manipulation. Many such achievements have been driven by the extensive use of simulation as a critical tool for training and testing robotic systems prior to their deployment in real-world environments. However, simulations consist of abstractions and approximations that inevitably introduce discrepancies between simulated and real environments, known as the reality gap. These discrepancies significantly hinder the successful transfer of systems from simulation to the real world. Closing this gap remains one of the most pressing challenges in robotics. Recent advances in sim-to-real transfer have demonstrated promising results across various platforms, including locomotion, navigation, and manipulation. By leveraging techniques such as domain randomization, real-to-sim transfer, state and action abstractions, and sim-real co-training, many works have overcome the reality gap. However, challenges persist, and a deeper understanding of the reality gap's root causes and solutions is necessary. In this survey, we present a comprehensive overview of the sim-to-real landscape, highlighting the causes, solutions, and evaluation metrics for the reality gap and sim-to-real transfer.
First Plan Then Evaluate: Use a Vectorized Motion Planner for Grasping
Sep 08, 2025Autonomous multi-finger grasping is a fundamental capability in robotic manipulation. Optimization-based approaches show strong performance, but tend to be sensitive to initialization and are potentially time-consuming. As an alternative, the generator-evaluator-planner framework has been proposed. A generator generates grasp candidates, an evaluator ranks the proposed grasps, and a motion planner plans a trajectory to the highest-ranked grasp. If the planner doesn't find a trajectory, a new trajectory optimization is started with the next-best grasp as the target and so on. However, executing lower-ranked grasps means a lower chance of grasp success, and multiple trajectory optimizations are time-consuming. Alternatively, relaxing the threshold for motion planning accuracy allows for easier computation of a successful trajectory but implies lower accuracy in estimating grasp success likelihood. It's a lose-lose proposition: either spend more time finding a successful trajectory or have a worse estimate of grasp success. We propose a framework that plans trajectories to a set of generated grasp targets in parallel, the evaluator estimates the grasp success likelihood of the resulting trajectories, and the robot executes the trajectory most likely to succeed. To plan trajectories to different targets efficiently, we propose the use of a vectorized motion planner. Our experiments show our approach improves over the traditional generator-evaluator-planner framework across different objects, generators, and motion planners, and successfully generalizes to novel environments in the real world, including different shelves and table heights. Project website https://sites.google.com/view/fpte
DefFusionNet: Learning Multimodal Goal Shapes for Deformable Object Manipulation via a Diffusion-based Probabilistic Model
Jun 23, 2025Deformable object manipulation is critical to many real-world robotic applications, ranging from surgical robotics and soft material handling in manufacturing to household tasks like laundry folding. At the core of this important robotic field is shape servoing, a task focused on controlling deformable objects into desired shapes. The shape servoing formulation requires the specification of a goal shape. However, most prior works in shape servoing rely on impractical goal shape acquisition methods, such as laborious domain-knowledge engineering or manual manipulation. DefGoalNet previously posed the current state-of-the-art solution to this problem, which learns deformable object goal shapes directly from a small number of human demonstrations. However, it significantly struggles in multi-modal settings, where multiple distinct goal shapes can all lead to successful task completion. As a deterministic model, DefGoalNet collapses these possibilities into a single averaged solution, often resulting in an unusable goal. In this paper, we address this problem by developing DefFusionNet, a novel neural network that leverages the diffusion probabilistic model to learn a distribution over all valid goal shapes rather than predicting a single deterministic outcome. This enables the generation of diverse goal shapes and avoids the averaging artifacts. We demonstrate our method's effectiveness on robotic tasks inspired by both manufacturing and surgical applications, both in simulation and on a physical robot. Our work is the first generative model capable of producing a diverse, multi-modal set of deformable object goals for real-world robotic applications.
