 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistive Tele-op: Leveraging Transformers to Collect Robotic Task Demonstrations
Dec 09, 2021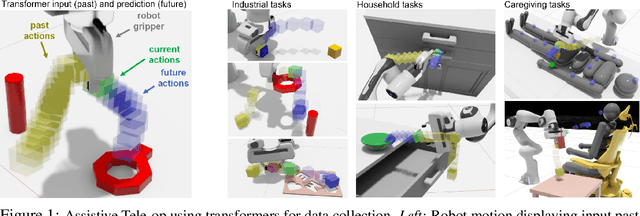
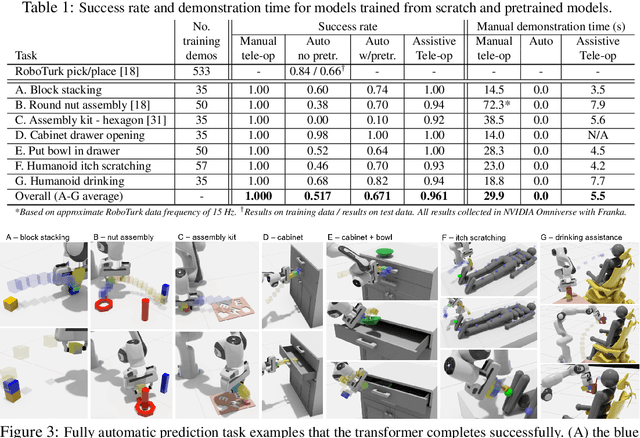
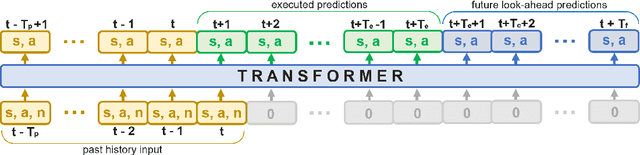
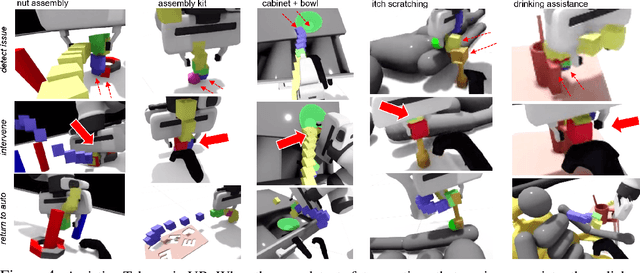
Sharing autonomy between robots and human operators could facilitate data collection of robotic task demonstrations to continuously improve learned models. Yet, the means to communicate intent and reason about the future are disparate between humans and robots. We present Assistive Tele-op, a virtual reality (VR) system for collecting robot task demonstrations that displays an autonomous trajectory forecast to communicate the robot's intent. As the robot moves, the user can switch between autonomous and manual control when desired. This allows users to collect task demonstrations with both a high success rate and with greater ease than manual teleoperation systems. Our system is powered by transformers, which can provide a window of potential states and actions far into the future -- with almost no added computation time. A key insight is that human intent can be injected at any location within the transformer sequence if the user decides that the model-predicted actions are inappropriate. At every time step, the user can (1) do nothing and allow autonomous operation to continue while observing the robot's future plan sequence, or (2) take over and momentarily prescribe a different set of actions to nudge the model back on track. We host the videos and other supplementary material at https://sites.google.com/view/assistive-teleop.
