 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVascular anatomy-aware self-supervised pre-training for X-ray angiogram analysis
Feb 12, 2026X-ray angiography is the gold standard imaging modality for cardiovascular diseases. However, current deep learning approaches for X-ray angiogram analysis are severely constrained by the scarcity of annotated data. While large-scale self-supervised learning (SSL) has emerged as a promising solution, its potential in this domain remains largely unexplored, primarily due to the lack of effective SSL frameworks and large-scale datasets. To bridge this gap, we introduce a vascular anatomy-aware masked image modeling (VasoMIM) framework that explicitly integrates domain-specific anatomical knowledge. Specifically, VasoMIM comprises two key designs: an anatomy-guided masking strategy and an anatomical consistency loss. The former strategically masks vessel-containing patches to compel the model to learn robust vascular semantics, while the latter preserves structural consistency of vessels between original and reconstructed images, enhancing the discriminability of the learned representations. In conjunction with VasoMIM, we curate XA-170K, the largest X-ray angiogram pre-training dataset to date. We validate VasoMIM on four downstream tasks across six datasets, where it demonstrates superior transferability and achieves state-of-the-art performance compared to existing methods. These findings highlight the significant potential of VasoMIM as a foundation model for advancing a wide range of X-ray angiogram analysis tasks. VasoMIM and XA-170K will be available at https://github.com/Dxhuang-CASIA/XA-SSL.
CAS-IQA: Teaching Vision-Language Models for Synthetic Angiography Quality Assessment
May 23, 2025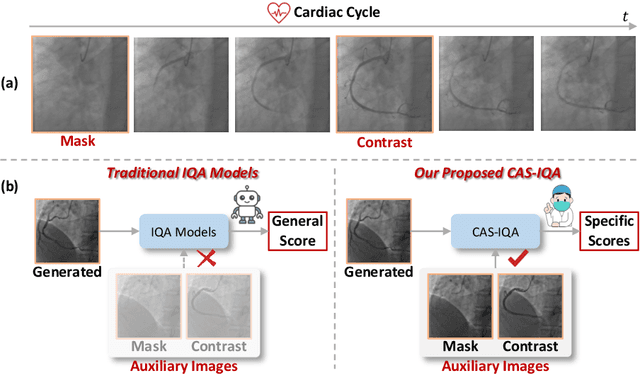
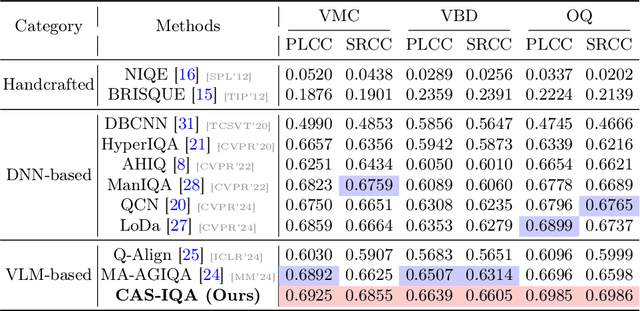
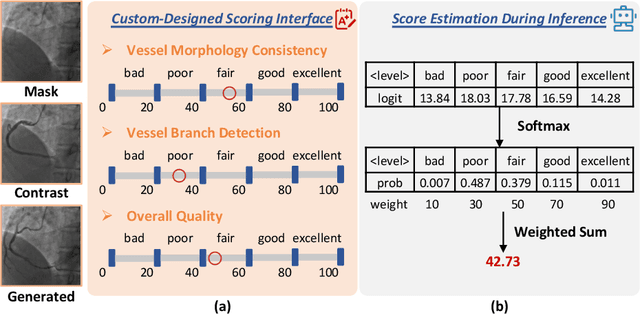

Synthetic X-ray angiographies generated by modern generative models hold great potential to reduce the use of contrast agents in vascular interventional procedures. However, low-quality synthetic angiographies can significantly increase procedural risk, underscoring the need for reliable image quality assessment (IQA) methods. Existing IQA models, however, fail to leverage auxiliary images as references during evaluation and lack fine-grained, task-specific metrics necessary for clinical relevance. To address these limitations, this paper proposes CAS-IQA, a vision-language model (VLM)-based framework that predicts fine-grained quality scores by effectively incorporating auxiliary information from related images. In the absence of angiography datasets, CAS-3K is constructed, comprising 3,565 synthetic angiographies along with score annotations. To ensure clinically meaningful assessment, three task-specific evaluation metrics are defined. Furthermore, a Multi-path featUre fuSion and rouTing (MUST) module is designed to enhance image representations by adaptively fusing and routing visual tokens to metric-specific branches. Extensive experiments on the CAS-3K dataset demonstrate that CAS-IQA significantly outperforms state-of-the-art IQA methods by a considerable margin.