 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CAIS-DMA: A Decision-Making Assistant for Collaborative AI Systems
Nov 08, 2023
A Collaborative Artificial Intelligence System (CAIS) is a cyber-physical system that learns actions in collaboration with humans in a shared environment to achieve a common goal. In particular, a CAIS is equipped with an AI model to support the decision-making process of this collaboration. When an event degrades the performance of CAIS (i.e., a disruptive event), this decision-making process may be hampered or even stopped. Thus, it is of paramount importance to monitor the learning of the AI model, and eventually support its decision-making process in such circumstances. This paper introduces a new methodology to automatically support the decision-making process in CAIS when the system experiences performance degradation after a disruptive event. To this aim, we develop a framework that consists of three components: one manages or simulates CAIS's environment and disruptive events, the second automates the decision-making process, and the third provides a visual analysis of CAIS behavior. Overall, our framework automatically monitors the decision-making process, intervenes whenever a performance degradation occurs, and recommends the next action. We demonstrate our framework by implementing an example with a real-world collaborative robot, where the framework recommends the next action that balances between minimizing the recovery time (i.e., resilience), and minimizing the energy adverse effects (i.e., greenness).
Deep learning as a tool for quantum error reduction in quantum image processing
Nov 08, 2023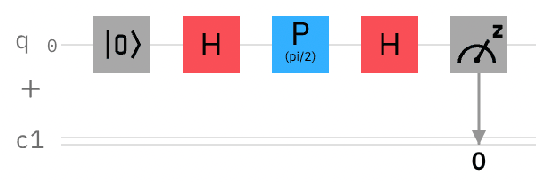
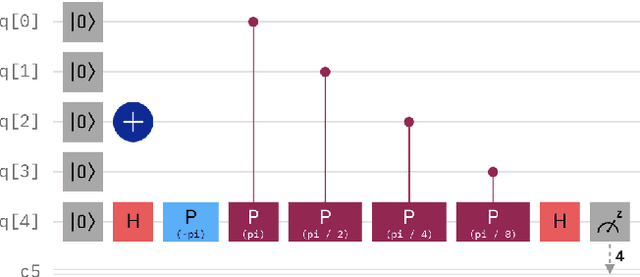

Despite the limited availability and quantum volume of quantum computers, quantum image representation is a widely researched area. Currently developed methods use quantum entanglement to encode information about pixel positions. These methods range from using the angle parameter of the rotation gate (e.g., the Flexible Representation of Quantum Images, FRQI), sequences of qubits (e.g., Novel Enhanced Quantum Representation, NEQR), or the angle parameter of the phase shift gates (e.g., Local Phase Image Quantum Encoding, LPIQE) for storing color information. All these methods are significantly affected by decoherence and other forms of quantum noise, which is an inseparable part of quantum computing in the noisy intermediate-scale quantum era. These phenomena can highly influence the measurements and result in extracted images that are visually dissimilar to the originals. Because this process is at its foundation quantum, the computational reversal of this process is possible. There are many methods for error correction, mitigation, and reduction, but all of them use quantum computer time or additional qubits to achieve the desired result. We report the successful use of a generative adversarial network trained for image-to-image translation, in conjunction with Phase Distortion Unraveling error reduction method, for reducing overall error in images encoded using LPIQE.
Massive Editing for Large Language Models via Meta Learning
Nov 08, 2023While large language models (LLMs) have enabled learning knowledge from the pre-training corpora, the acquired knowledge may be fundamentally incorrect or outdated over time, which necessitates rectifying the knowledge of the language model (LM) after the training. A promising approach involves employing a hyper-network to generate parameter shift, whereas existing hyper-networks suffer from inferior scalability in synchronous editing operation amount. To mitigate the problem, we propose the MAssive Language Model Editing Network (MALMEN), which formulates the parameter shift aggregation as the least square problem, subsequently updating the LM parameters using the normal equation. To accommodate editing multiple facts simultaneously with limited memory budgets, we separate the computation on the hyper-network and LM, enabling arbitrary batch size on both neural networks. Our method is evaluated by editing up to thousands of facts on LMs with different architectures, i.e., BERT-base, GPT-2, T5-XL (2.8B), and GPT-J (6B), across various knowledge-intensive NLP tasks, i.e., closed book fact-checking and question answering. Remarkably, MALMEN is capable of editing hundreds of times more facts than strong baselines with the identical hyper-network architecture and outperforms editor specifically designed for GPT. Our code is available at https://github.com/ChenmienTan/malmen.