A Bayesian Treatment of Real-to-Sim for Deformable Object Manipulation
Dec 09, 2021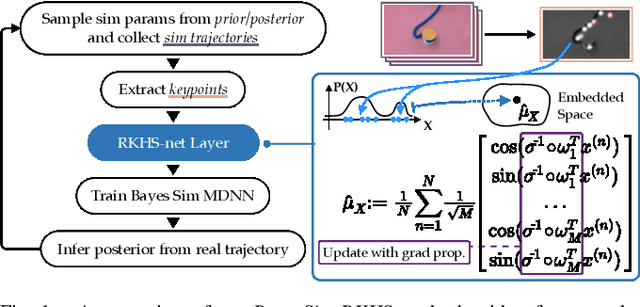


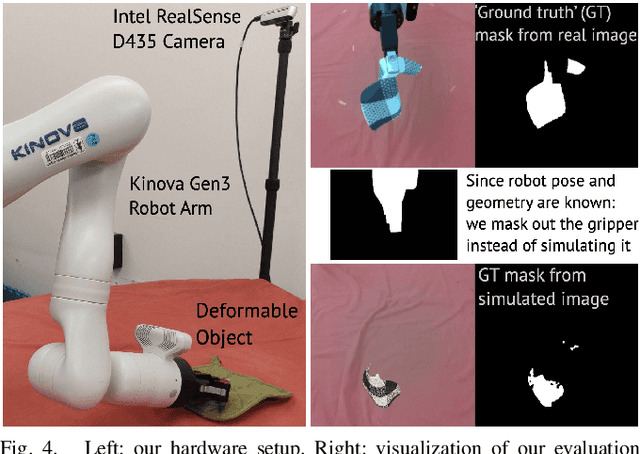
Deformable object manipulation remains a challenging task in robotics research. Conventional techniques for parameter inference and state estimation typically rely on a precise definition of the state space and its dynamics. While this is appropriate for rigid objects and robot states, it is challenging to define the state space of a deformable object and how it evolves in time. In this work, we pose the problem of inferring physical parameters of deformable objects as a probabilistic inference task defined with a simulator. We propose a novel methodology for extracting state information from image sequences via a technique to represent the state of a deformable object as a distribution embedding. This allows to incorporate noisy state observations directly into modern Bayesian simulation-based inference tools in a principled manner. Our experiments confirm that we can estimate posterior distributions of physical properties, such as elasticity, friction and scale of highly deformable objects, such as cloth and ropes. Overall, our method addresses the real-to-sim problem probabilistically and helps to better represent the evolution of the state of deformable objects.
Learning Perceptual Concepts by Bootstrapping from Human Queries
Nov 09, 2021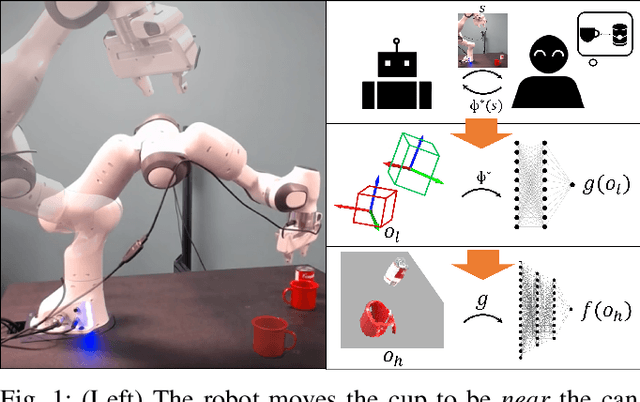
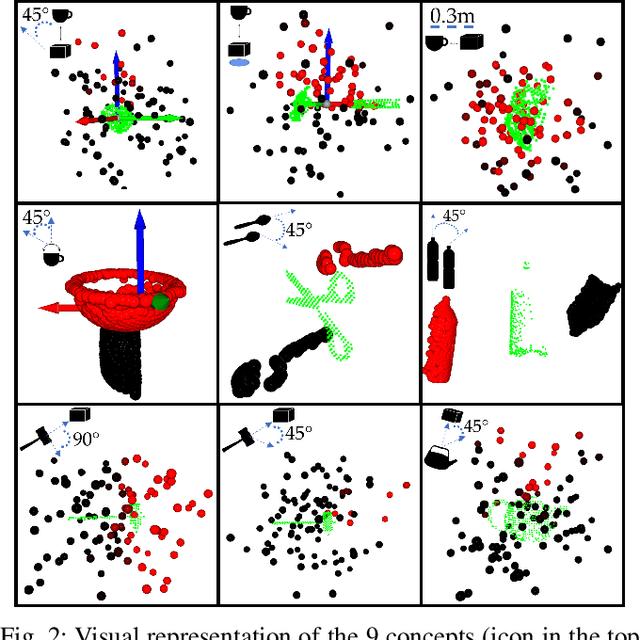
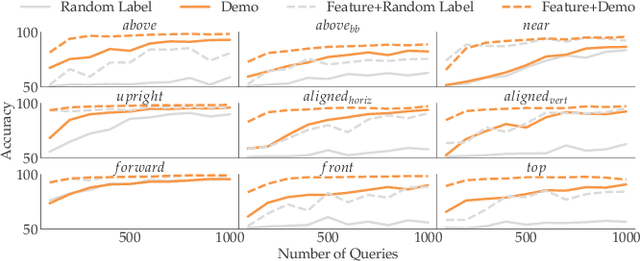
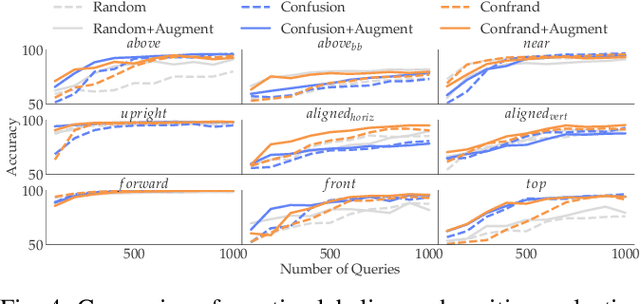
Robots need to be able to learn concepts from their users in order to adapt their capabilities to each user's unique task. But when the robot operates on high-dimensional inputs, like images or point clouds, this is impractical: the robot needs an unrealistic amount of human effort to learn the new concept. To address this challenge, we propose a new approach whereby the robot learns a low-dimensional variant of the concept and uses it to generate a larger data set for learning the concept in the high-dimensional space. This lets it take advantage of semantically meaningful privileged information only accessible at training time, like object poses and bounding boxes, that allows for richer human interaction to speed up learning. We evaluate our approach by learning prepositional