 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterSketch: An Interleaved Reasoning Model with Self-correcting Visual Sketch and Stepwise Reward
May 26, 2026While vision-language models (VLMs) have exhibited multi-turn visual reasoning capabilities, their reasoning trajectories remain relatively shallow and are dominated by a text-centric paradigm, limiting their applicability to complex visual challenges. In contrast, human-like thought typically involves long-horizon reasoning with an interleaved visual-textual chain-of-thought (VT-CoT). To bridge this gap, we introduce InterSketch, an interleaved reasoning model to enhance the VT-CoT capability via self-correcting and stepwise reward mechanisms. InterSketch dynamically generates intermediate visual sketches using external tools and interleaves them with textual reasoning, enabling effective perception and logical reasoning over long-horizon visual understanding tasks. Specifically, in the first cold-start stage, we propose a synthesized high-quality interleaved VT-CoT dataset and include a reflection mechanism to enable the model's capability in multi-turn interleaved reasoning and self-correction. In the subsequent reinforcement learning (RL) stage, we design a stepwise reward mechanism to mitigate the sparsity of reward signals inherent in end-only supervision over long-horizon reasoning. Extensive experiments on visual reasoning benchmarks demonstrate the effectiveness of InterSketch, even outperforming proprietary models such as Gemini-3-Pro.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
V-ABS: Action-Observer Driven Beam Search for Dynamic Visual Reasoning
May 11, 2026Multimodal large language models (MLLMs) have achieved remarkable success in general perception, yet complex multi-step visual reasoning remains a persistent challenge. Although recent agentic approaches incorporate tool use, they often neglect critical execution feedback. Consequently, they suffer from the imagination-action-observer (IAO) bias, a misalignment between prior imagination and observer feedback that undermines reasoning stability and optimality. To bridge this gap, we introduce V-ABS, an action-observer driven beam search framework that enables deliberate reasoning through thinker-actor-observer iterations. We also propose an entropy-based adaptive weighting algorithm to mitigate the IAO bias by dynamically balancing the confidence scores between the policy priors and the observational feedback. Moreover, we construct a large-scale supervised fine-tuning (SFT) dataset comprising over 80k samples to guide the model to assign higher prior confidence to correct action paths. Extensive experiments across eight diverse benchmarks show that V-ABS achieves state-of-the-art performance, delivering an average improvement of 19.7% on the Qwen3-VL-8B baseline and consistent gains across both open-source and proprietary models.
GUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior
Jun 09, 2025



Multimodal Large Language Models (MLLMs) have shown great potential in revolutionizing Graphical User Interface (GUI) automation. However, existing GUI models mostly rely on learning from nearly error-free offline trajectories, thus lacking reflection and error recovery capabilities. To bridge this gap, we propose GUI-Reflection, a novel framework that explicitly integrates self-reflection and error correction capabilities into end-to-end multimodal GUI models throughout dedicated training stages: GUI-specific pre-training, offline supervised fine-tuning (SFT), and online reflection tuning. GUI-reflection enables self-reflection behavior emergence with fully automated data generation and learning processes without requiring any human annotation. Specifically, 1) we first propose scalable data pipelines to automatically construct reflection and error correction data from existing successful trajectories. While existing GUI models mainly focus on grounding and UI understanding ability, we propose the GUI-Reflection Task Suite to learn and evaluate reflection-oriented abilities explicitly. 2) Furthermore, we built a diverse and efficient environment for online training and data collection of GUI models on mobile devices. 3) We also present an iterative online reflection tuning algorithm leveraging the proposed environment, enabling the model to continuously enhance its reflection and error correction abilities. Our framework equips GUI agents with self-reflection and correction capabilities, paving the way for more robust, adaptable, and intelligent GUI automation, with all data, models, environments, and tools to be released publicly.
