 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid Learning of Time-Series Inverse Dynamics Models for Locally Isotropic Robot Motion
Dec 06, 2022
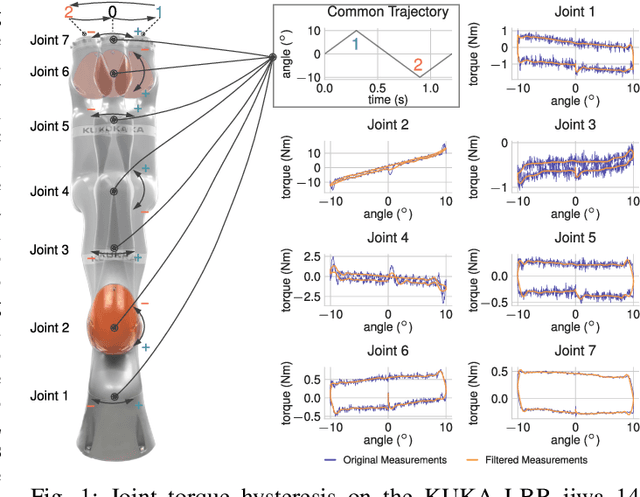
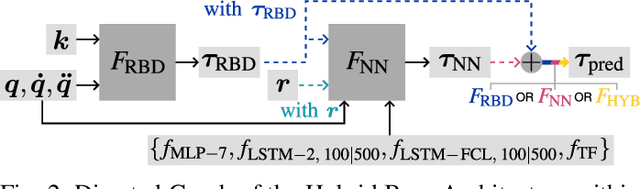
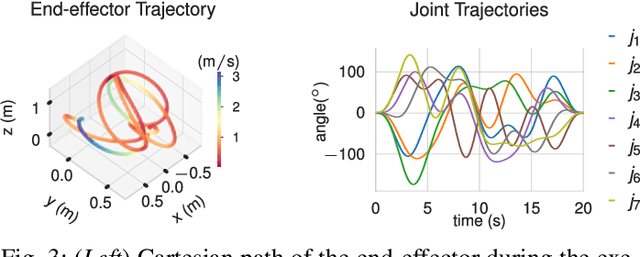
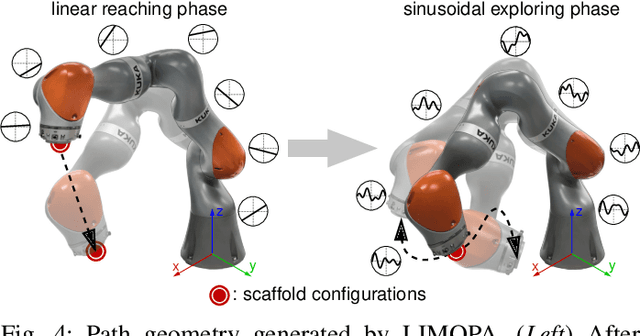
Applications of force control and motion planning often rely on an inverse dynamics model to represent the high-dimensional dynamic behavior of robots during motion. The widespread occurrence of low-velocity, small-scale, locally isotropic motion (LIMO) typically complicates the identification of appropriate models due to the exaggeration of dynamic effects and sensory perturbation caused by complex friction and phenomena of hysteresis, e.g., pertaining to joint elasticity. We propose a hybrid model learning base architecture combining a rigid body dynamics model identified by parametric regression and time-series neural network architectures based on multilayer-perceptron, LSTM, and Transformer topologies. Further, we introduce novel joint-wise rotational history encoding, reinforcing temporal information to effectively model dynamic hysteresis. The models are evaluated on a KUKA iiwa 14 during algorithmically generated locally isotropic movements. Together with the rotational encoding, the proposed architectures outperform state-of-the-art baselines by a magnitude of 10$^3$ yielding an RMSE of 0.14 Nm. Leveraging the hybrid structure and time-series encoding capabilities, our approach allows for accurate torque estimation, indicating its applicability in critically force-sensitive applications during motion sequences exceeding the capacity of conventional inverse dynamics models while retaining trainability in face of scarce data and explainability due to the employed physics model prior.