concepts that describe object state or multi-object relationships, like above, near, or aligned, which are key to user specification of task goals and execution constraints for robots. Using a simulated human, we show that our approach improves sample complexity when compared to learning concepts directly in the high-dimensional space. We also demonstrate the utility of the learned concepts in motion planning tasks on a 7-DoF Franka Panda robot.
From Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence
Oct 28, 2021
Machine learning has long since become a keystone technology, accelerating science and applications in a broad range of domains. Consequently, the notion of applying learning methods to a particular problem set has become an established and valuable modus operandi to advance a particular field. In this article we argue that such an approach does not straightforwardly extended to robotics -- or to embodied intelligence more generally: systems which engage in a purposeful exchange of energy and information with a physical environment. In particular, the purview of embodied intelligent agents extends significantly beyond the typical considerations of main-stream machine learning approaches, which typically (i) do not consider operation under conditions significantly different from those encountered during training; (ii) do not consider the often substantial, long-lasting and potentially safety-critical nature of interactions during learning and deployment; (iii) do not require ready adaptation to novel tasks while at the same time (iv) effectively and efficiently curating and extending their models of the world through targeted and deliberate actions. In reality, therefore, these limitations result in learning-based systems which suffer from many of the same operational shortcomings as more traditional, engineering-based approaches when deployed on a robot outside a well defined, and often narrow operating envelope. Contrary to viewing embodied intelligence as another application domain for machine learning, here we argue that it is in fact a key driver for the advancement of machine learning technology. In this article our goal is to highlight challenges and opportunities that are specific to embodied intelligence and to propose research directions which may significantly advance the state-of-the-art in robot learning.
