 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSWAM: A Dual-System World Action Foundation Model for Fine-Grained Robot Manipulation
Jul 06, 2026World Action Models (WAMs) provide a promising alternative to Vision-Language-Action (VLA) policies by using video-based world modeling as dense supervision for robot action learning. Existing WAMs excel at physically grounded execution, but typically lack the explicit language-level planning interface in VLM-based VLAs for decomposing coarse instructions. Such decomposition becomes important when household tasks involve complex multi-step goals, where coarse user commands need to be converted into sequences of fine-grained executable subtasks. Meanwhile, the field still lacks a fair real-robot comparison between VLA and WAM execution capabilities, since existing systems often differ in data, robot embodiments, and task protocols. To address both the decomposition gap and the need for a controlled WAM-VLA comparison, we introduce DSWAM, a Dual-System World Action Foundation Model for fine-grained robot manipulation. DSWAM keeps a System 1 WAM executor as the default control path and optionally activates a System 2 vision-language subtask planner only when task decomposition is useful. The planner predicts executable subtasks from short-term visual history and a global task prompt, while the WAM executor performs world-aware action generation for each instruction or subtask. The executor is trained with action prediction and video co-training, but inference directly predicts action chunks without explicit future video generation. To make this execution path practical on real robots, we further integrate TensorRT acceleration, asynchronous execution, and real-time chunking (RTC) so that policy queries do not block robot control. To provide a fair real-robot comparison with VLA policies, we build and evaluate DSWAM under the DeMaVLA real-world deformable manipulation setting with matched robot platform, pretraining data, post-training data, and evaluation criteria.
PiL-World: A Chunk-Wise World Model for VLA Policy-in-the-Loop Evaluation
Jun 04, 2026Vision-language-action (VLA) policies operate in a closed loop in real-world robot tasks: a robot observes the scene, executes an action chunk, and conditions its next decision on the resulting observation. However, most existing world models for robot action evaluation are limited to open-loop prediction along pre-collected action trajectories. This prevents them from supporting closed-loop VLA evaluation, where each action chunk must be conditioned on the observation generated by the previous execution. To address this gap, we propose PiL-World, a chunk-wise world model designed for policy-in-the-loop VLA evaluation. Given the current observation and the action trajectory rolled out by a VLA policy, PiL-World generates multi-view future observations that are consistent with the VLA rollout and match the image inputs required by the policy. By alternating between VLA inference and world-model prediction, PiL-World enables closed-loop evaluation without real robot execution at every step. To improve rollout fidelity, PiL-World conditions video generation on action-derived visual control from head-view robot motion and latent histories that encode task execution context, while jointly predicting complementary multi-view observations. Beyond successful teleoperated demonstrations, it also learns from failed execution trajectories, helping the imagined rollouts better match the distribution of real policy executions. We evaluate PiL-World on three real dual-arm manipulation tasks. PiL-World generates imagined rollouts that are highly consistent with real robot executions. More importantly, compared with the baseline, it reduces the error between VLA success rates measured in real-world rollouts and those estimated through closed-loop world-model evaluation from 63.2% to 12.0%.
DeMaVLA: A Vision-Language-Action Foundation Model for Generalizable Deformable Manipulation
May 29, 2026Real-world household robots require Vision-Language-Action (VLA) foundation models that can acquire reusable manipulation skills across diverse objects, task conditions, and household environments. Deformable-object folding is a representative challenge, requiring robots to handle clothing items from random initial states across varying categories, geometries, materials, and scenes. However, existing VLA systems commonly train separate policies for different object categories, while naively mixed multi-task training often suffers from task interference and degraded performance. To move beyond category-specific folding policies, we introduce DeMaVLA, a VLA foundation model for generalizable Deformable Manipulation. DeMaVLA adopts a VLM backbone with an action expert and formulates continuous action generation using flow matching. To improve efficiency, the action expert is constructed by pruning every other transformer layer while preserving layer-wise alignment with the VLM backbone, reducing training and inference cost. DeMaVLA is first pre-trained on approximately 5,000 hours of selected real-world dual-arm demonstrations to acquire general manipulation priors. It is then post-trained on mixed folding data that aggregates self-collected demonstrations and corrective trajectories from real-robot failures across multiple folding tasks through a human-in-the-loop Data Aggregation~(DAgger) pipeline. Experiments show that DeMaVLA achieves competitive performance on RoboTwin and strong real-world results on our household folding benchmark. These results highlight the value of scalable real-world data, efficient action generation, and corrective learning for general-purpose VLA policies in deformable-object manipulation.