Virtual Avatar Stream: a cost-down approach to the Metaverse experience
Apr 04, 2023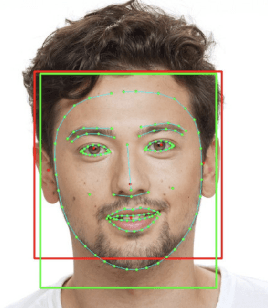

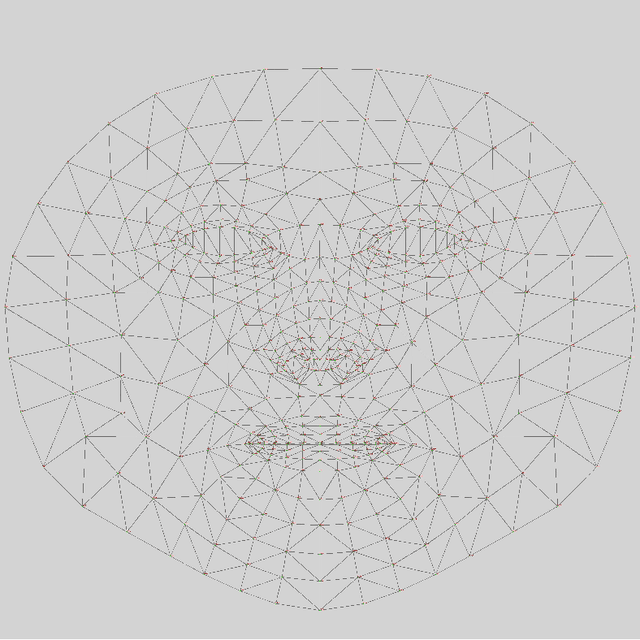
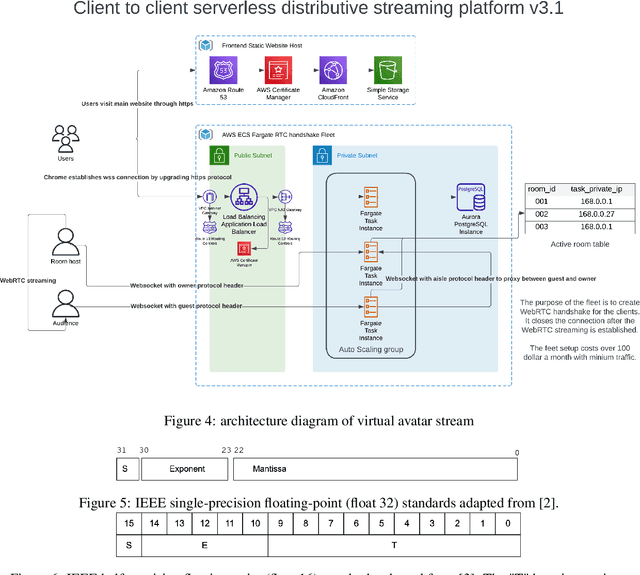
The Metaverse through VR headsets is a rapidly growing concept, but the high cost of entry currently limits access for many users. This project aims to provide an accessible entry point to the immersive Metaverse experience by leveraging web technologies. The platform developed allows users to engage with rendered avatars using only a web browser, microphone, and webcam. By employing the WebGL and MediaPipe face tracking AI model from Google, the application generates real-time 3D face meshes for users. It uses a client-to-client streaming cluster to establish a connection, and clients negotiate SRTP protocol through WebRTC for direct data streaming. Additionally, the project addresses backend challenges through an architecture that is serverless, distributive, auto-scaling, highly resilient, and secure. The platform offers a scalable, hardware-free solution for users to experience a near-immersive Metaverse, with the potential for future integration with game server clusters. This project provides an important step toward a more inclusive Metaverse accessible to a wider audience.
