 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient On-Policy Distillation for Automatic Speech Recognition
May 27, 2026Building competitive automatic speech recognition (ASR) models usually requires large-scale au- dio supervision, which makes reproduction and specialization expensive. We study Ark-ASR, a 0.6B- parameter audio-conditioned language model trained with 100k hours of speech, and examine whether a strong Qwen-ASR teacher can transfer additional recognition capability through on-policy distillation. Across Mandarin and English ASR benchmarks, the proposed training recipe consistently improves over supervised fine-tuning alone and outperforms the same-scale Qwen3-ASR-0.6B baseline on four of five evaluation sets. This is achieved with only 100k hours of speech, compared with the 20M hours of super- vised audio reported for the Qwen3-Omni AuT encoder. The larger Qwen3-ASR-1.7B remains stronger, but the results show that teacher-guided on-policy training can substantially close the gap for compact ASR models under a much smaller audio budget. A support-overlap diagnostic further suggests that the teacher-data stage improves local student-teacher compatibility, matching recent analyses of when on-policy distillation is effective.
Tiny-Engram: Trigger-Indexed Concept Tables for Generative Vision
May 19, 2026Current personalization methods for generative vision models typically encode new concepts through continuous adapters or weight updates, yet provide limited control over whether and when a concept should be retrieved. In this work, we introduce Tiny-Engram, a compact trigger-indexed concept table that gives visual memories an explicit lexical address and activation boundary inside frozen image and video generators. Tiny-Engram parameterizes each concept as a small set of memory entries indexed by registered n-gram matches, which modulate text-encoder hidden states only within the matched trigger region. Outside this lexical support, the conditioning pathway is identical to that of the frozen base model. Across both single-encoder latent diffusion and multi-encoder diffusion-transformer backbones, this formulation binds a rare trigger phrase to a target identity while preserving compositional control from the surrounding prompt. We further evaluate the same table-based memory in a text-conditioned video generation setting, where the trigger path reliably alters the generated subject but fine-grained identity persistence across held-out video prompts remains limited. Taken together, these results suggest that small, explicitly addressed concept tables are a practical route to modular visual personalization, with strongest evidence in image generation. For video diffusion, the remaining gap points to a broader requirement: temporally stable identity likely depends on tighter coupling between text-side memory and the evolving visual state, motivating future work on memory injection beyond the text-conditioning interface.
Unifying Speech Recognition, Synthesis and Conversion with Autoregressive Transformers
Jan 15, 2026Traditional speech systems typically rely on separate, task-specific models for text-to-speech (TTS), automatic speech recognition (ASR), and voice conversion (VC), resulting in fragmented pipelines that limit scalability, efficiency, and cross-task generalization. In this paper, we present General-Purpose Audio (GPA), a unified audio foundation model that integrates multiple core speech tasks within a single large language model (LLM) architecture. GPA operates on a shared discrete audio token space and supports instruction-driven task induction, enabling a single autoregressive model to flexibly perform TTS, ASR, and VC without architectural modifications. This unified design combines a fully autoregressive formulation over discrete speech tokens, joint multi-task training across speech domains, and a scalable inference pipeline that achieves high concurrency and throughput. The resulting model family supports efficient multi-scale deployment, including a lightweight 0.3B-parameter variant optimized for edge and resource-constrained environments. Together, these design choices demonstrate that a unified autoregressive architecture can achieve competitive performance across diverse speech tasks while remaining viable for low-latency, practical deployment.