StructFormer: Learning Spatial Structure for Language-Guided Semantic Rearrangement of Novel Objects
Oct 19, 2021
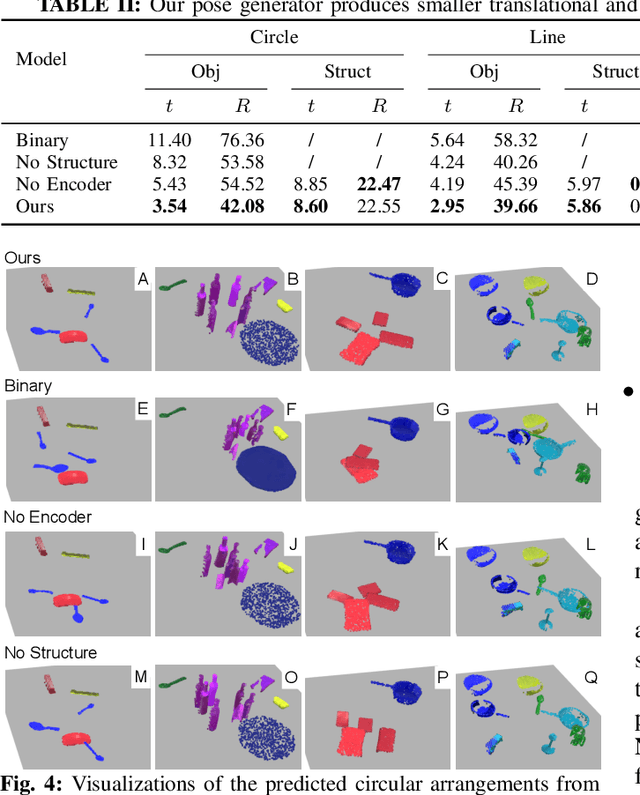
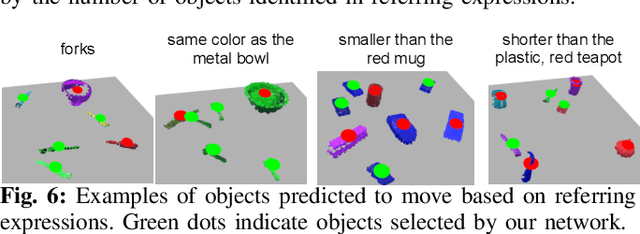
Geometric organization of objects into semantically meaningful arrangements pervades the built world. As such, assistive robots operating in warehouses, offices, and homes would greatly benefit from the ability to recognize and rearrange objects into these semantically meaningful structures. To be useful, these robots must contend with previously unseen objects and receive instructions without significant programming. While previous works have examined recognizing pairwise semantic relations and sequential manipulation to change these simple relations none have shown the ability to arrange objects into complex structures such as circles or table settings. To address this problem we propose a novel transformer-based neural network, StructFormer, which takes as input a partial-view point cloud of the current object arrangement and a structured language command encoding the desired object configuration. We show through rigorous experiments that StructFormer enables a physical robot to rearrange novel objects into semantically meaningful structures with multi-object relational constraints inferred from the language command.