MadEye: Boosting Live Video Analytics Accuracy with Adaptive Camera Configurations
Apr 04, 2023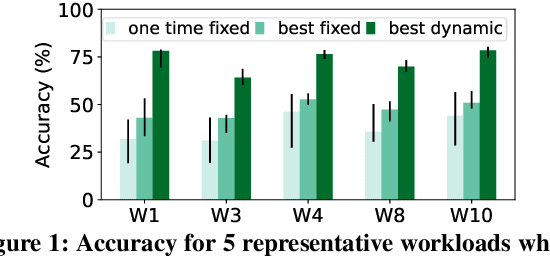

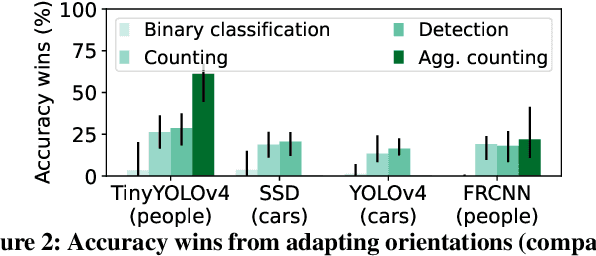

Camera orientations (i.e., rotation and zoom) govern the content that a camera captures in a given scene, which in turn heavily influences the accuracy of live video analytics pipelines. However, existing analytics approaches leave this crucial adaptation knob untouched, instead opting to only alter the way that captured images from fixed orientations are encoded, streamed, and analyzed. We present MadEye, a camera-server system that automatically and continually adapts orientations to maximize accuracy for the workload and resource constraints at hand. To realize this using commodity pan-tilt-zoom (PTZ) cameras, MadEye embeds (1) a search algorithm that rapidly explores the massive space of orientations to identify a fruitful subset at each time, and (2) a novel knowledge distillation strategy to efficiently (with only camera resources) select the ones that maximize workload accuracy. Experiments on diverse workloads show that MadEye boosts accuracy by 2.9-25.7% for the same resource usage, or achieves the same accuracy with 2-3.7x lower resource costs.
Re-Evaluating LiDAR Scene Flow for Autonomous Driving
Apr 04, 2023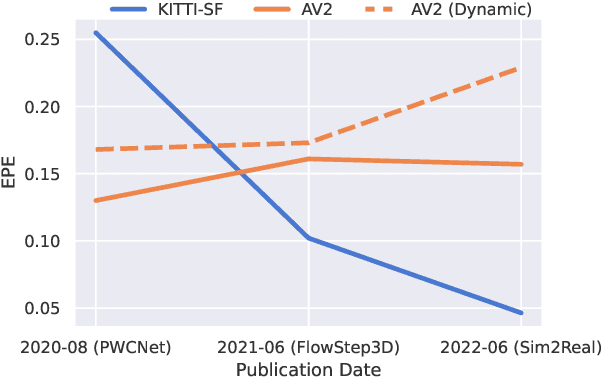
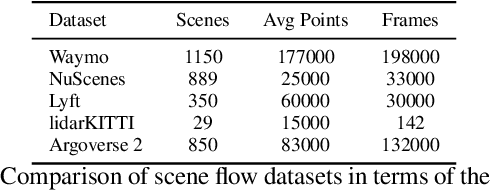
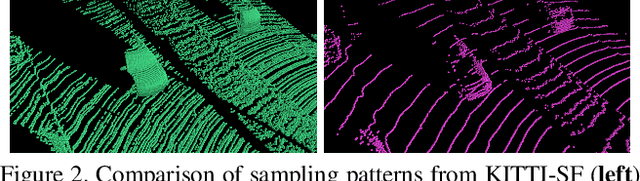
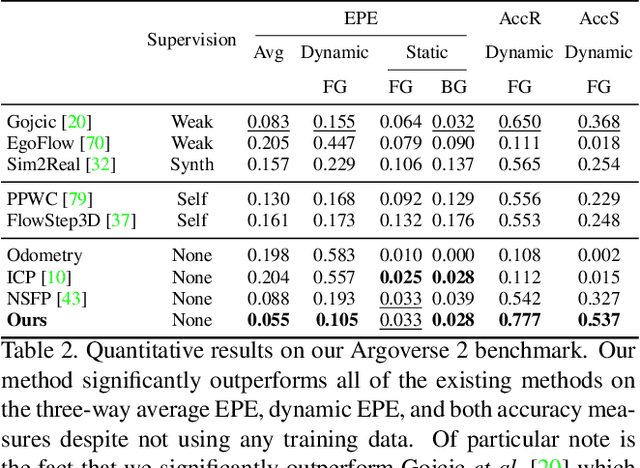
Current methods for self-supervised LiDAR scene flow estimation work poorly on real data. A variety of flaws in common evaluation protocols have caused leading approaches to focus on problems that do not exist in real data. We analyze a suite of recent works and find that despite their focus on deep learning, the main challenges of the LiDAR scene flow problem -- removing the dominant rigid motion and robustly estimating the simple motions that remain -- can be more effectively solved with classical techniques such as ICP motion compensation and enforcing piecewise rigid assumptions. We combine these steps with a test-time optimization method to form a state-of-the-art system that does not require any training data. Because our final approach is dataless, it can be applied on different datasets with diverse LiDAR rigs without retraining. Our proposed approach outperforms all existing methods on Argoverse 2.0, halves the error rate on NuScenes, and even rivals the performance of supervised networks on Waymo and lidarKITTI.
