 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMAug: Point Prompt Augmentation for Segment Anything Model
Jul 03, 2023This paper introduces SAMAug, a novel visual point augmentation method for the Segment Anything Model (SAM) that enhances interactive image segmentation performance. SAMAug generates augmented point prompts to provide more information to SAM. From the initial point prompt, SAM produces the initial mask, which is then fed into our proposed SAMAug to generate augmented point prompts. By incorporating these extra points, SAM can generate augmented segmentation masks based on the augmented point prompts and the initial prompt, resulting in improved segmentation performance. We evaluate four point augmentation techniques: random selection, maximum difference entropy, maximum distance, and a saliency model. Experiments on the COCO, Fundus, and Chest X-ray datasets demonstrate that SAMAug can boost SAM's segmentation results, especially using the maximum distance and saliency model methods. SAMAug underscores the potential of visual prompt engineering to advance interactive computer vision models.
Radiology-GPT: A Large Language Model for Radiology
Jun 14, 2023



We introduce Radiology-GPT, a large language model for radiology. Using an instruction tuning approach on an extensive dataset of radiology domain knowledge, Radiology-GPT demonstrates superior performance compared to general language models such as StableLM, Dolly and LLaMA. It exhibits significant versatility in radiological diagnosis, research, and communication. This work serves as a catalyst for future developments in clinical NLP. The successful implementation of Radiology-GPT is indicative of the potential of localizing generative large language models, specifically tailored for distinctive medical specialties, while ensuring adherence to privacy standards such as HIPAA. The prospect of developing individualized, large-scale language models that cater to specific needs of various hospitals presents a promising direction. The fusion of conversational competence and domain-specific knowledge in these models is set to foster future development in healthcare AI. A demo of Radiology-GPT is available at https://huggingface.co/spaces/allen-eric/radiology-gpt.
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
ImpressionGPT: An Iterative Optimizing Framework for Radiology Report Summarization with ChatGPT
May 03, 2023The 'Impression' section of a radiology report is a critical basis for communication between radiologists and other physicians, and it is typically written by radiologists based on the 'Findings' section. However, writing numerous impressions can be laborious and error-prone for radiologists. Although recent studies have achieved promising results in automatic impression generation using large-scale medical text data for pre-training and fine-tuning pre-trained language models, such models often require substantial amounts of medical text data and have poor generalization performance. While large language models (LLMs) like ChatGPT have shown strong generalization capabilities and performance, their performance in specific domains, such as radiology, remains under-investigated and potentially limited. To address this limitation, we propose ImpressionGPT, which leverages the in-context learning capability of LLMs by constructing dynamic contexts using domain-specific, individualized data. This dynamic prompt approach enables the model to learn contextual knowledge from semantically similar examples from existing data. Additionally, we design an iterative optimization algorithm that performs automatic evaluation on the generated impression results and composes the corresponding instruction prompts to further optimize the model. The proposed ImpressionGPT model achieves state-of-the-art performance on both MIMIC-CXR and OpenI datasets without requiring additional training data or fine-tuning the LLMs. This work presents a paradigm for localizing LLMs that can be applied in a wide range of similar application scenarios, bridging the gap between general-purpose LLMs and the specific language processing needs of various domains.
Instruction-ViT: Multi-Modal Prompts for Instruction Learning in ViT
Apr 29, 2023Prompts have been proven to play a crucial role in large language models, and in recent years, vision models have also been using prompts to improve scalability for multiple downstream tasks. In this paper, we focus on adapting prompt design based on instruction tuning into a visual transformer model for image classification which we called Instruction-ViT. The key idea is to implement multi-modal prompts (text or image prompt) related to category information to guide the fine-tuning of the model. Based on the experiments of several image captionining tasks, the performance and domain adaptability were improved. Our work provided an innovative strategy to fuse multi-modal prompts with better performance and faster adaptability for visual classification models.
Prompt Engineering for Healthcare: Methodologies and Applications
Apr 28, 2023This review will introduce the latest advances in prompt engineering in the field of natural language processing (NLP) for the medical domain. First, we will provide a brief overview of the development of prompt engineering and emphasize its significant contributions to healthcare NLP applications such as question-answering systems, text summarization, and machine translation. With the continuous improvement of general large language models, the importance of prompt engineering in the healthcare domain is becoming increasingly prominent. The aim of this article is to provide useful resources and bridges for healthcare NLP researchers to better explore the application of prompt engineering in this field. We hope that this review can provide new ideas and inspire ample possibilities for research and application in medical NLP.
