 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisruptive Autoencoders: Leveraging Low-level features for 3D Medical Image Pre-training
Jul 31, 2023Harnessing the power of pre-training on large-scale datasets like ImageNet forms a fundamental building block for the progress of representation learning-driven solutions in computer vision. Medical images are inherently different from natural images as they are acquired in the form of many modalities (CT, MR, PET, Ultrasound etc.) and contain granulated information like tissue, lesion, organs etc. These characteristics of medical images require special attention towards learning features representative of local context. In this work, we focus on designing an effective pre-training framework for 3D radiology images. First, we propose a new masking strategy called local masking where the masking is performed across channel embeddings instead of tokens to improve the learning of local feature representations. We combine this with classical low-level perturbations like adding noise and downsampling to further enable low-level representation learning. To this end, we introduce Disruptive Autoencoders, a pre-training framework that attempts to reconstruct the original image from disruptions created by a combination of local masking and low-level perturbations. Additionally, we also devise a cross-modal contrastive loss (CMCL) to accommodate the pre-training of multiple modalities in a single framework. We curate a large-scale dataset to enable pre-training of 3D medical radiology images (MRI and CT). The proposed pre-training framework is tested across multiple downstream tasks and achieves state-of-the-art performance. Notably, our proposed method tops the public test leaderboard of BTCV multi-organ segmentation challenge.
DeepEdit: Deep Editable Learning for Interactive Segmentation of 3D Medical Images
May 18, 2023Automatic segmentation of medical images is a key step for diagnostic and interventional tasks. However, achieving this requires large amounts of annotated volumes, which can be tedious and time-consuming task for expert annotators. In this paper, we introduce DeepEdit, a deep learning-based method for volumetric medical image annotation, that allows automatic and semi-automatic segmentation, and click-based refinement. DeepEdit combines the power of two methods: a non-interactive (i.e. automatic segmentation using nnU-Net, UNET or UNETR) and an interactive segmentation method (i.e. DeepGrow), into a single deep learning model. It allows easy integration of uncertainty-based ranking strategies (i.e. aleatoric and epistemic uncertainty computation) and active learning. We propose and implement a method for training DeepEdit by using standard training combined with user interaction simulation. Once trained, DeepEdit allows clinicians to quickly segment their datasets by using the algorithm in auto segmentation mode or by providing clicks via a user interface (i.e. 3D Slicer, OHIF). We show the value of DeepEdit through evaluation on the PROSTATEx dataset for prostate/prostatic lesions and the Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) dataset for abdominal CT segmentation, using state-of-the-art network architectures as baseline for comparison. DeepEdit could reduce the time and effort annotating 3D medical images compared to DeepGrow alone. Source code is available at https://github.com/Project-MONAI/MONAILabel
Communication-Efficient Vertical Federated Learning with Limited Overlapping Samples
Mar 30, 2023



Federated learning is a popular collaborative learning approach that enables clients to train a global model without sharing their local data. Vertical federated learning (VFL) deals with scenarios in which the data on clients have different feature spaces but share some overlapping samples. Existing VFL approaches suffer from high communication costs and cannot deal efficiently with limited overlapping samples commonly seen in the real world. We propose a practical vertical federated learning (VFL) framework called \textbf{one-shot VFL} that can solve the communication bottleneck and the problem of limited overlapping samples simultaneously based on semi-supervised learning. We also propose \textbf{few-shot VFL} to improve the accuracy further with just one more communication round between the server and the clients. In our proposed framework, the clients only need to communicate with the server once or only a few times. We evaluate the proposed VFL framework on both image and tabular datasets. Our methods can improve the accuracy by more than 46.5\% and reduce the communication cost by more than 330$\times$ compared with state-of-the-art VFL methods when evaluated on CIFAR-10. Our code will be made publicly available at \url{https://nvidia.github.io/NVFlare/research/one-shot-vfl}.