Trace and Pace: Controllable Pedestrian Animation via Guided Trajectory Diffusion
Apr 04, 2023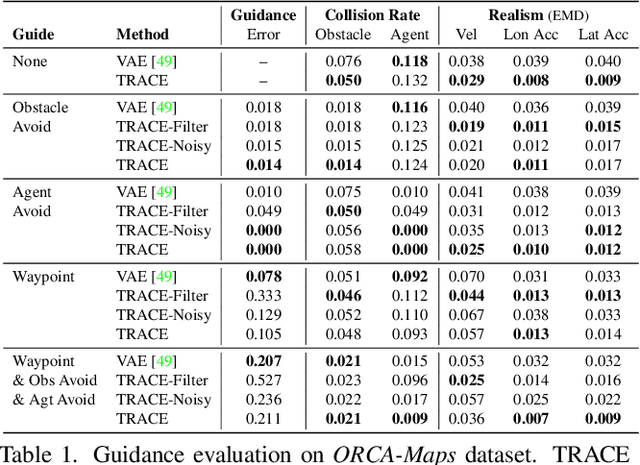
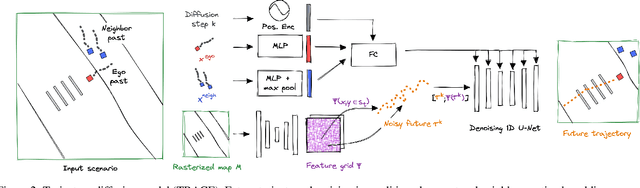
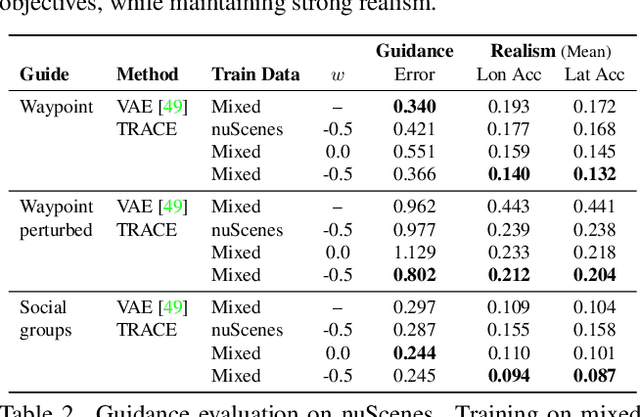
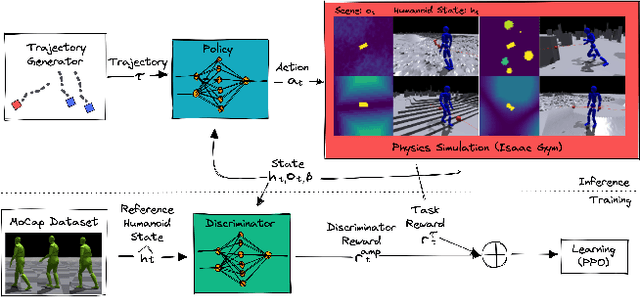
We introduce a method for generating realistic pedestrian trajectories and full-body animations that can be controlled to meet user-defined goals. We draw on recent advances in guided diffusion modeling to achieve test-time controllability of trajectories, which is normally only associated with rule-based systems. Our guided diffusion model allows users to constrain trajectories through target waypoints, speed, and specified social groups while accounting for the surrounding environment context. This trajectory diffusion model is integrated with a novel physics-based humanoid controller to form a closed-loop, full-body pedestrian animation system capable of placing large crowds in a simulated environment with varying terrains. We further propose utilizing the value function learned during RL training of the animation controller to guide diffusion to produce trajectories better suited for particular scenarios such as collision avoidance and traversing uneven terrain. Video results are available on the project page at https://nv-tlabs.github.io/trace-pace .