ChatABL: Abductive Learning via Natural Language Interaction with ChatGPT
Apr 21, 2023Large language models (LLMs) such as ChatGPT have recently demonstrated significant potential in mathematical abilities, providing valuable reasoning paradigm consistent with human natural language. However, LLMs currently have difficulty in bridging perception, language understanding and reasoning capabilities due to incompatibility of the underlying information flow among them, making it challenging to accomplish tasks autonomously. On the other hand, abductive learning (ABL) frameworks for integrating the two abilities of perception and reasoning has seen significant success in inverse decipherment of incomplete facts, but it is limited by the lack of semantic understanding of logical reasoning rules and the dependence on complicated domain knowledge representation. This paper presents a novel method (ChatABL) for integrating LLMs into the ABL framework, aiming at unifying the three abilities in a more user-friendly and understandable manner. The proposed method uses the strengths of LLMs' understanding and logical reasoning to correct the incomplete logical facts for optimizing the performance of perceptual module, by summarizing and reorganizing reasoning rules represented in natural language format. Similarly, perceptual module provides necessary reasoning examples for LLMs in natural language format. The variable-length handwritten equation deciphering task, an abstract expression of the Mayan calendar decoding, is used as a testbed to demonstrate that ChatABL has reasoning ability beyond most existing state-of-the-art methods, which has been well supported by comparative studies. To our best knowledge, the proposed ChatABL is the first attempt to explore a new pattern for further approaching human-level cognitive ability via natural language interaction with ChatGPT.
Exploring the Trade-Offs: Unified Large Language Models vs Local Fine-Tuned Models for Highly-Specific Radiology NLI Task
Apr 18, 2023



Recently, ChatGPT and GPT-4 have emerged and gained immense global attention due to their unparalleled performance in language processing. Despite demonstrating impressive capability in various open-domain tasks, their adequacy in highly specific fields like radiology remains untested. Radiology presents unique linguistic phenomena distinct from open-domain data due to its specificity and complexity. Assessing the performance of large language models (LLMs) in such specific domains is crucial not only for a thorough evaluation of their overall performance but also for providing valuable insights into future model design directions: whether model design should be generic or domain-specific. To this end, in this study, we evaluate the performance of ChatGPT/GPT-4 on a radiology NLI task and compare it to other models fine-tuned specifically on task-related data samples. We also conduct a comprehensive investigation on ChatGPT/GPT-4's reasoning ability by introducing varying levels of inference difficulty. Our results show that 1) GPT-4 outperforms ChatGPT in the radiology NLI task; 2) other specifically fine-tuned models require significant amounts of data samples to achieve comparable performance to ChatGPT/GPT-4. These findings demonstrate that constructing a generic model that is capable of solving various tasks across different domains is feasible.
Rectify ViT Shortcut Learning by Visual Saliency
Jun 17, 2022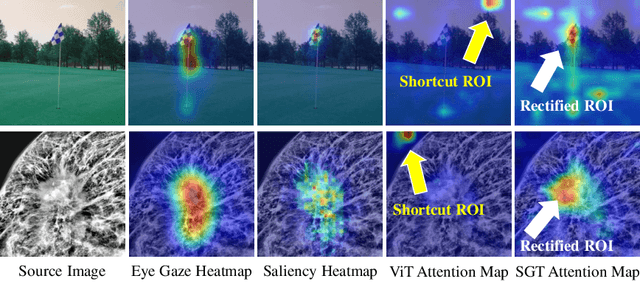
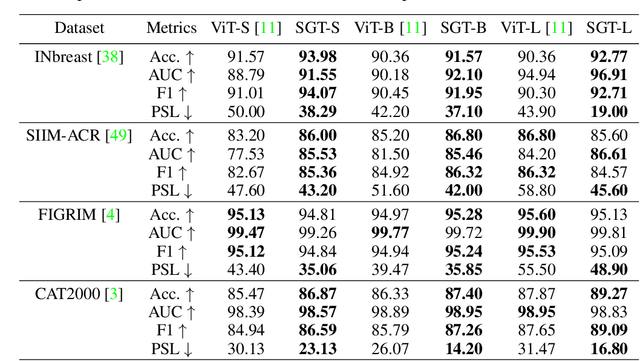
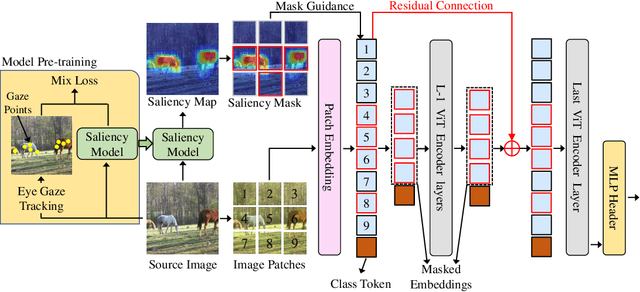
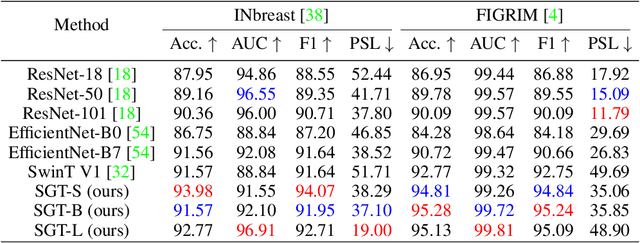
