 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior
Jun 09, 2025



Multimodal Large Language Models (MLLMs) have shown great potential in revolutionizing Graphical User Interface (GUI) automation. However, existing GUI models mostly rely on learning from nearly error-free offline trajectories, thus lacking reflection and error recovery capabilities. To bridge this gap, we propose GUI-Reflection, a novel framework that explicitly integrates self-reflection and error correction capabilities into end-to-end multimodal GUI models throughout dedicated training stages: GUI-specific pre-training, offline supervised fine-tuning (SFT), and online reflection tuning. GUI-reflection enables self-reflection behavior emergence with fully automated data generation and learning processes without requiring any human annotation. Specifically, 1) we first propose scalable data pipelines to automatically construct reflection and error correction data from existing successful trajectories. While existing GUI models mainly focus on grounding and UI understanding ability, we propose the GUI-Reflection Task Suite to learn and evaluate reflection-oriented abilities explicitly. 2) Furthermore, we built a diverse and efficient environment for online training and data collection of GUI models on mobile devices. 3) We also present an iterative online reflection tuning algorithm leveraging the proposed environment, enabling the model to continuously enhance its reflection and error correction abilities. Our framework equips GUI agents with self-reflection and correction capabilities, paving the way for more robust, adaptable, and intelligent GUI automation, with all data, models, environments, and tools to be released publicly.
Decoding Knowledge Attribution in Mixture-of-Experts: A Framework of Basic-Refinement Collaboration and Efficiency Analysis
May 30, 2025The interpretability of Mixture-of-Experts (MoE) models, especially those with heterogeneous designs, remains underexplored. Existing attribution methods for dense models fail to capture dynamic routing-expert interactions in sparse MoE architectures. To address this issue, we propose a cross-level attribution algorithm to analyze sparse MoE architectures (Qwen 1.5-MoE, OLMoE, Mixtral-8x7B) against dense models (Qwen 1.5-7B, Llama-7B, Mixtral-7B). Results show MoE models achieve 37% higher per-layer efficiency via a "mid-activation, late-amplification" pattern: early layers screen experts, while late layers refine knowledge collaboratively. Ablation studies reveal a "basic-refinement" framework--shared experts handle general tasks (entity recognition), while routed experts specialize in domain-specific processing (geographic attributes). Semantic-driven routing is evidenced by strong correlations between attention heads and experts (r=0.68), enabling task-aware coordination. Notably, architectural depth dictates robustness: deep Qwen 1.5-MoE mitigates expert failures (e.g., 43% MRR drop in geographic tasks when blocking top-10 experts) through shared expert redundancy, whereas shallow OLMoE suffers severe degradation (76% drop). Task sensitivity further guides design: core-sensitive tasks (geography) require concentrated expertise, while distributed-tolerant tasks (object attributes) leverage broader participation. These insights advance MoE interpretability, offering principles to balance efficiency, specialization, and robustness.
BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model
May 29, 2025



Unlocking deep, interpretable biological reasoning from complex genomic data is a major AI challenge hindering scientific discovery. Current DNA foundation models, despite strong sequence representation, struggle with multi-step reasoning and lack inherent transparent, biologically intuitive explanations. We introduce BioReason, a pioneering architecture that, for the first time, deeply integrates a DNA foundation model with a Large Language Model (LLM). This novel connection enables the LLM to directly process and reason with genomic information as a fundamental input, fostering a new form of multimodal biological understanding. BioReason's sophisticated multi-step reasoning is developed through supervised fine-tuning and targeted reinforcement learning, guiding the system to generate logical, biologically coherent deductions. On biological reasoning benchmarks including KEGG-based disease pathway prediction - where accuracy improves from 88% to 97% - and variant effect prediction, BioReason demonstrates an average 15% performance gain over strong single-modality baselines. BioReason reasons over unseen biological entities and articulates decision-making through interpretable, step-by-step biological traces, offering a transformative approach for AI in biology that enables deeper mechanistic insights and accelerates testable hypothesis generation from genomic data. Data, code, and checkpoints are publicly available at https://github.com/bowang-lab/BioReason
Frame-Level Captions for Long Video Generation with Complex Multi Scenes
May 27, 2025Generating long videos that can show complex stories, like movie scenes from scripts, has great promise and offers much more than short clips. However, current methods that use autoregression with diffusion models often struggle because their step-by-step process naturally leads to a serious error accumulation (drift). Also, many existing ways to make long videos focus on single, continuous scenes, making them less useful for stories with many events and changes. This paper introduces a new approach to solve these problems. First, we propose a novel way to annotate datasets at the frame-level, providing detailed text guidance needed for making complex, multi-scene long videos. This detailed guidance works with a Frame-Level Attention Mechanism to make sure text and video match precisely. A key feature is that each part (frame) within these windows can be guided by its own distinct text prompt. Our training uses Diffusion Forcing to provide the model with the ability to handle time flexibly. We tested our approach on difficult VBench 2.0 benchmarks ("Complex Plots" and "Complex Landscapes") based on the WanX2.1-T2V-1.3B model. The results show our method is better at following instructions in complex, changing scenes and creates high-quality long videos. We plan to share our dataset annotation methods and trained models with the research community. Project page: https://zgctroy.github.io/frame-level-captions .
R3-RAG: Learning Step-by-Step Reasoning and Retrieval for LLMs via Reinforcement Learning
May 26, 2025