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
Mar 22, 2023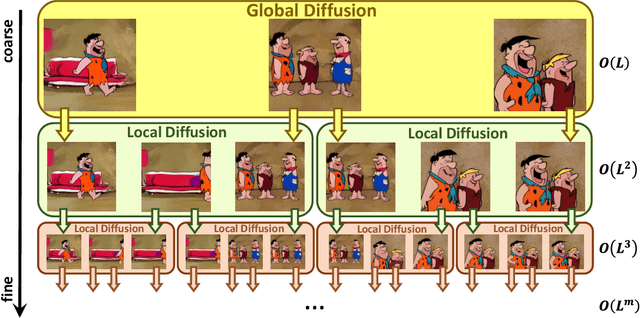
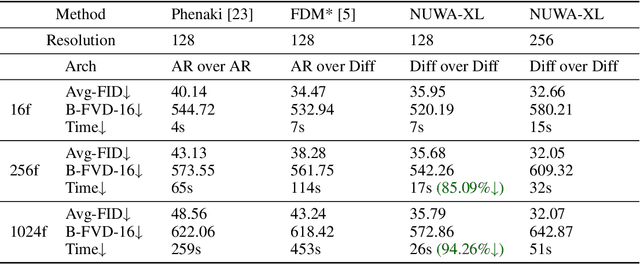
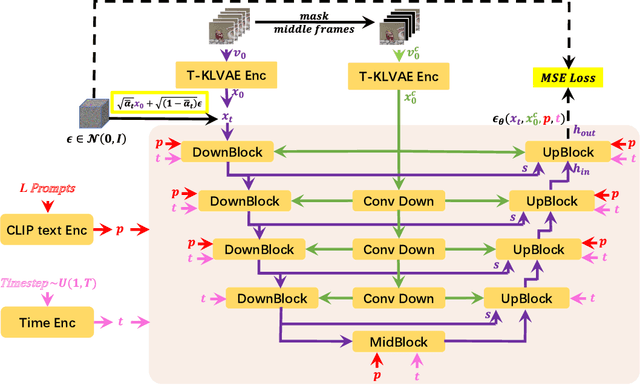
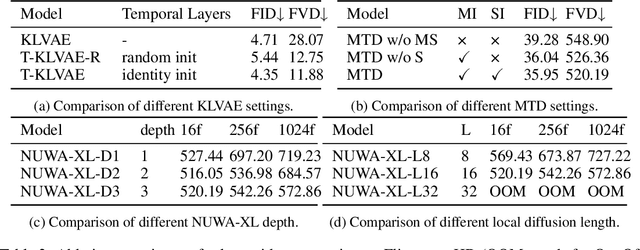
In this paper, we propose NUWA-XL, a novel Diffusion over Diffusion architecture for eXtremely Long video generation. Most current work generates long videos segment by segment sequentially, which normally leads to the gap between training on short videos and inferring long videos, and the sequential generation is inefficient. Instead, our approach adopts a ``coarse-to-fine'' process, in which the video can be generated in parallel at the same granularity. A global diffusion model is applied to generate the keyframes across the entire time range, and then local diffusion models recursively fill in the content between nearby frames. This simple yet effective strategy allows us to directly train on long videos (3376 frames) to reduce the training-inference gap, and makes it possible to generate all segments in parallel. To evaluate our model, we build FlintstonesHD dataset, a new benchmark for long video generation. Experiments show that our model not only generates high-quality long videos with both global and local coherence, but also decreases the average inference time from 7.55min to 26s (by 94.26\%) at the same hardware setting when generating 1024 frames. The homepage link is \url{https://msra-nuwa.azurewebsites.net/}