Continuous-Time Fitted Value Iteration for Robust Policies
Oct 05, 2021
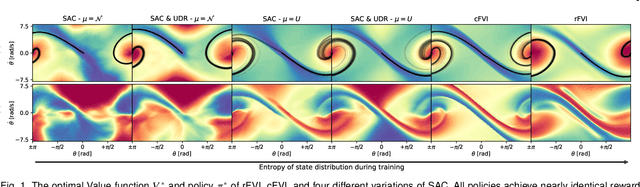


Solving the Hamilton-Jacobi-Bellman equation is important in many domains including control, robotics and economics. Especially for continuous control, solving this differential equation and its extension the Hamilton-Jacobi-Isaacs equation, is important as it yields the optimal policy that achieves the maximum reward on a give task. In the case of the Hamilton-Jacobi-Isaacs equation, which includes an adversary controlling the environment and minimizing the reward, the obtained policy is also robust to perturbations of the dynamics. In this paper we propose continuous fitted value iteration (cFVI) and robust fitted value iteration (rFVI). These algorithms leverage the non-linear control-affine dynamics and separable state and action reward of many continuous control problems to derive the optimal policy and optimal adversary in closed form. This analytic expression simplifies the differential equations and enables us to solve for the optimal value function using value iteration for continuous actions and states as well as the adversarial case. Notably, the resulting algorithms do not require discretization of states or actions. We apply the resulting algorithms to the Furuta pendulum and cartpole. We show that both algorithms obtain the optimal policy. The robustness Sim2Real experiments on the physical systems show that the policies successfully achieve the task in the real-world. When changing the masses of the pendulum, we observe that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi
CLIPort: What and Where Pathways for Robotic Manipulation
Sep 24, 2021
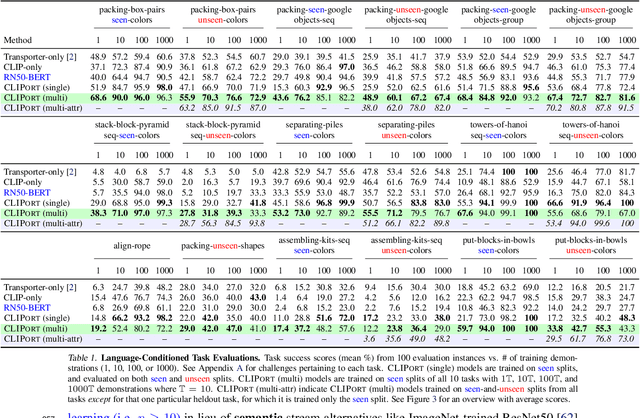
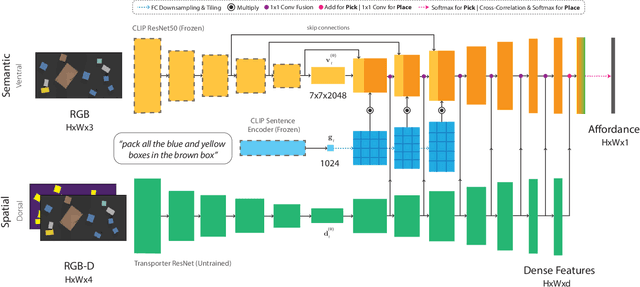
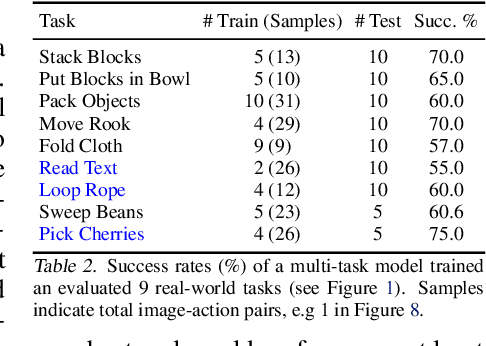
How can we imbue robots with the ability to manipulate objects precisely but also to reason about them in terms of abstract concepts? Recent works in manipulation have shown that end-to-end networks can learn dexterous skills that require precise spatial reasoning, but these methods often fail to generalize to new goals or quickly learn transferable concepts across tasks. In parallel, there has been great progress in learning generalizable semantic representations for vision and language by training on large-scale internet data, however these representations lack the spatial understanding necessary for fine-grained manipulation. To this end, we propose a framework that combines the best of both worlds: a two-stream architecture with semantic and spatial pathways for vision-based manipulation. Specifically, we present CLIPort, a language-conditioned imitation-learning agent that combines the broad semantic understanding (what) of CLIP [1] with the spatial precision (where) of Transporter [2]. Our end-to-end framework is capable of solving a variety of language-specified tabletop tasks from packing unseen objects to folding cloths, all without any explicit representations of object poses, instance segmentations, memory, symbolic states, or syntactic structures. Experiments in simulated and real-world settings show that our approach is data efficient in few-shot settings and generalizes effectively to seen and unseen semantic concepts. We even learn one multi-task policy for 10 simulated and 9 real-world tasks that is better or comparable to single-task policies.