Following the Diagnostic Trace: Visual Cognition-guided Cooperative Network for Chest X-Ray Diagnosis
Feb 25, 2026Computer-aided diagnosis (CAD) has significantly advanced automated chest X-ray diagnosis but remains isolated from clinical workflows and lacks reliable decision support and interpretability. Human-AI collaboration seeks to enhance the reliability of diagnostic models by integrating the behaviors of controllable radiologists. However, the absence of interactive tools seamlessly embedded within diagnostic routines impedes collaboration, while the semantic gap between radiologists' decision-making patterns and model representations further limits clinical adoption. To overcome these limitations, we propose a visual cognition-guided collaborative network (VCC-Net) to achieve the cooperative diagnostic paradigm. VCC-Net centers on visual cognition (VC) and employs clinically compatible interfaces, such as eye-tracking or the mouse, to capture radiologists' visual search traces and attention patterns during diagnosis. VCC-Net employs VC as a spatial cognition guide, learning hierarchical visual search strategies to localize diagnostically key regions. A cognition-graph co-editing module subsequently integrates radiologist VC with model inference to construct a disease-aware graph. The module captures dependencies among anatomical regions and aligns model representations with VC-driven features, mitigating radiologist bias and facilitating complementary, transparent decision-making. Experiments on the public datasets SIIM-ACR, EGD-CXR, and self-constructed TB-Mouse dataset achieved classification accuracies of 88.40%, 85.05%, and 92.41%, respectively. The attention maps produced by VCC-Net exhibit strong concordance with radiologists' gaze distributions, demonstrating a mutual reinforcement of radiologist and model inference. The code is available at https://github.com/IPMI-NWU/VCC-Net.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Towards High-Consistency Embodied World Model with Multi-View Trajectory Videos
Nov 19, 2025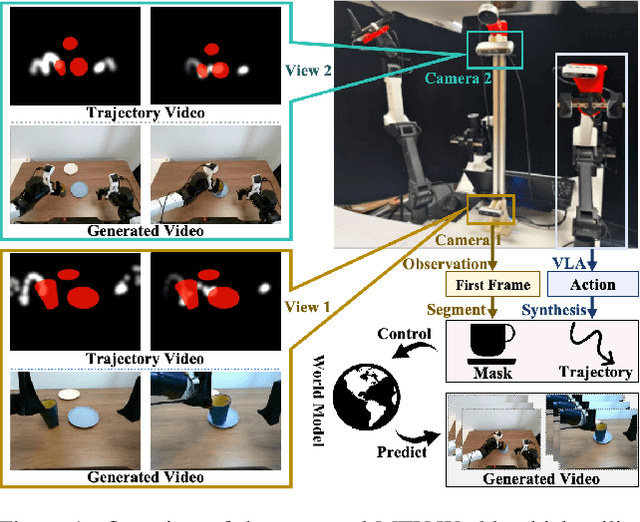

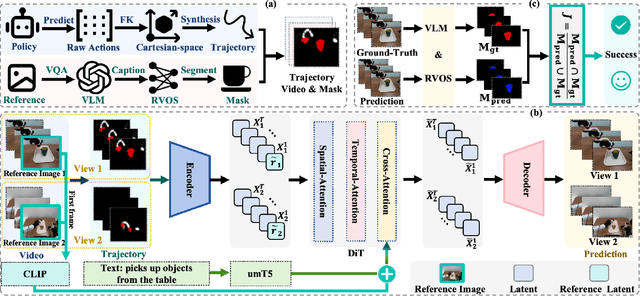
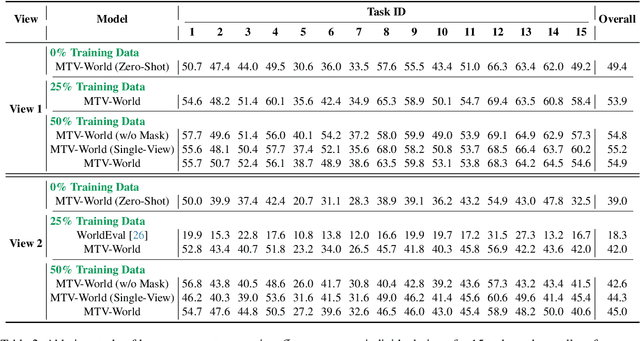
Embodied world models aim to predict and interact with the physical world through visual observations and actions. However, existing models struggle to accurately translate low-level actions (e.g., joint positions) into precise robotic movements in predicted frames, leading to inconsistencies with real-world physical interactions. To address these limitations, we propose MTV-World, an embodied world model that introduces Multi-view Trajectory-Video control for precise visuomotor prediction. Specifically, instead of directly using low-level actions for control, we employ trajectory videos obtained through camera intrinsic and extrinsic parameters and Cartesian-space transformation as control signals. However, projecting 3D raw actions onto 2D images inevitably causes a loss of spatial information, making a single view insufficient for accurate interaction modeling. To overcome this, we introduce a multi-view framework that compensates for spatial information loss and ensures high-consistency with physical world. MTV-World forecasts future frames based on multi-view trajectory videos as input and conditioning on an initial frame per view. Furthermore, to systematically evaluate both robotic motion precision and object interaction accuracy, we develop an auto-evaluation pipeline leveraging multimodal large models and referring video object segmentation models. To measure spatial consistency, we formulate it as an object location matching problem and adopt the Jaccard Index as the evaluation metric. Extensive experiments demonstrate that MTV-World achieves precise control execution and accurate physical interaction modeling in complex dual-arm scenarios.
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
Advancing Medical Radiograph Representation Learning: A Hybrid Pre-training Paradigm with Multilevel Semantic Granularity
Oct 01, 2024



This paper introduces an innovative approach to Medical Vision-Language Pre-training (Med-VLP) area in the specialized context of radiograph representation learning. While conventional methods frequently merge textual annotations into unified reports, we acknowledge the intrinsic hierarchical relationship between the findings and impression section in radiograph datasets. To establish a targeted correspondence between images and texts, we propose a novel HybridMED framework to align global-level visual representations with impression and token-level visual representations with findings. Moreover, our framework incorporates a generation decoder that employs two proxy tasks, responsible for generating the impression from (1) images, via a captioning branch, and (2) findings, through a summarization branch. Additionally, knowledge distillation is leveraged to facilitate the training process. Experiments on the MIMIC-CXR dataset reveal that our summarization branch effectively distills knowledge to the captioning branch, enhancing model performance without significantly increasing parameter requirements due to the shared self-attention and feed-forward architecture.
* 18 pages
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Aug 02, 2024
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.