PrivateLoRA For Efficient Privacy Preserving LLM
Nov 23, 2023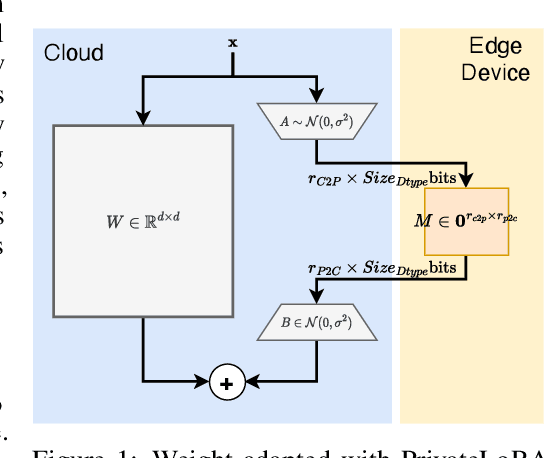
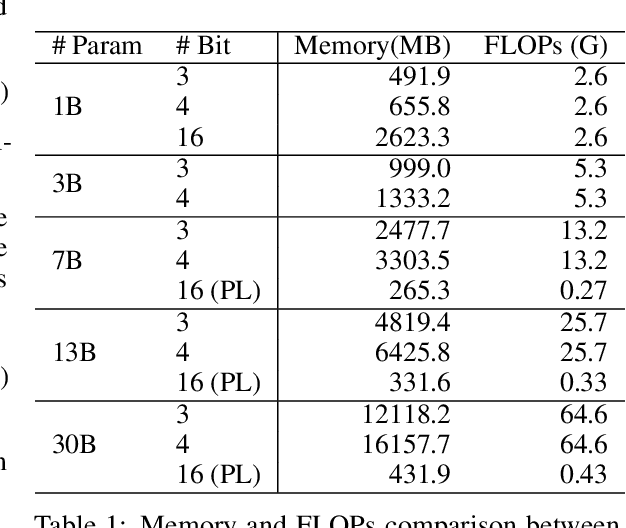
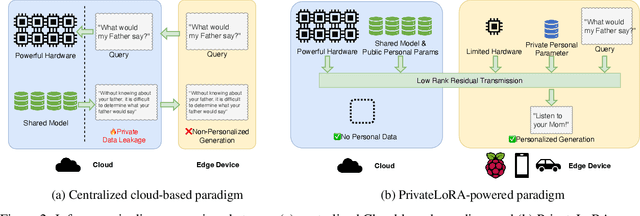
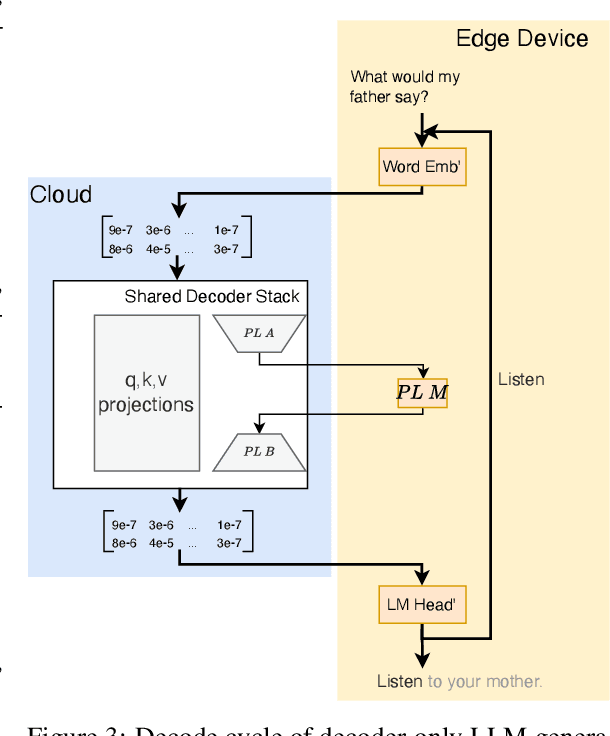
End users face a choice between privacy and efficiency in current Large Language Model (LLM) service paradigms. In cloud-based paradigms, users are forced to compromise data locality for generation quality and processing speed. Conversely, edge device paradigms maintain data locality but fail to deliver satisfactory performance. In this work, we propose a novel LLM service paradigm that distributes privacy-sensitive computation on edge devices and shared computation in the cloud. Only activations are transmitted between the central cloud and edge devices to ensure data locality. Our core innovation, PrivateLoRA, addresses the challenging communication overhead by exploiting the low rank of residual activations, achieving over 95% communication reduction. Consequently, PrivateLoRA effectively maintains data locality and is extremely resource efficient. Under standard 5G networks, PrivateLoRA achieves throughput over 300% of device-only solutions for 7B models and over 80% of an A100 GPU for 33B models. PrivateLoRA also provides tuning performance comparable to LoRA for advanced personalization. Our approach democratizes access to state-of-the-art generative AI for edge devices, paving the way for more tailored LLM experiences for the general public. To our knowledge, our proposed framework is the first efficient and privacy-preserving LLM solution in the literature.