Robust Bayesian Scene Reconstruction by Leveraging Retrieval-Augmented Priors
Nov 29, 2024



Constructing 3D representations of object geometry is critical for many downstream manipulation tasks. These representations must be built from potentially noisy partial observations. In this work we focus on the problem of reconstructing a multi-object scene from a single RGBD image. Current deep learning approaches to this problem can be brittle to noisy real world observations and out-of-distribution objects. Other approaches that do not rely on training data cannot accurately infer the backside of objects. We propose BRRP, a reconstruction method that can leverage preexisting mesh datasets to build an informative prior during robust probabilistic reconstruction. In order to make our method more efficient, we introduce the concept of retrieval-augmented prior, where we retrieve relevant components of our prior distribution during inference. Our method produces a distribution over object shape that can be used for reconstruction or measuring uncertainty. We evaluate our method in both procedurally generated scenes and in real world scenes. We show our method is more robust than a deep learning approach while being more accurate than a method with an uninformative prior.
23 DoF Grasping Policies from a Raw Point Cloud
Nov 21, 2024
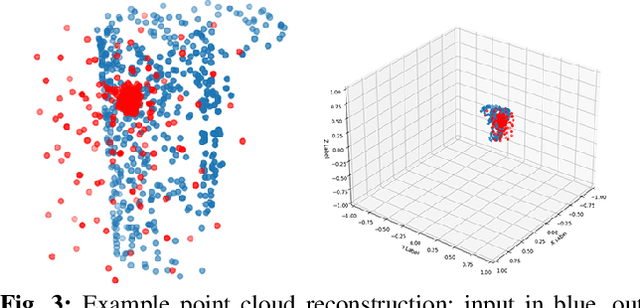
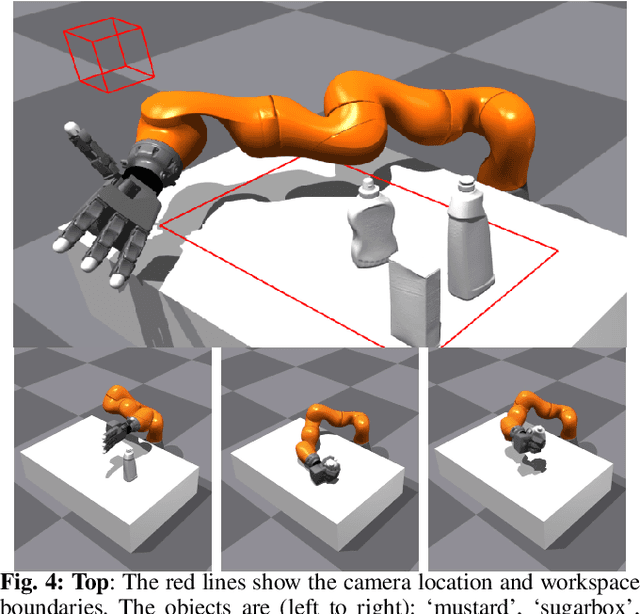
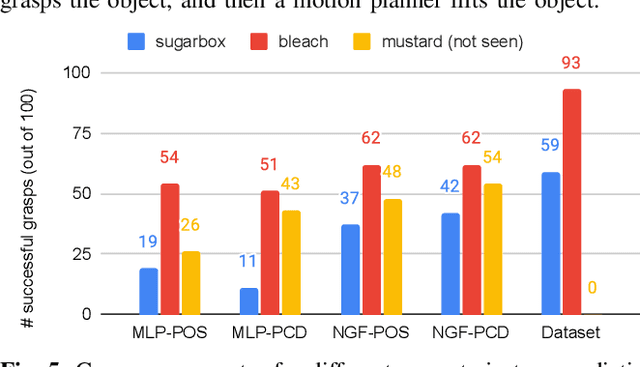
Coordinating the motion of robots with high degrees of freedom (DoF) to grasp objects gives rise to many challenges. In this paper, we propose a novel imitation learning approach to learn a policy that directly predicts 23 DoF grasp trajectories from a partial point cloud provided by a single, fixed camera. At the core of the approach is a second-order geometric-based model of behavioral dynamics. This Neural Geometric Fabric (NGF) policy predicts accelerations directly in joint space. We show that our policy is capable of generalizing to novel objects, and combine our policy with a geometric fabric motion planner in a loop to generate stable grasping trajectories. We evaluate our approach on a set of three different objects, compare different policy structures, and run ablation studies to understand the importance of different object encodings for policy learning.