Shortcut learning is common but harmful to deep learning models, leading to degenerated feature representations and consequently jeopardizing the model's generalizability and interpretability. However, shortcut learning in the widely used Vision Transformer framework is largely unknown. Meanwhile, introducing domain-specific knowledge is a major approach to rectifying the shortcuts, which are predominated by background related factors. For example, in the medical imaging field, eye-gaze data from radiologists is an effective human visual prior knowledge that has the great potential to guide the deep learning models to focus on meaningful foreground regions of interest. However, obtaining eye-gaze data is time-consuming, labor-intensive and sometimes even not practical. In this work, we propose a novel and effective saliency-guided vision transformer (SGT) model to rectify shortcut learning in ViT with the absence of eye-gaze data. Specifically, a computational visual saliency model is adopted to predict saliency maps for input image samples. Then, the saliency maps are used to distil the most informative image patches. In the proposed SGT, the self-attention among image patches focus only on the distilled informative ones. Considering this distill operation may lead to global information lost, we further introduce, in the last encoder layer, a residual connection that captures the self-attention across all the image patches. The experiment results on four independent public datasets show that our SGT framework can effectively learn and leverage human prior knowledge without eye gaze data and achieves much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the interpretability of the ViT model, demonstrating the promise of transferring human prior knowledge derived visual saliency in rectifying shortcut learning
Eye-gaze-guided Vision Transformer for Rectifying Shortcut Learning
May 25, 2022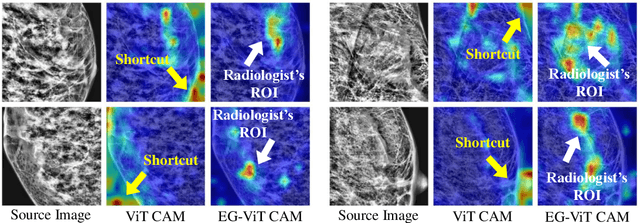
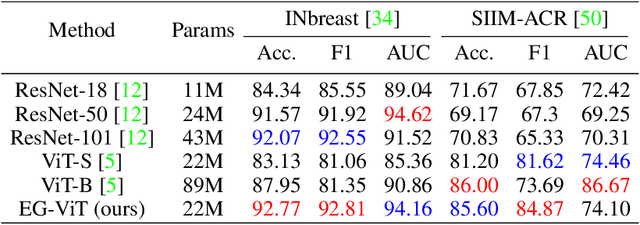
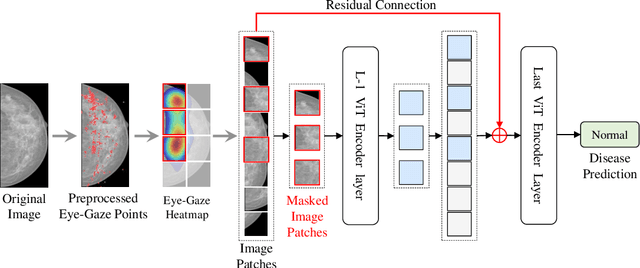
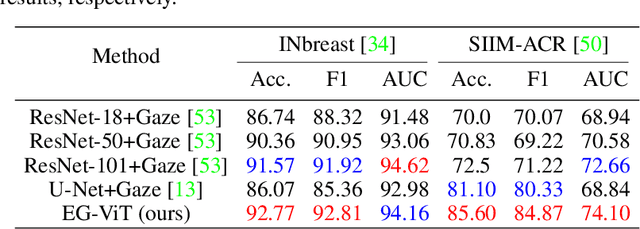
Learning harmful shortcuts such as spurious correlations and biases prevents deep neural networks from learning the meaningful and useful representations, thus jeopardizing the generalizability and interpretability of the learned representation. The situation becomes even more serious in medical imaging, where the clinical data (e.g., MR images with pathology) are limited and scarce while the reliability, generalizability and transparency of the learned model are highly required. To address this problem, we propose to infuse human experts' intelligence and domain knowledge into the training of deep neural networks. The core idea is that we infuse the visual attention information from expert radiologists to proactively guide the deep model to focus on regions with potential pathology and avoid being trapped in learning harmful shortcuts. To do so, we propose a novel eye-gaze-guided vision transformer (EG-ViT) for diagnosis with limited medical image data. We mask the input image patches that are out of the radiologists' interest and add an additional residual connection in the last encoder layer of EG-ViT to maintain the correlations of all patches. The experiments on two public datasets of INbreast and SIIM-ACR demonstrate our EG-ViT model can effectively learn/transfer experts' domain knowledge and achieve much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the EG-ViT model's interpretability. In general, EG-ViT takes the advantages of both human expert's prior knowledge and the power of deep neural networks. This work opens new avenues for advancing current artificial intelligence paradigms by infusing human intelligence.