Geometric Fabrics: Generalizing Classical Mechanics to Capture the Physics of Behavior
Sep 21, 2021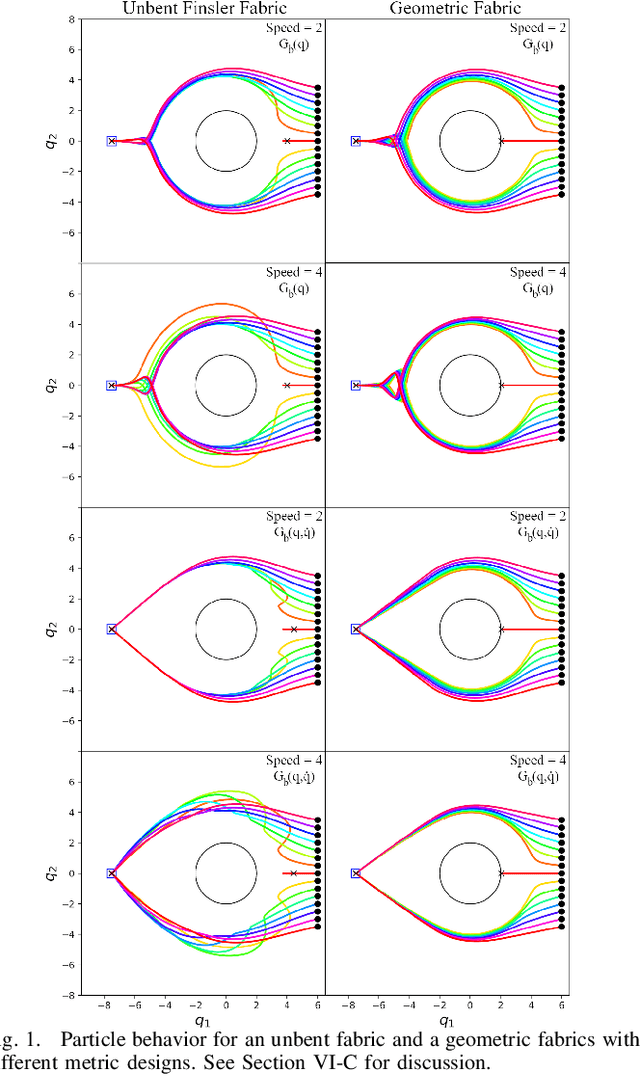
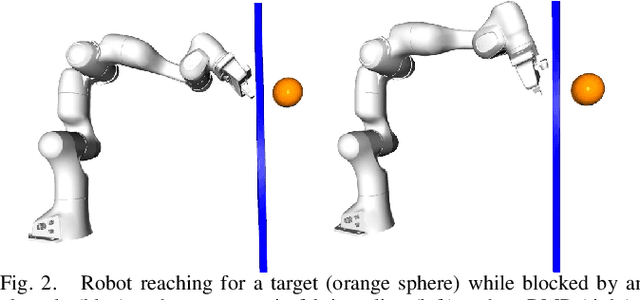
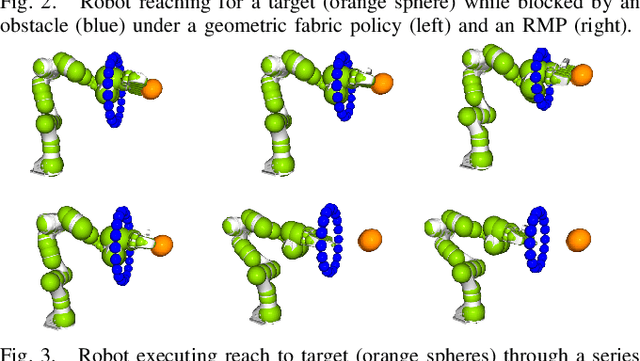
Classical mechanical systems are central to controller design in energy shaping methods of geometric control. However, their expressivity is limited by position-only metrics and the intimate link between metric and geometry. Recent work on Riemannian Motion Policies (RMPs) has shown that shedding these restrictions results in powerful design tools, but at the expense of theoretical guarantees. In this work, we generalize classical mechanics to what we call geometric fabrics, whose expressivity and theory enable the design of systems that outperform RMPs in practice. Geometric fabrics strictly generalize classical mechanics forming a new physics of behavior by first generalizing them to Finsler geometries and then explicitly bending them to shape their behavior. We develop the theory of fabrics and present both a collection of controlled experiments examining their theoretical properties and a set of robot system experiments showing improved performance over a well-engineered and hardened implementation of RMPs, our current state-of-the-art in controller design.