Likelihood Ratio Confidence Sets for Sequential Decision Making
Nov 08, 2023Certifiable, adaptive uncertainty estimates for unknown quantities are an essential ingredient of sequential decision-making algorithms. Standard approaches rely on problem-dependent concentration results and are limited to a specific combination of parameterization, noise family, and estimator. In this paper, we revisit the likelihood-based inference principle and propose to use likelihood ratios to construct any-time valid confidence sequences without requiring specialized treatment in each application scenario. Our method is especially suitable for problems with well-specified likelihoods, and the resulting sets always maintain the prescribed coverage in a model-agnostic manner. The size of the sets depends on a choice of estimator sequence in the likelihood ratio. We discuss how to provably choose the best sequence of estimators and shed light on connections to online convex optimization with algorithms such as Follow-the-Regularized-Leader. To counteract the initially large bias of the estimators, we propose a reweighting scheme that also opens up deployment in non-parametric settings such as RKHS function classes. We provide a non-asymptotic analysis of the likelihood ratio confidence sets size for generalized linear models, using insights from convex duality and online learning. We showcase the practical strength of our method on generalized linear bandit problems, survival analysis, and bandits with various additive noise distributions.
Exploring and Analyzing Wildland Fire Data Via Machine Learning Techniques
Nov 09, 2023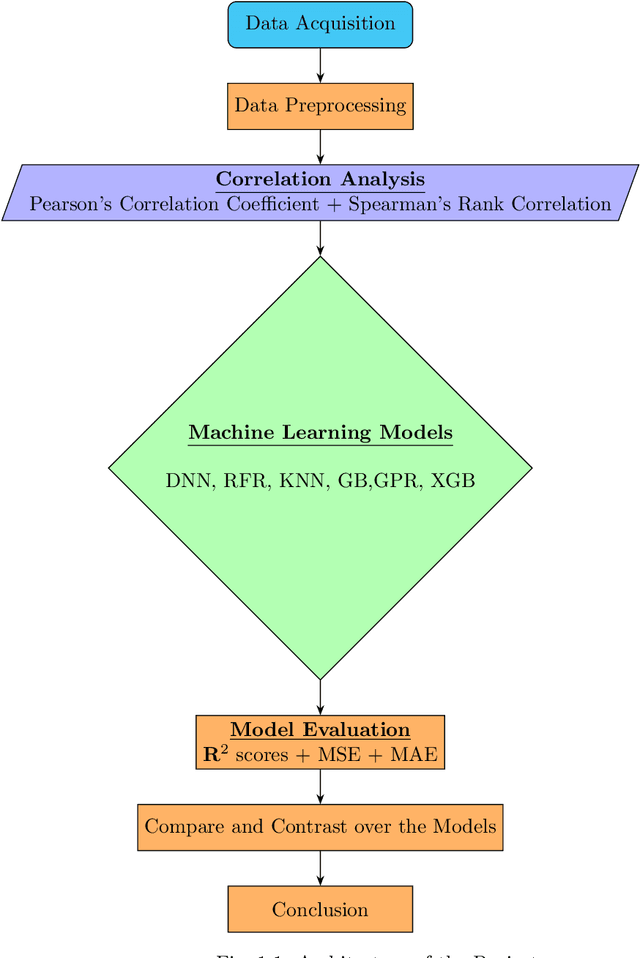

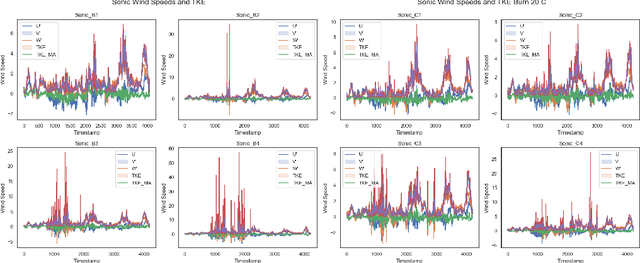
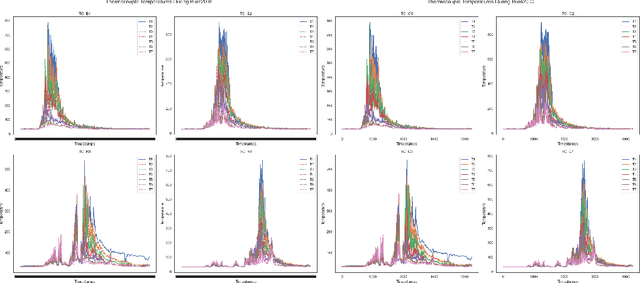
This research project investigated the correlation between a 10 Hz time series of thermocouple temperatures and turbulent kinetic energy (TKE) computed from wind speeds collected from a small experimental prescribed burn at the Silas Little Experimental Forest in New Jersey, USA. The primary objective of this project was to explore the potential for using thermocouple temperatures as predictors for estimating the TKE produced by a wildland fire. Machine learning models, including Deep Neural Networks, Random Forest Regressor, Gradient Boosting, and Gaussian Process Regressor, are employed to assess the potential for thermocouple temperature perturbations to predict TKE values. Data visualization and correlation analyses reveal patterns and relationships between thermocouple temperatures and TKE, providing insight into the underlying dynamics. The project achieves high accuracy in predicting TKE by employing various machine learning models despite a weak correlation between the predictors and the target variable. The results demonstrate significant success, particularly from regression models, in accurately estimating the TKE. The research findings contribute to fire behavior and smoke modeling science, emphasizing the importance of incorporating machine learning approaches and identifying complex relationships