MultiLoRA: Democratizing LoRA for Better Multi-Task Learning
Nov 20, 2023



LoRA achieves remarkable resource efficiency and comparable performance when adapting LLMs for specific tasks. Since ChatGPT demonstrated superior performance on various tasks, there has been a growing desire to adapt one model for all tasks. However, the explicit low-rank of LoRA limits the adaptation performance in complex multi-task scenarios. LoRA is dominated by a small number of top singular vectors while fine-tuning decomposes into a set of less important unitary transforms. In this paper, we propose MultiLoRA for better multi-task adaptation by reducing the dominance of top singular vectors observed in LoRA. MultiLoRA scales LoRA modules horizontally and change parameter initialization of adaptation matrices to reduce parameter dependency, thus yields more balanced unitary subspaces. We unprecedentedly construct specialized training data by mixing datasets of instruction follow, natural language understanding, world knowledge, to cover semantically and syntactically different samples. With only 2.5% of additional parameters, MultiLoRA outperforms single LoRA counterparts and fine-tuning on multiple benchmarks and model scales. Further investigation into weight update matrices of MultiLoRA exhibits reduced dependency on top singular vectors and more democratic unitary transform contributions.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Marketing Budget Allocation with Offline Constrained Deep Reinforcement Learning
Sep 06, 2023



We study the budget allocation problem in online marketing campaigns that utilize previously collected offline data. We first discuss the long-term effect of optimizing marketing budget allocation decisions in the offline setting. To overcome the challenge, we propose a novel game-theoretic offline value-based reinforcement learning method using mixed policies. The proposed method reduces the need to store infinitely many policies in previous methods to only constantly many policies, which achieves nearly optimal policy efficiency, making it practical and favorable for industrial usage. We further show that this method is guaranteed to converge to the optimal policy, which cannot be achieved by previous value-based reinforcement learning methods for marketing budget allocation. Our experiments on a large-scale marketing campaign with tens-of-millions users and more than one billion budget verify the theoretical results and show that the proposed method outperforms various baseline methods. The proposed method has been successfully deployed to serve all the traffic of this marketing campaign.
Adversarial Learning for Incentive Optimization in Mobile Payment Marketing
Dec 28, 2021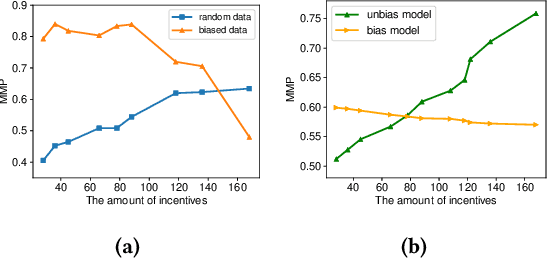
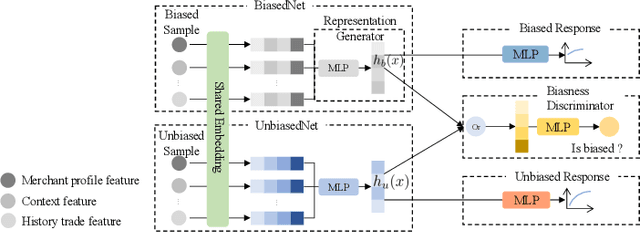
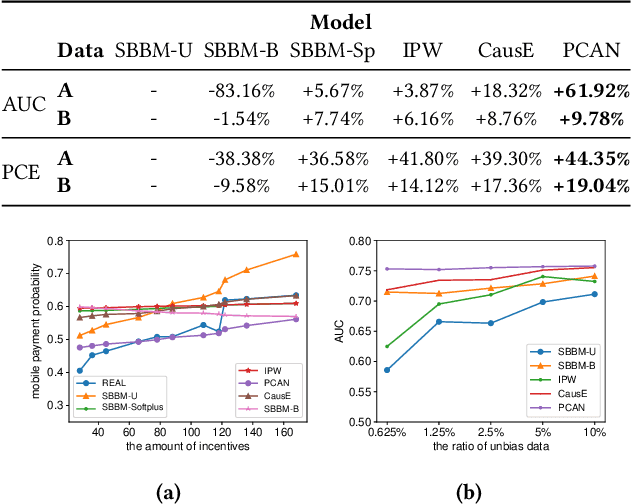
Many payment platforms hold large-scale marketing campaigns, which allocate incentives to encourage users to pay through their applications. To maximize the return on investment, incentive allocations are commonly solved in a two-stage procedure. After training a response estimation model to estimate the users' mobile payment probabilities (MPP), a linear programming process is applied to obtain the optimal incentive allocation. However, the large amount of biased data in the training set, generated by the previous biased allocation policy, causes a biased estimation. This bias deteriorates the performance of the response model and misleads the linear programming process, dramatically degrading the performance of the resulting allocation policy. To overcome this obstacle, we propose a bias correction adversarial network. Our method leverages the small set of unbiased data obtained under a full-randomized allocation policy to train an unbiased model and then uses it to reduce the bias with adversarial learning. Offline and online experimental results demonstrate that our method outperforms state-of-the-art approaches and significantly improves the performance of the resulting allocation policy in a real-world marketing campaign.