SORNet: Spatial Object-Centric Representations for Sequential Manipulation
Sep 08, 2021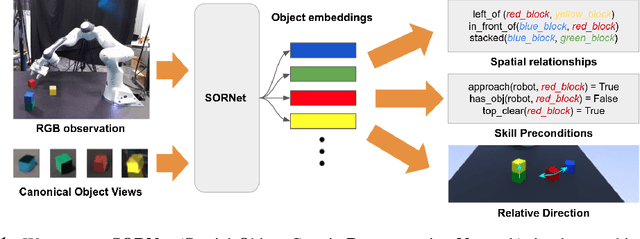

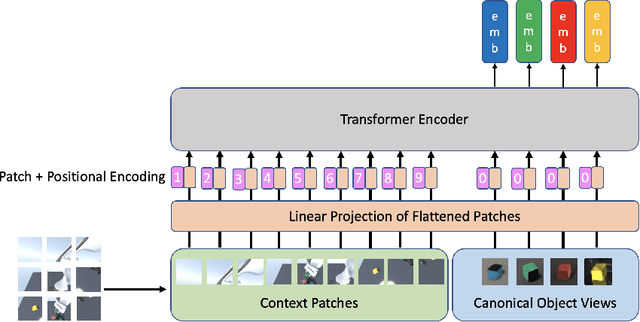
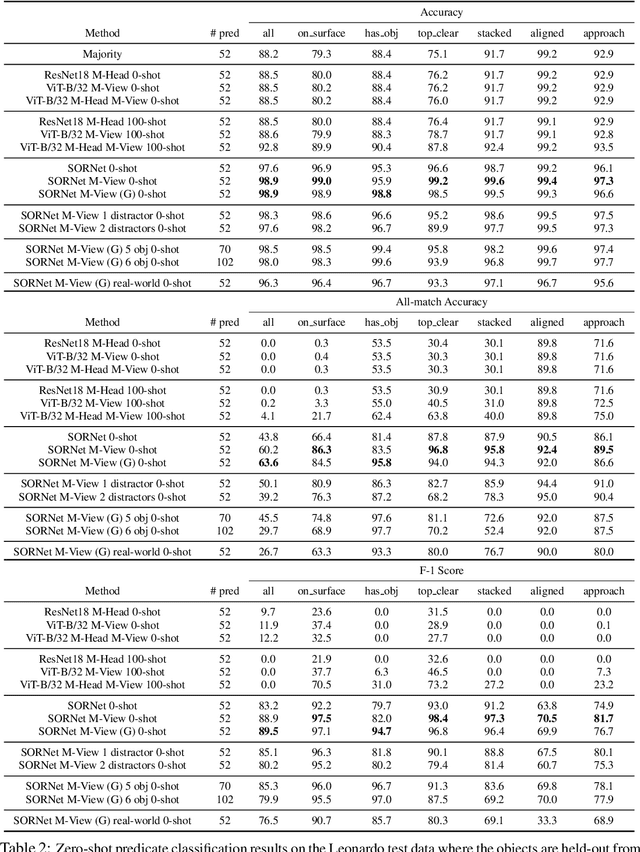
Sequential manipulation tasks require a robot to perceive the state of an environment and plan a sequence of actions leading to a desired goal state, where the ability to reason about spatial relationships among object entities from raw sensor inputs is crucial. Prior works relying on explicit state estimation or end-to-end learning struggle with novel objects. In this work, we propose SORNet (Spatial Object-Centric Representation Network), which extracts object-centric representations from RGB images conditioned on canonical views of the objects of interest. We show that the object embeddings learned by SORNet generalize zero-shot to unseen object entities on three spatial reasoning tasks: spatial relationship classification, skill precondition classification and relative direction regression, significantly outperforming baselines. Further, we present real-world robotic experiments demonstrating the usage of the learned object embeddings in task planning for sequential manipulation.
