 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Consistency Policy Optimization for Reinforcement Learning of LLM Agents
Jun 24, 2026Group-based reinforcement learning effectively post-trains LLM agents for long-horizon, sparse-reward tasks by deriving step-level credit from trajectory outcomes. However, this ties a step's credit to its rollout's final outcome: semantically near-identical intermediate steps receive opposite credit depending on whether their trajectory eventually succeeded or failed. Such semantic credit inconsistency sends conflicting gradients to similar actions and wastes the partially-correct progress inside failed rollouts. Motivated by this, we propose Semantic Consistency Policy Optimization (SCPO), a value-free reward-shaping method that mitigates this inconsistency by recovering step-level credit from successful siblings in the same rollout group. Concretely, SCPO scores each failed step against a successful sibling and adds positive step-level credit for new progress along that sibling. On ALFWorld and WebShop, SCPO matches or exceeds strong group-based baselines, reaching 93.7+/-4.1 percent success on ALFWorld and 74.8+/-2.0 percent on WebShop at 1.5B parameters, with gains concentrated on the hardest multi-step tasks.
Unveiling Language Routing Isolation in Multilingual MoE Models for Interpretable Subnetwork Adaptation
Apr 04, 2026Mixture-of-Experts (MoE) models exhibit striking performance disparities across languages, yet the internal mechanisms driving these gaps remain poorly understood. In this work, we conduct a systematic analysis of expert routing patterns in MoE models, revealing a phenomenon we term Language Routing Isolation, in which high- and low-resource languages tend to activate largely disjoint expert sets. Through layer-stratified analysis, we further show that routing patterns exhibit a layer-wise convergence-divergence pattern across model depth. Building on these findings, we propose RISE (Routing Isolation-guided Subnetwork Enhancement), a framework that exploits routing isolation to identify and adapt language-specific expert subnetworks. RISE applies a tripartite selection strategy, using specificity scores to identify language-specific experts in shallow and deep layers and overlap scores to select universal experts in middle layers. By training only the selected subnetwork while freezing all other parameters, RISE substantially improves low-resource language performance while preserving capabilities in other languages. Experiments on 10 languages demonstrate that RISE achieves target-language F1 gains of up to 10.85% with minimal cross-lingual degradation.
Optimal Expert-Attention Allocation in Mixture-of-Experts: A Scalable Law for Dynamic Model Design
Mar 11, 2026This paper presents a novel extension of neural scaling laws to Mixture-of-Experts (MoE) models, focusing on the optimal allocation of compute between expert and attention sub-layers. As MoE architectures have emerged as an efficient method for scaling model capacity without proportionally increasing computation, determining the optimal expert-attention compute ratio becomes critical. We define the ratio $r$ as the fraction of total FLOPs per token dedicated to the expert layers versus the attention layers, and explore how this ratio interacts with the overall compute budget and model sparsity. Through extensive experiments with GPT-style MoE Transformers, we empirically find that the optimal ratio $r^*$ follows a power-law relationship with total compute and varies with sparsity. Our analysis leads to an explicit formula for $r^*$, enabling precise control over the expert-attention compute allocation. We generalize the Chinchilla scaling law by incorporating this architectural parameter, providing a new framework for tuning MoE models beyond size and data. Our findings offer practical guidelines for designing efficient MoE models, optimizing performance while respecting fixed compute budgets.
Deconstructing Pre-training: Knowledge Attribution Analysis in MoE and Dense Models
Jan 13, 2026Mixture-of-Experts (MoE) architectures decouple model capacity from per-token computation, enabling scaling beyond the computational limits imposed by dense scaling laws. Yet how MoE architectures shape knowledge acquisition during pre-training, and how this process differs from dense architectures, remains unknown. To address this issue, we introduce Gated-LPI (Log-Probability Increase), a neuron-level attribution metric that decomposes log-probability increase across neurons. We present a time-resolved comparison of knowledge acquisition dynamics in MoE and dense architectures, tracking checkpoints over 1.2M training steps (~ 5.0T tokens) and 600K training steps (~ 2.5T tokens), respectively. Our experiments uncover three patterns: (1) Low-entropy backbone. The top approximately 1% of MoE neurons capture over 45% of positive updates, forming a high-utility core, which is absent in the dense baseline. (2) Early consolidation. The MoE model locks into a stable importance profile within < 100K steps, whereas the dense model remains volatile throughout training. (3) Functional robustness. Masking the ten most important MoE attention heads reduces relational HIT@10 by < 10%, compared with > 50% for the dense model, showing that sparsity fosters distributed -- rather than brittle -- knowledge storage. These patterns collectively demonstrate that sparsity fosters an intrinsically stable and distributed computational backbone from early in training, helping bridge the gap between sparse architectures and training-time interpretability.
