 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
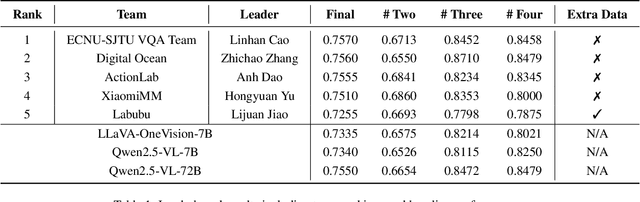
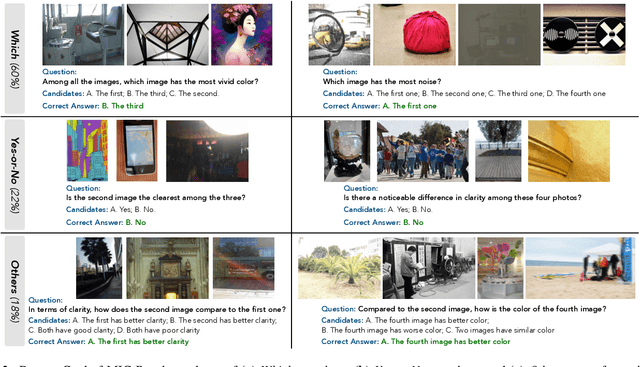
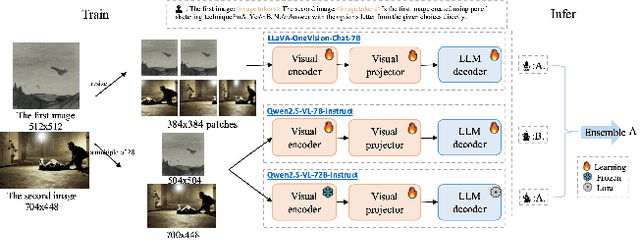
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Instruct Large Language Models to Generate Scientific Literature Survey Step by Step
Aug 15, 2024Abstract. Automatically generating scientific literature surveys is a valuable task that can significantly enhance research efficiency. However, the diverse and complex nature of information within a literature survey poses substantial challenges for generative models. In this paper, we design a series of prompts to systematically leverage large language models (LLMs), enabling the creation of comprehensive literature surveys through a step-by-step approach. Specifically, we design prompts to guide LLMs to sequentially generate the title, abstract, hierarchical headings, and the main content of the literature survey. We argue that this design enables the generation of the headings from a high-level perspective. During the content generation process, this design effectively harnesses relevant information while minimizing costs by restricting the length of both input and output content in LLM queries. Our implementation with Qwen-long achieved third place in the NLPCC 2024 Scientific Literature Survey Generation evaluation task, with an overall score only 0.03% lower than the second-place team. Additionally, our soft heading recall is 95.84%, the second best among the submissions. Thanks to the efficient prompt design and the low cost of the Qwen-long API, our method reduces the expense for generating each literature survey to 0.1 RMB, enhancing the practical value of our method.
Prototypical Contrastive Learning through Alignment and Uniformity for Recommendation
Feb 03, 2024Graph Collaborative Filtering (GCF), one of the most widely adopted recommendation system methods, effectively captures intricate relationships between user and item interactions. Graph Contrastive Learning (GCL) based GCF has gained significant attention as it leverages self-supervised techniques to extract valuable signals from real-world scenarios. However, many methods usually learn the instances of discrimination tasks that involve the construction of contrastive pairs through random sampling. GCL approaches suffer from sampling bias issues, where the negatives might have a semantic structure similar to that of the positives, thus leading to a loss of effective feature representation. To address these problems, we present the \underline{Proto}typical contrastive learning through \underline{A}lignment and \underline{U}niformity for recommendation, which is called \textbf{ProtoAU}. Specifically, we first propose prototypes (cluster centroids) as a latent space to ensure consistency across different augmentations from the origin graph, aiming to eliminate the need for random sampling of contrastive pairs. Furthermore, the absence of explicit negatives means that directly optimizing the consistency loss between instance and prototype could easily result in dimensional collapse issues. Therefore, we propose aligning and maintaining uniformity in the prototypes of users and items as optimization objectives to prevent falling into trivial solutions. Finally, we conduct extensive experiments on four datasets and evaluate their performance on the task of link prediction. Experimental results demonstrate that the proposed ProtoAU outperforms other representative methods. The source codes of our proposed ProtoAU are available at \url{https://github.com/oceanlvr/ProtoAU}.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Distributional Reinforcement Learning with Online Risk-awareness Adaption
Oct 08, 2023



The use of reinforcement learning (RL) in practical applications requires considering sub-optimal outcomes, which depend on the agent's familiarity with the uncertain environment. Dynamically adjusting the level of epistemic risk over the course of learning can tactically achieve reliable optimal policy in safety-critical environments and tackle the sub-optimality of a static risk level. In this work, we introduce a novel framework, Distributional RL with Online Risk Adaption (DRL-ORA), which can quantify the aleatory and epistemic uncertainties compositely and dynamically select the epistemic risk levels via solving a total variation minimization problem online. The risk level selection can be efficiently achieved through grid search using a Follow-The-Leader type algorithm, and its offline oracle is related to "satisficing measure" (in the decision analysis community) under a special modification of the loss function. We show multiple classes of tasks where DRL-ORA outperforms existing methods that rely on either a fixed risk level or manually predetermined risk level adaption. Given the simplicity of our modifications, we believe the framework can be easily incorporated into most RL algorithm variants.
How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
Jan 18, 2023The introduction of ChatGPT has garnered widespread attention in both academic and industrial communities. ChatGPT is able to respond effectively to a wide range of human questions, providing fluent and comprehensive answers that significantly surpass previous public chatbots in terms of security and usefulness. On one hand, people are curious about how ChatGPT is able to achieve such strength and how far it is from human experts. On the other hand, people are starting to worry about the potential negative impacts that large language models (LLMs) like ChatGPT could have on society, such as fake news, plagiarism, and social security issues. In this work, we collected tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas. We call the collected dataset the Human ChatGPT Comparison Corpus (HC3). Based on the HC3 dataset, we study the characteristics of ChatGPT's responses, the differences and gaps from human experts, and future directions for LLMs. We conducted comprehensive human evaluations and linguistic analyses of ChatGPT-generated content compared with that of humans, where many interesting results are revealed. After that, we conduct extensive experiments on how to effectively detect whether a certain text is generated by ChatGPT or humans. We build three different detection systems, explore several key factors that influence their effectiveness, and evaluate them in different scenarios. The dataset, code, and models are all publicly available at https://github.com/Hello-SimpleAI/chatgpt-comparison-detection.