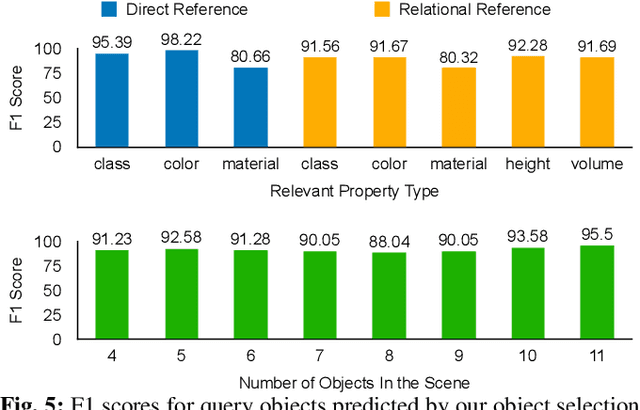
Predicting Stable Configurations for Semantic Placement of Novel Objects
Aug 26, 2021
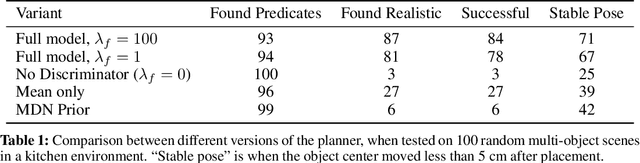
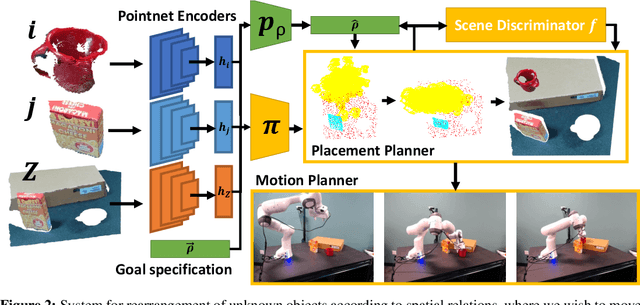
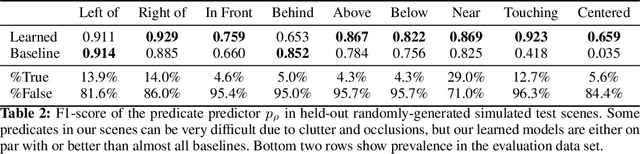
Human environments contain numerous objects configured in a variety of arrangements. Our goal is to enable robots to repose previously unseen objects according to learned semantic relationships in novel environments. We break this problem down into two parts: (1) finding physically valid locations for the objects and (2) determining if those poses satisfy learned, high-level semantic relationships. We build our models and training from the ground up to be tightly integrated with our proposed planning algorithm for semantic placement of unknown objects. We train our models purely in simulation, with no fine-tuning needed for use in the real world. Our approach enables motion planning for semantic rearrangement of unknown objects in scenes with varying geometry from only RGB-D sensing. Our experiments through a set of simulated ablations demonstrate that using a relational classifier alone is not sufficient for reliable planning. We further demonstrate the ability of our planner to generate and execute diverse manipulation plans through a set of real-world experiments with a variety of objects.