LogoDet-3K: A Large-Scale Image Dataset for Logo Detection
Aug 12, 2020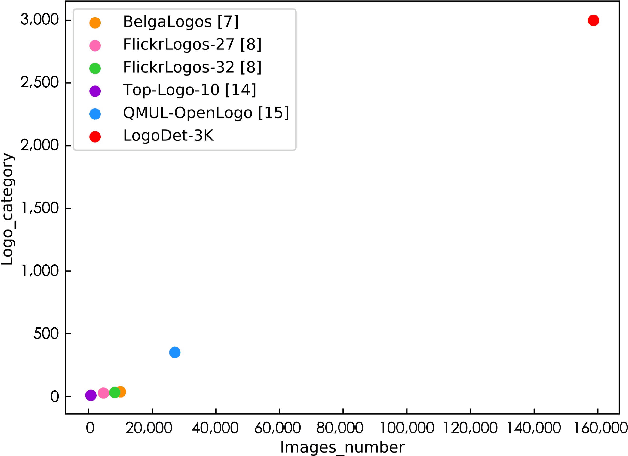
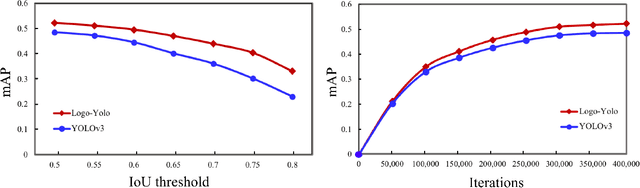


Logo detection has been gaining considerable attention because of its wide range of applications in the multimedia field, such as copyright infringement detection, brand visibility monitoring, and product brand management on social media. In this paper, we introduce LogoDet-3K, the largest logo detection dataset with full annotation, which has 3,000 logo categories, about 200,000 manually annotated logo objects and 158,652 images. LogoDet-3K creates a more challenging benchmark for logo detection, for its higher comprehensive coverage and wider variety in both logo categories and annotated objects compared with existing datasets. We describe the collection and annotation process of our dataset, analyze its scale and diversity in comparison to other datasets for logo detection. We further propose a strong baseline method Logo-Yolo, which incorporates Focal loss and CIoU loss into the state-of-the-art YOLOv3 framework for large-scale logo detection. Logo-Yolo can solve the problems of multi-scale objects, logo sample imbalance and inconsistent bounding-box regression. It obtains about 4% improvement on the average performance compared with YOLOv3, and greater improvements compared with reported several deep detection models on LogoDet-3K. The evaluations on other three existing datasets further verify the effectiveness of our method, and demonstrate better generalization ability of LogoDet-3K on logo detection and retrieval tasks. The LogoDet-3K dataset is used to promote large-scale logo-related research and it can be found at https://github.com/Wangjing1551/LogoDet-3K-Dataset.
Logo-2K+: A Large-Scale Logo Dataset for Scalable Logo Classification
Nov 11, 2019
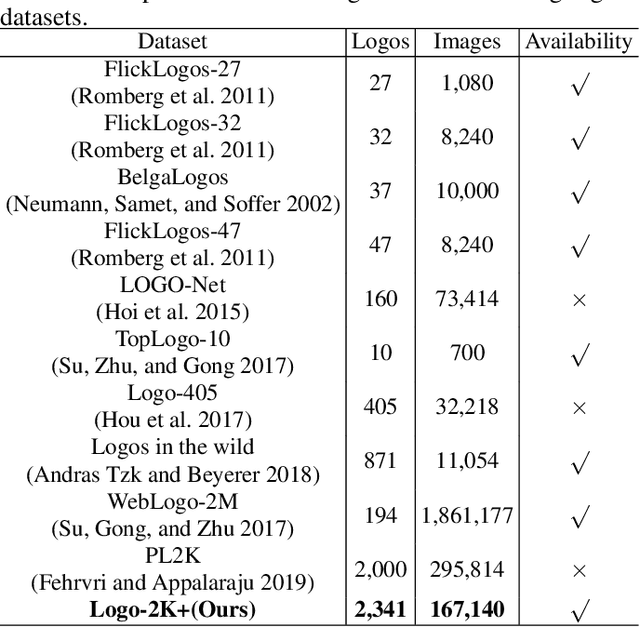
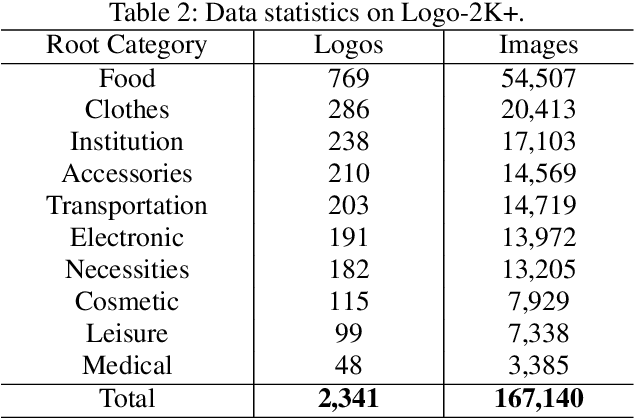
Logo classification has gained increasing attention for its various applications, such as copyright infringement detection, product recommendation and contextual advertising. Compared with other types of object images, the real-world logo images have larger variety in logo appearance and more complexity in their background. Therefore, recognizing the logo from images is challenging. To support efforts towards scalable logo classification task, we have curated a dataset, Logo-2K+, a new large-scale publicly available real-world logo dataset with 2,341 categories and 167,140 images. Compared with existing popular logo datasets, such as FlickrLogos-32 and LOGO-Net, Logo-2K+ has more comprehensive coverage of logo categories and larger quantity of logo images. Moreover, we propose a Discriminative Region Navigation and Augmentation Network (DRNA-Net), which is capable of discovering more informative logo regions and augmenting these image regions for logo classification. DRNA-Net consists of four sub-networks: the navigator sub-network first selected informative logo-relevant regions guided by the teacher sub-network, which can evaluate its confidence belonging to the ground-truth logo class. The data augmentation sub-network then augments the selected regions via both region cropping and region dropping. Finally, the scrutinizer sub-network fuses features from augmented regions and the whole image for logo classification. Comprehensive experiments on Logo-2K+ and other three existing benchmark datasets demonstrate the effectiveness of proposed method. Logo-2K+ and the proposed strong baseline DRNA-Net are expected to further the development of scalable logo image recognition, and the Logo-2K+ dataset can be found at https://github.com/msn199959/Logo-2k-plus-Dataset.