Fair Federated Medical Image Segmentation via Client Contribution Estimation
Mar 29, 2023How to ensure fairness is an important topic in federated learning (FL). Recent studies have investigated how to reward clients based on their contribution (collaboration fairness), and how to achieve uniformity of performance across clients (performance fairness). Despite achieving progress on either one, we argue that it is critical to consider them together, in order to engage and motivate more diverse clients joining FL to derive a high-quality global model. In this work, we propose a novel method to optimize both types of fairness simultaneously. Specifically, we propose to estimate client contribution in gradient and data space. In gradient space, we monitor the gradient direction differences of each client with respect to others. And in data space, we measure the prediction error on client data using an auxiliary model. Based on this contribution estimation, we propose a FL method, federated training via contribution estimation (FedCE), i.e., using estimation as global model aggregation weights. We have theoretically analyzed our method and empirically evaluated it on two real-world medical datasets. The effectiveness of our approach has been validated with significant performance improvements, better collaboration fairness, better performance fairness, and comprehensive analytical studies.
Federated Virtual Learning on Heterogeneous Data with Local-global Distillation
Mar 04, 2023



Despite Federated Learning (FL)'s trend for learning machine learning models in a distributed manner, it is susceptible to performance drops when training on heterogeneous data. Recently, dataset distillation has been explored in order to improve the efficiency and scalability of FL by creating a smaller, synthetic dataset that retains the performance of a model trained on the local private datasets. We discover that using distilled local datasets can amplify the heterogeneity issue in FL. To address this, we propose a new method, called Federated Virtual Learning on Heterogeneous Data with Local-Global Distillation (FEDLGD), which trains FL using a smaller synthetic dataset (referred as virtual data) created through a combination of local and global distillation. Specifically, to handle synchronization and class imbalance, we propose iterative distribution matching to allow clients to have the same amount of balanced local virtual data; to harmonize the domain shifts, we use federated gradient matching to distill global virtual data that are shared with clients without hindering data privacy to rectify heterogeneous local training via enforcing local-global feature similarity. We experiment on both benchmark and real-world datasets that contain heterogeneous data from different sources. Our method outperforms state-of-the-art heterogeneous FL algorithms under the setting with a very limited amount of distilled virtual data.
PerAda: Parameter-Efficient and Generalizable Federated Learning Personalization with Guarantees
Feb 13, 2023



Personalized Federated Learning (pFL) has emerged as a promising solution to tackle data heterogeneity across clients in FL. However, existing pFL methods either (1) introduce high communication and computation costs or (2) overfit to local data, which can be limited in scope, and are vulnerable to evolved test samples with natural shifts. In this paper, we propose PerAda, a parameter-efficient pFL framework that reduces communication and computational costs and exhibits superior generalization performance, especially under test-time distribution shifts. PerAda reduces the costs by leveraging the power of pretrained models and only updates and communicates a small number of additional parameters from adapters. PerAda has good generalization since it regularizes each client's personalized adapter with a global adapter, while the global adapter uses knowledge distillation to aggregate generalized information from all clients. Theoretically, we provide generalization bounds to explain why PerAda improves generalization, and we prove its convergence to stationary points under non-convex settings. Empirically, PerAda demonstrates competitive personalized performance (+4.85% on CheXpert) and enables better out-of-distribution generalization (+5.23% on CIFAR-10-C) on different datasets across natural and medical domains compared with baselines, while only updating 12.6% of parameters per model based on the adapter.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022



Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.