Retrieval-Augmented Generation (RAG) integrates external knowledge with Large Language Models (LLMs) to enhance factual correctness and mitigate hallucination. However, dense retrievers often become the bottleneck of RAG systems due to their limited parameters compared to LLMs and their inability to perform step-by-step reasoning. While prompt-based iterative RAG attempts to address these limitations, it is constrained by human-designed workflows. To address these limitations, we propose $\textbf{R3-RAG}$, which uses $\textbf{R}$einforcement learning to make the LLM learn how to $\textbf{R}$eason and $\textbf{R}$etrieve step by step, thus retrieving comprehensive external knowledge and leading to correct answers. R3-RAG is divided into two stages. We first use cold start to make the model learn the manner of iteratively interleaving reasoning and retrieval. Then we use reinforcement learning to further harness its ability to better explore the external retrieval environment. Specifically, we propose two rewards for R3-RAG: 1) answer correctness for outcome reward, which judges whether the trajectory leads to a correct answer; 2) relevance-based document verification for process reward, encouraging the model to retrieve documents that are relevant to the user question, through which we can let the model learn how to iteratively reason and retrieve relevant documents to get the correct answer. Experimental results show that R3-RAG significantly outperforms baselines and can transfer well to different retrievers. We release R3-RAG at https://github.com/Yuan-Li-FNLP/R3-RAG.
Ctrl-DNA: Controllable Cell-Type-Specific Regulatory DNA Design via Constrained RL
May 26, 2025Designing regulatory DNA sequences that achieve precise cell-type-specific gene expression is crucial for advancements in synthetic biology, gene therapy and precision medicine. Although transformer-based language models (LMs) can effectively capture patterns in regulatory DNA, their generative approaches often struggle to produce novel sequences with reliable cell-specific activity. Here, we introduce Ctrl-DNA, a novel constrained reinforcement learning (RL) framework tailored for designing regulatory DNA sequences with controllable cell-type specificity. By formulating regulatory sequence design as a biologically informed constrained optimization problem, we apply RL to autoregressive genomic LMs, enabling the models to iteratively refine sequences that maximize regulatory activity in targeted cell types while constraining off-target effects. Our evaluation on human promoters and enhancers demonstrates that Ctrl-DNA consistently outperforms existing generative and RL-based approaches, generating high-fitness regulatory sequences and achieving state-of-the-art cell-type specificity. Moreover, Ctrl-DNA-generated sequences capture key cell-type-specific transcription factor binding sites (TFBS), short DNA motifs recognized by regulatory proteins that control gene expression, demonstrating the biological plausibility of the generated sequences.
REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
May 26, 2025We present REARANK, a large language model (LLM)-based listwise reasoning reranking agent. REARANK explicitly reasons before reranking, significantly improving both performance and interpretability. Leveraging reinforcement learning and data augmentation, REARANK achieves substantial improvements over baseline models across popular information retrieval benchmarks, notably requiring only 179 annotated samples. Built on top of Qwen2.5-7B, our REARANK-7B demonstrates performance comparable to GPT-4 on both in-domain and out-of-domain benchmarks and even surpasses GPT-4 on reasoning-intensive BRIGHT benchmarks. These results underscore the effectiveness of our approach and highlight how reinforcement learning can enhance LLM reasoning capabilities in reranking.
Chi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025



Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
CAS-IQA: Teaching Vision-Language Models for Synthetic Angiography Quality Assessment
May 23, 2025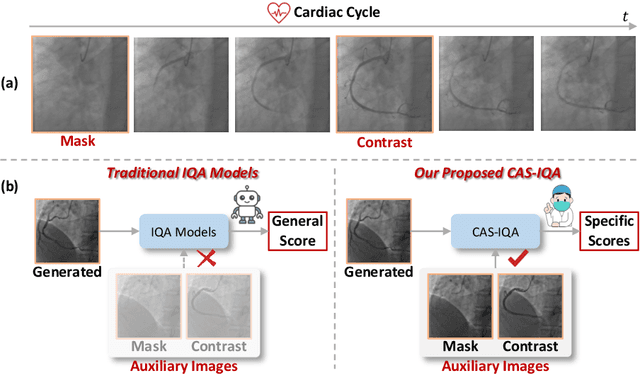
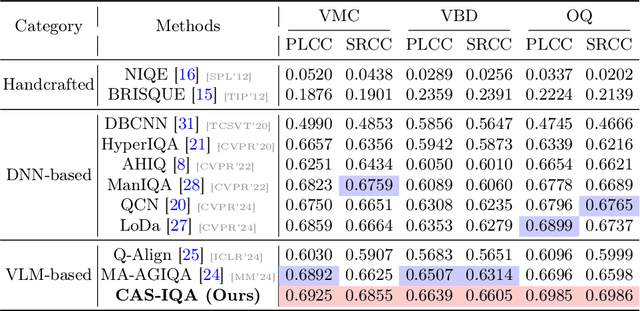
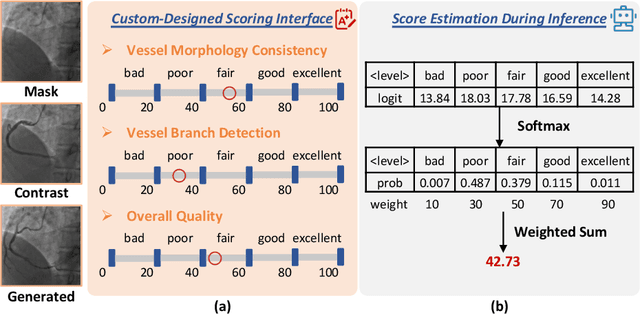

Synthetic X-ray angiographies generated by modern generative models hold great potential to reduce the use of contrast agents in vascular interventional procedures. However, low-quality synthetic angiographies can significantly increase procedural risk, underscoring the need for reliable image quality assessment (IQA) methods. Existing IQA models, however, fail to leverage auxiliary images as references during evaluation and lack fine-grained, task-specific metrics necessary for clinical relevance. To address these limitations, this paper proposes CAS-IQA, a vision-language model (VLM)-based framework that predicts fine-grained quality scores by effectively incorporating auxiliary information from related images. In the absence of angiography datasets, CAS-3K is constructed, comprising 3,565 synthetic angiographies along with score annotations. To ensure clinically meaningful assessment, three task-specific evaluation metrics are defined. Furthermore, a Multi-path featUre fuSion and rouTing (MUST) module is designed to enhance image representations by adaptively fusing and routing visual tokens to metric-specific branches. Extensive experiments on the CAS-3K dataset demonstrate that CAS-IQA significantly outperforms state-of-the-art IQA methods by a considerable margin.
SSR: Speculative Parallel Scaling Reasoning in Test-time
May 21, 2025Large language models (LLMs) have achieved impressive results on multi-step mathematical reasoning, yet at the cost of high computational overhead. This challenge is particularly acute for test-time scaling methods such as parallel decoding, which increase answer diversity but scale poorly in efficiency. To address this efficiency-accuracy trade-off, we propose SSR (Speculative Parallel Scaling Reasoning), a training-free framework that leverages a key insight: by introducing speculative decoding at the step level, we can accelerate reasoning without sacrificing correctness. SSR integrates two components: a Selective Parallel Module (SPM) that identifies a small set of promising reasoning strategies via model-internal scoring, and Step-level Speculative Decoding (SSD), which enables efficient draft-target collaboration for fine-grained reasoning acceleration. Experiments on three mathematical benchmarks-AIME 2024, MATH-500, and LiveMathBench - demonstrate that SSR achieves strong gains over baselines. For instance, on LiveMathBench, SSR improves pass@1 accuracy by 13.84% while reducing computation to 80.5% of the baseline FLOPs. On MATH-500, SSR reduces compute to only 30% with no loss in accuracy.