Differentiable GPU-Parallelized Task and Motion Planning
Nov 18, 2024


We present a differentiable optimization-based framework for Task and Motion Planning (TAMP) that is massively parallelizable on GPUs, enabling thousands of sampled seeds to be optimized simultaneously. Existing sampling-based approaches inherently disconnect the parameters by generating samples for each independently and combining them through composition and rejection, while optimization-based methods struggle with highly non-convex constraints and local optima. Our method treats TAMP constraint satisfaction as optimizing a batch of particles, each representing an assignment to a plan skeleton's continuous parameters. We represent the plan skeleton's constraints using differentiable cost functions, enabling us to compute the gradient of each particle and update it toward satisfying solutions. Our use of GPU parallelism better covers the parameter space through scale, increasing the likelihood of finding the global optima by exploring multiple basins through global sampling. We demonstrate that our algorithm can effectively solve a highly constrained Tetris packing problem using a Franka arm in simulation and deploy our planner on a real robot arm. Website: https://williamshen-nz.github.io/gpu-tamp
Points2Plans: From Point Clouds to Long-Horizon Plans with Composable Relational Dynamics
Aug 27, 2024We present Points2Plans, a framework for composable planning with a relational dynamics model that enables robots to solve long-horizon manipulation tasks from partial-view point clouds. Given a language instruction and a point cloud of the scene, our framework initiates a hierarchical planning procedure, whereby a language model generates a high-level plan and a sampling-based planner produces constraint-satisfying continuous parameters for manipulation primitives sequenced according to the high-level plan. Key to our approach is the use of a relational dynamics model as a unifying interface between the continuous and symbolic representations of states and actions, thus facilitating language-driven planning from high-dimensional perceptual input such as point clouds. Whereas previous relational dynamics models require training on datasets of multi-step manipulation scenarios that align with the intended test scenarios, Points2Plans uses only single-step simulated training data while generalizing zero-shot to a variable number of steps during real-world evaluations. We evaluate our approach on tasks involving geometric reasoning, multi-object interactions, and occluded object reasoning in both simulated and real-world settings. Results demonstrate that Points2Plans offers strong generalization to unseen long-horizon tasks in the real world, where it solves over 85% of evaluated tasks while the next best baseline solves only 50%. Qualitative demonstrations of our approach operating on a mobile manipulator platform are made available at sites.google.com/stanford.edu/points2plans.
DextrAH-G: Pixels-to-Action Dexterous Arm-Hand Grasping with Geometric Fabrics
Jul 02, 2024



A pivotal challenge in robotics is achieving fast, safe, and robust dexterous grasping across a diverse range of objects, an important goal within industrial applications. However, existing methods often have very limited speed, dexterity, and generality, along with limited or no hardware safety guarantees. In this work, we introduce DextrAH-G, a depth-based dexterous grasping policy trained entirely in simulation that combines reinforcement learning, geometric fabrics, and teacher-student distillation. We address key challenges in joint arm-hand policy learning, such as high-dimensional observation and action spaces, the sim2real gap, collision avoidance, and hardware constraints. DextrAH-G enables a 23 motor arm-hand robot to safely and continuously grasp and transport a large variety of objects at high speed using multi-modal inputs including depth images, allowing generalization across object geometry. Videos at https://sites.google.com/view/dextrah-g.
Composable Part-Based Manipulation
May 09, 2024



In this paper, we propose composable part-based manipulation (CPM), a novel approach that leverages object-part decomposition and part-part correspondences to improve learning and generalization of robotic manipulation skills. By considering the functional correspondences between object parts, we conceptualize functional actions, such as pouring and constrained placing, as combinations of different correspondence constraints. CPM comprises a collection of composable diffusion models, where each model captures a different inter-object correspondence. These diffusion models can generate parameters for manipulation skills based on the specific object parts. Leveraging part-based correspondences coupled with the task decomposition into distinct constraints enables strong generalization to novel objects and object categories. We validate our approach in both simulated and real-world scenarios, demonstrating its effectiveness in achieving robust and generalized manipulation capabilities.