Decoding Knowledge Attribution in Mixture-of-Experts: A Framework of Basic-Refinement Collaboration and Efficiency Analysis
May 30, 2025The interpretability of Mixture-of-Experts (MoE) models, especially those with heterogeneous designs, remains underexplored. Existing attribution methods for dense models fail to capture dynamic routing-expert interactions in sparse MoE architectures. To address this issue, we propose a cross-level attribution algorithm to analyze sparse MoE architectures (Qwen 1.5-MoE, OLMoE, Mixtral-8x7B) against dense models (Qwen 1.5-7B, Llama-7B, Mixtral-7B). Results show MoE models achieve 37% higher per-layer efficiency via a "mid-activation, late-amplification" pattern: early layers screen experts, while late layers refine knowledge collaboratively. Ablation studies reveal a "basic-refinement" framework--shared experts handle general tasks (entity recognition), while routed experts specialize in domain-specific processing (geographic attributes). Semantic-driven routing is evidenced by strong correlations between attention heads and experts (r=0.68), enabling task-aware coordination. Notably, architectural depth dictates robustness: deep Qwen 1.5-MoE mitigates expert failures (e.g., 43% MRR drop in geographic tasks when blocking top-10 experts) through shared expert redundancy, whereas shallow OLMoE suffers severe degradation (76% drop). Task sensitivity further guides design: core-sensitive tasks (geography) require concentrated expertise, while distributed-tolerant tasks (object attributes) leverage broader participation. These insights advance MoE interpretability, offering principles to balance efficiency, specialization, and robustness.
Unveiling Instruction-Specific Neurons & Experts: An Analytical Framework for LLM's Instruction-Following Capabilities
May 27, 2025The finetuning of Large Language Models (LLMs) has significantly advanced their instruction-following capabilities, yet the underlying computational mechanisms driving these improvements remain poorly understood. This study systematically examines how fine-tuning reconfigures LLM computations by isolating and analyzing instruction-specific sparse components, i.e., neurons in dense models and both neurons and experts in Mixture-of-Experts (MoE) architectures. In particular, we introduce HexaInst, a carefully curated and balanced instructional dataset spanning six distinct categories, and propose SPARCOM, a novel analytical framework comprising three key contributions: (1) a method for identifying these sparse components, (2) an evaluation of their functional generality and uniqueness, and (3) a systematic comparison of their alterations. Through experiments, we demonstrate functional generality, uniqueness, and the critical role of these components in instruction execution. By elucidating the relationship between fine-tuning-induced adaptations and sparse computational substrates, this work provides deeper insights into how LLMs internalize instruction-following behavior for the trustworthy LLM community.
LoTA-QAF: Lossless Ternary Adaptation for Quantization-Aware Fine-Tuning
May 24, 2025Quantization and fine-tuning are crucial for deploying large language models (LLMs) on resource-constrained edge devices. However, fine-tuning quantized models presents significant challenges, primarily stemming from: First, the mismatch in data types between the low-precision quantized weights (e.g., 4-bit) and the high-precision adaptation weights (e.g., 16-bit). This mismatch limits the computational efficiency advantage offered by quantized weights during inference. Second, potential accuracy degradation when merging these high-precision adaptation weights into the low-precision quantized weights, as the adaptation weights often necessitate approximation or truncation. Third, as far as we know, no existing methods support the lossless merging of adaptation while adjusting all quantized weights. To address these challenges, we introduce lossless ternary adaptation for quantization-aware fine-tuning (LoTA-QAF). This is a novel fine-tuning method specifically designed for quantized LLMs, enabling the lossless merging of ternary adaptation weights into quantized weights and the adjustment of all quantized weights. LoTA-QAF operates through a combination of: i) A custom-designed ternary adaptation (TA) that aligns ternary weights with the quantization grid and uses these ternary weights to adjust quantized weights. ii) A TA-based mechanism that enables the lossless merging of adaptation weights. iii) Ternary signed gradient descent (t-SignSGD) for updating the TA weights. We apply LoTA-QAF to Llama-3.1/3.3 and Qwen-2.5 model families and validate its effectiveness on several downstream tasks. On the MMLU benchmark, our method effectively recovers performance for quantized models, surpassing 16-bit LoRA by up to 5.14\%. For task-specific fine-tuning, 16-bit LoRA achieves superior results, but LoTA-QAF still outperforms other methods.