Automated head and neck tumor segmentation from 3D PET/CT
Sep 22, 2022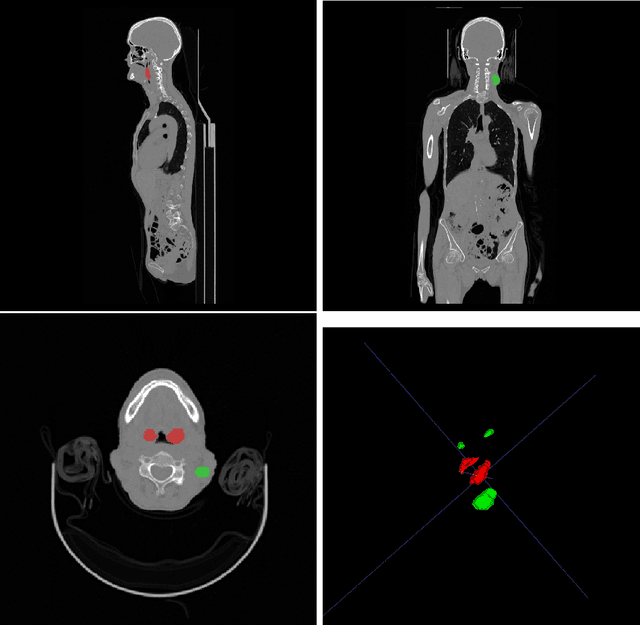
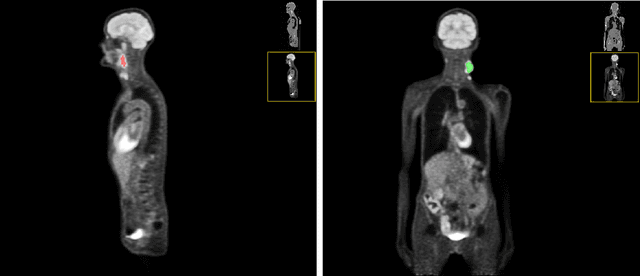
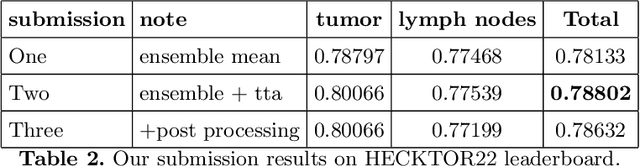
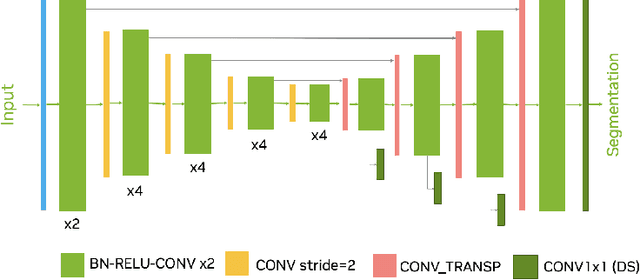
Head and neck tumor segmentation challenge (HECKTOR) 2022 offers a platform for researchers to compare their solutions to segmentation of tumors and lymph nodes from 3D CT and PET images. In this work, we describe our solution to HECKTOR 2022 segmentation task. We re-sample all images to a common resolution, crop around head and neck region, and train SegResNet semantic segmentation network from MONAI. We use 5-fold cross validation to select best model checkpoints. The final submission is an ensemble of 15 models from 3 runs. Our solution (team name NVAUTO) achieves the 1st place on the HECKTOR22 challenge leaderboard with an aggregated dice score of 0.78802.
Automated segmentation of intracranial hemorrhages from 3D CT
Sep 21, 2022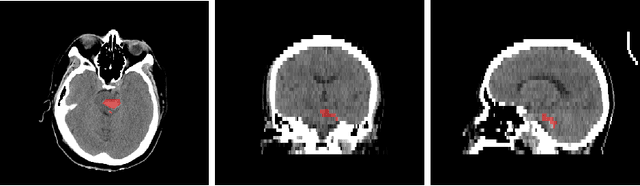
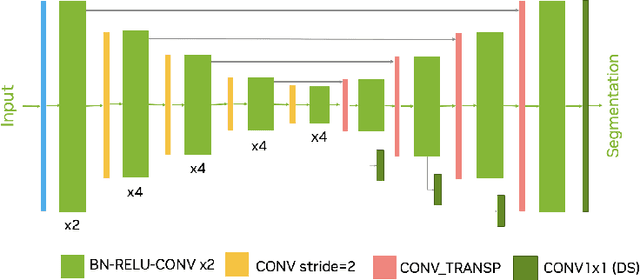
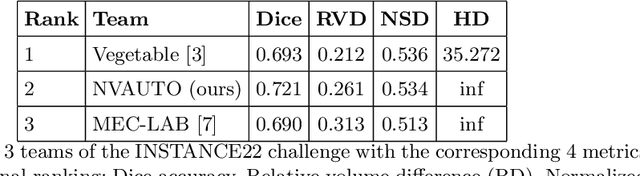
Intracranial hemorrhage segmentation challenge (INSTANCE 2022) offers a platform for researchers to compare their solutions to segmentation of hemorrhage stroke regions from 3D CTs. In this work, we describe our solution to INSTANCE 2022. We use a 2D segmentation network, SegResNet from MONAI, operating slice-wise without resampling. The final submission is an ensemble of 18 models. Our solution (team name NVAUTO) achieves the top place in terms of Dice metric (0.721), and overall rank 2. It is implemented with Auto3DSeg.