between fine-scale fire behavior and turbulence. Accurate TKE estimation using thermocouple temperatures allows for the refinement of models that can inform decision-making in fire management strategies, facilitate effective risk mitigation, and optimize fire management efforts. This project highlights the valuable role of machine learning techniques in analyzing wildland fire data, showcasing their potential to advance fire research and management practices.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023
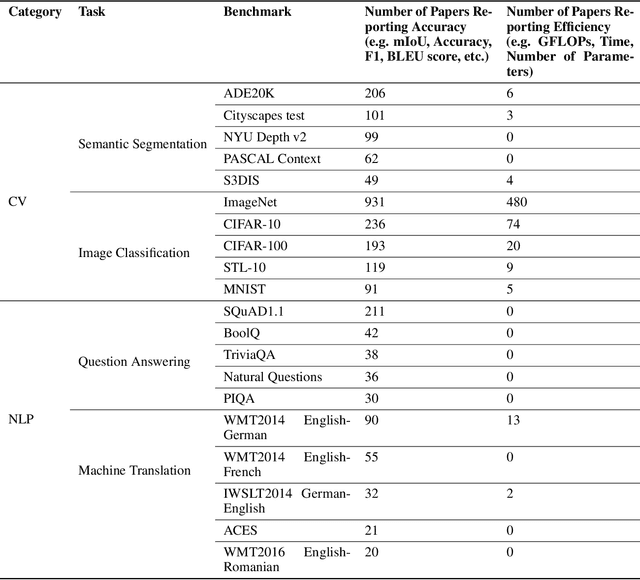
Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving
Nov 09, 2023



The pursuit of autonomous driving technology hinges on the sophisticated integration of perception, decision-making, and control systems. Traditional approaches, both data-driven and rule-based, have been hindered by their inability to grasp the nuance of complex driving environments and the intentions of other road users. This has been a significant bottleneck, particularly in the development of common sense reasoning and nuanced scene understanding necessary for safe and reliable autonomous driving. The advent of Visual Language Models (VLM) represents a novel frontier in realizing fully autonomous vehicle driving. This report provides an exhaustive evaluation of the latest state-of-the-art VLM, \modelnamefull, and its application in autonomous driving scenarios. We explore the model's abilities to understand and reason about driving scenes, make decisions, and ultimately act in the capacity of a driver. Our comprehensive tests span from basic scene recognition to complex causal reasoning and real-time decision-making under varying conditions. Our findings reveal that \modelname demonstrates superior performance in scene understanding and causal reasoning compared to existing autonomous systems. It showcases the potential to handle out-of-distribution scenarios, recognize intentions, and make informed decisions in real driving contexts. However, challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks. These limitations underscore the need for further research and development. Project is now available on GitHub for interested parties to access and utilize: \url{https://github.com/PJLab-ADG/GPT4V-AD-Exploration}
Robust Retraining-free GAN Fingerprinting via Personalized Normalization
Nov 09, 2023In recent years, there has been significant growth in the commercial applications of generative models, licensed and distributed by model developers to users, who in turn use them to offer services. In this scenario, there is a need to track and identify the responsible user in the presence of a violation of the license agreement or any kind of malicious usage. Although there are methods enabling Generative Adversarial Networks (GANs) to include invisible watermarks in the images they produce, generating a model with a different watermark, referred to as a fingerprint, for each user is time- and resource-consuming due to the need to retrain the model to include the desired fingerprint. In this paper, we propose