A Policy Efficient Reduction Approach to Convex Constrained Deep Reinforcement Learning
Aug 29, 2021
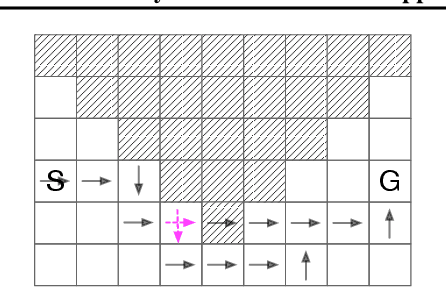
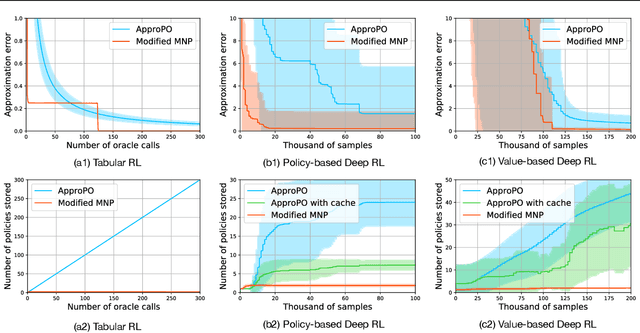

Although well-established in general reinforcement learning (RL), value-based methods are rarely explored in constrained RL (CRL) for their incapability of finding policies that can randomize among multiple actions. To apply value-based methods to CRL, a recent groundbreaking line of game-theoretic approaches uses the mixed policy that randomizes among a set of carefully generated policies to converge to the desired constraint-satisfying policy. However, these approaches require storing a large set of policies, which is not policy efficient, and may incur prohibitive memory costs in constrained deep RL. To address this problem, we propose an alternative approach. Our approach first reformulates the CRL to an equivalent distance optimization problem. With a specially designed linear optimization oracle, we derive a meta-algorithm that solves it using any off-the-shelf RL algorithm and any conditional gradient (CG) type algorithm as subroutines. We then propose a new variant of the CG-type algorithm, which generalizes the minimum norm point (MNP) method. The proposed method matches the convergence rate of the existing game-theoretic approaches and achieves the worst-case optimal policy efficiency. The experiments on a navigation task show that our method reduces the memory costs by an order of magnitude, and meanwhile achieves better performance, demonstrating both its effectiveness and efficiency.
LinkLouvain: Link-Aware A/B Testing and Its Application on Online Marketing Campaign
Feb 03, 2021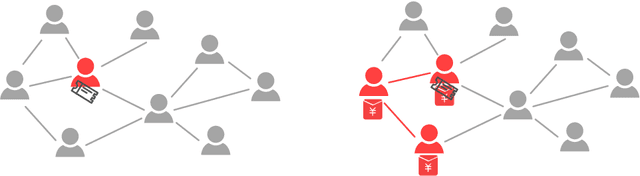
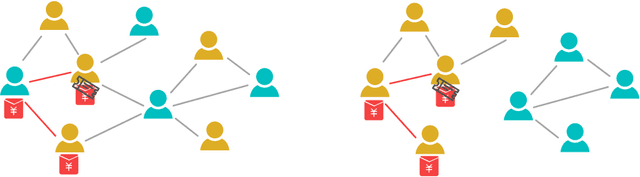
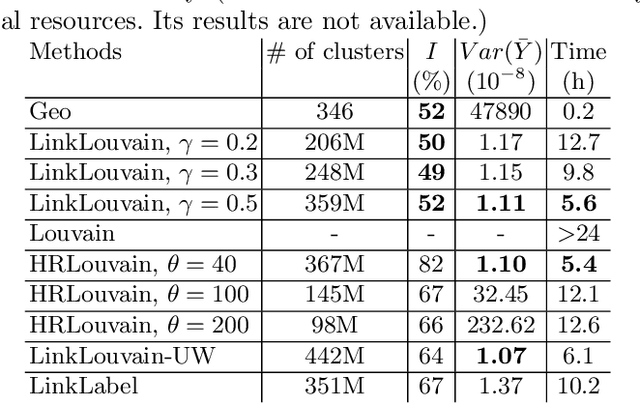
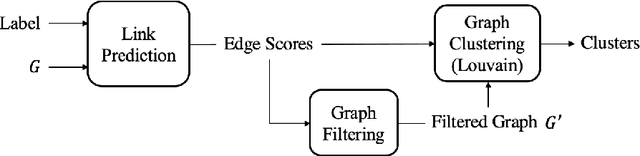
A lot of online marketing campaigns aim to promote user interaction. The average treatment effect (ATE) of campaign strategies need to be monitored throughout the campaign. A/B testing is usually conducted for such needs, whereas the existence of user interaction can introduce interference to normal A/B testing. With the help of link prediction, we design a network A/B testing method LinkLouvain to minimize graph interference and it gives an accurate and sound estimate of the campaign's ATE. In this paper, we analyze the network A/B testing problem under a real-world online marketing campaign, describe our proposed LinkLouvain method, and evaluate it on real-world data. Our method achieves significant performance compared with others and is deployed in the online marketing campaign.