Internal Chain-of-Thought: Empirical Evidence for Layer-wise Subtask Scheduling in LLMs
May 20, 2025
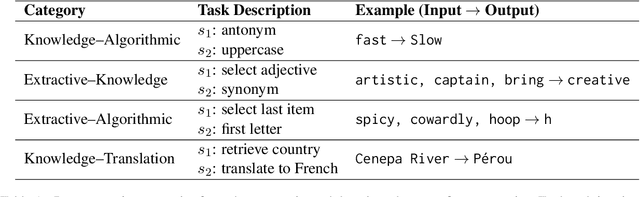


We show that large language models (LLMs) exhibit an $\textit{internal chain-of-thought}$: they sequentially decompose and execute composite tasks layer-by-layer. Two claims ground our study: (i) distinct subtasks are learned at different network depths, and (ii) these subtasks are executed sequentially across layers. On a benchmark of 15 two-step composite tasks, we employ layer-from context-masking and propose a novel cross-task patching method, confirming (i). To examine claim (ii), we apply LogitLens to decode hidden states, revealing a consistent layerwise execution pattern. We further replicate our analysis on the real-world $\text{TRACE}$ benchmark, observing the same stepwise dynamics. Together, our results enhance LLMs transparency by showing their capacity to internally plan and execute subtasks (or instructions), opening avenues for fine-grained, instruction-level activation steering.
Capturing Nuanced Preferences: Preference-Aligned Distillation for Small Language Models
Feb 20, 2025



Aligning small language models (SLMs) with human values typically involves distilling preference knowledge from large language models (LLMs). However, existing distillation methods model preference knowledge in teacher LLMs by comparing pairwise responses, overlooking the extent of difference between responses. This limitation hinders student SLMs from capturing the nuanced preferences for multiple responses. In this paper, we propose a Preference-Aligned Distillation (PAD) framework, which models teacher's preference knowledge as a probability distribution over all potential preferences, thereby providing more nuanced supervisory signals. Our insight in developing PAD is rooted in the demonstration that language models can serve as reward functions, reflecting their intrinsic preferences. Based on this, PAD comprises three key steps: (1) sampling diverse responses using high-temperature; (2) computing rewards for both teacher and student to construct their intrinsic preference; and (3) training the student's intrinsic preference distribution to align with the teacher's. Experiments on four mainstream alignment benchmarks demonstrate that PAD consistently and significantly outperforms existing approaches, achieving over 20\% improvement on AlpacaEval 2 and Arena-Hard, indicating superior alignment with human preferences. Notably, on MT-Bench, using the \textsc{Gemma} model family, the student trained by PAD surpasses its teacher, further validating the effectiveness of our PAD.
The Fine Line: Navigating Large Language Model Pretraining with Down-streaming Capability Analysis
Apr 01, 2024



Uncovering early-stage metrics that reflect final model performance is one core principle for large-scale pretraining. The existing scaling law demonstrates the power-law correlation between pretraining loss and training flops, which serves as an important indicator of the current training state for large language models. However, this principle only focuses on the model's compression properties on the training data, resulting in an inconsistency with the ability improvements on the downstream tasks. Some follow-up works attempted to extend the scaling-law to more complex metrics (such as hyperparameters), but still lacked a comprehensive analysis of the dynamic differences among various capabilities during pretraining. To address the aforementioned limitations, this paper undertakes a comprehensive comparison of model capabilities at various pretraining intermediate checkpoints. Through this analysis, we confirm that specific downstream metrics exhibit similar training dynamics across models of different sizes, up to 67 billion parameters. In addition to our core findings, we've reproduced Amber and OpenLLaMA, releasing their intermediate checkpoints. This initiative offers valuable resources to the research community and facilitates the verification and exploration of LLM pretraining by open-source researchers. Besides, we provide empirical summaries, including performance comparisons of different models and capabilities, and tuition of key metrics for different training phases. Based on these findings, we provide a more user-friendly strategy for evaluating the optimization state, offering guidance for establishing a stable pretraining process.