a retraining-free GAN fingerprinting method that allows model developers to easily generate model copies with the same functionality but different fingerprints. The generator is modified by inserting additional Personalized Normalization (PN) layers whose parameters (scaling and bias) are generated by two dedicated shallow networks (ParamGen Nets) taking the fingerprint as input. A watermark decoder is trained simultaneously to extract the fingerprint from the generated images. The proposed method can embed different fingerprints inside the GAN by just changing the input of the ParamGen Nets and performing a feedforward pass, without finetuning or retraining. The performance of the proposed method in terms of robustness against both model-level and image-level attacks is also superior to the state-of-the-art.
Exploiting Correlated Auxiliary Feedback in Parameterized Bandits
Nov 05, 2023We study a novel variant of the parameterized bandits problem in which the learner can observe additional auxiliary feedback that is correlated with the observed reward. The auxiliary feedback is readily available in many real-life applications, e.g., an online platform that wants to recommend the best-rated services to its users can observe the user's rating of service (rewards) and collect additional information like service delivery time (auxiliary feedback). In this paper, we first develop a method that exploits auxiliary feedback to build a reward estimator with tight confidence bounds, leading to a smaller regret. We then characterize the regret reduction in terms of the correlation coefficient between reward and its auxiliary feedback. Experimental results in different settings also verify the performance gain achieved by our proposed method.
Serving Time: Real-Time, Safe Motion Planning and Control for Manipulation of Unsecured Objects
Sep 06, 2023A key challenge to ensuring the rapid transition of robotic systems from the industrial sector to more ubiquitous applications is the development of algorithms that can guarantee safe operation while in close proximity to humans. Motion planning and control methods, for instance, must be able to certify safety while operating in real-time in arbitrary environments and in the presence of model uncertainty. This paper proposes Wrench Analysis for Inertial Transport using Reachability (WAITR), a certifiably safe motion planning and control framework for serial link manipulators that manipulate unsecured objects in arbitrary environments. WAITR uses reachability analysis to construct over-approximations of the contact wrench applied to unsecured objects, which captures uncertainty in the manipulator dynamics, the object dynamics, and contact parameters such as the coefficient of friction. An optimization problem formulation is presented that can be solved in real-time to generate provably-safe motions for manipulating the unsecured objects. This paper illustrates that WAITR outperforms state of the art methods in a variety of simulation experiments and demonstrates its performance in the real-world.