HigeNet: A Highly Efficient Modeling for Long Sequence Time Series Prediction in AIOps
Nov 13, 2022
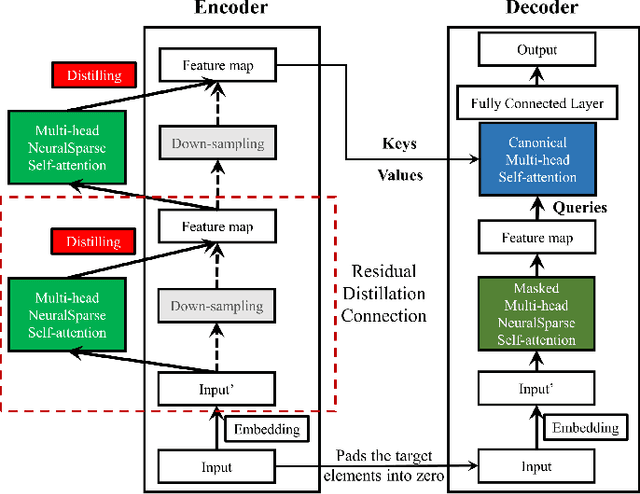
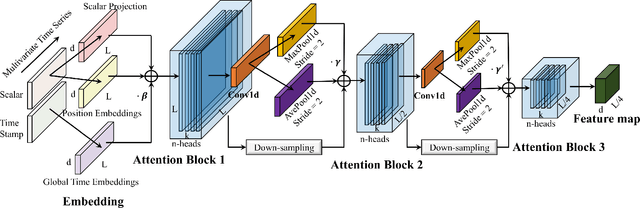
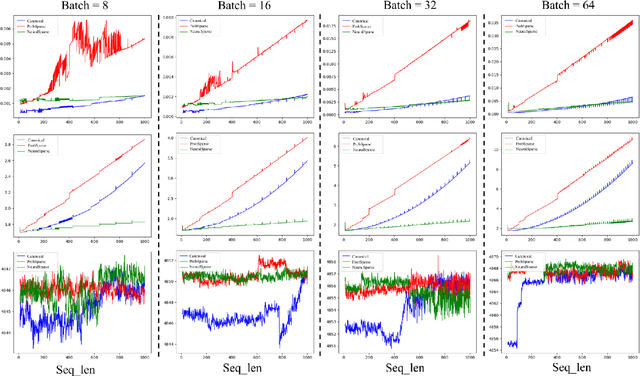
Modern IT system operation demands the integration of system software and hardware metrics. As a result, it generates a massive amount of data, which can be potentially used to make data-driven operational decisions. In the basic form, the decision model needs to monitor a large set of machine data, such as CPU utilization, allocated memory, disk and network latency, and predicts the system metrics to prevent performance degradation. Nevertheless, building an effective prediction model in this scenario is rather challenging as the model has to accurately capture the long-range coupling dependency in the Multivariate Time-Series (MTS). Moreover, this model needs to have low computational complexity and can scale efficiently to the dimension of data available. In this paper, we propose a highly efficient model named HigeNet to predict the long-time sequence time series. We have deployed the HigeNet on production in the D-matrix platform. We also provide offline evaluations on several publicly available datasets as well as one online dataset to demonstrate the model's efficacy. The extensive experiments show that training time, resource usage and accuracy of the model are found to be significantly better than five state-of-the-art competing models.
DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
Apr 10, 2023

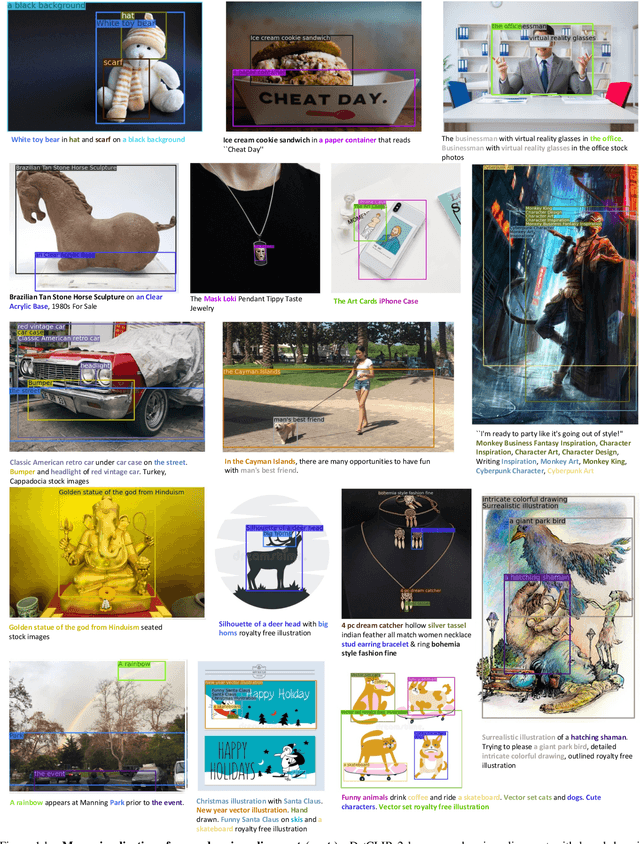
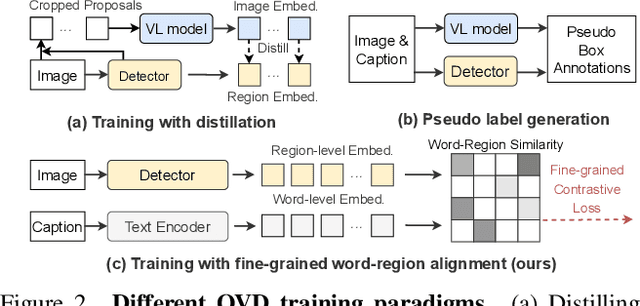
This paper presents DetCLIPv2, an efficient and scalable training framework that incorporates large-scale image-text pairs to achieve open-vocabulary object detection (OVD). Unlike previous OVD frameworks that typically rely on a pre-trained vision-language model (e.g., CLIP) or exploit image-text pairs via a pseudo labeling process, DetCLIPv2 directly learns the fine-grained word-region alignment from massive image-text pairs in an end-to-end manner. To accomplish this, we employ a maximum word-region similarity between region proposals and textual words to guide the contrastive objective. To enable the model to gain localization capability while learning broad concepts, DetCLIPv2 is trained with a hybrid supervision from detection, grounding and image-text pair data under a unified data formulation. By jointly training with an alternating scheme and adopting low-resolution input for image-text pairs, DetCLIPv2 exploits image-text pair data efficiently and effectively: DetCLIPv2 utilizes 13X more image-text pairs than DetCLIP with a similar training time and improves performance. With 13M image-text pairs for pre-training, DetCLIPv2 demonstrates superior open-vocabulary detection performance, e.g., DetCLIPv2 with Swin-T backbone achieves 40.4% zero-shot AP on the LVIS benchmark, which outperforms previous works GLIP/GLIPv2/DetCLIP by 14.4/11.4/4.5% AP, respectively, and even beats its fully-supervised counterpart by a large margin.
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023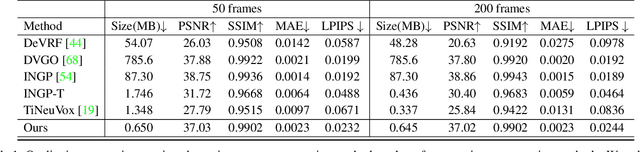
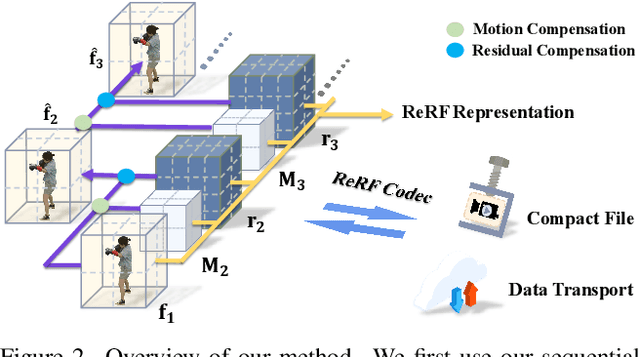
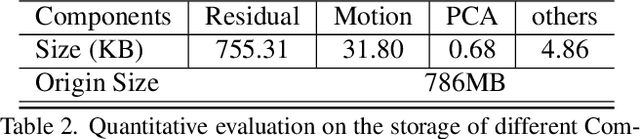
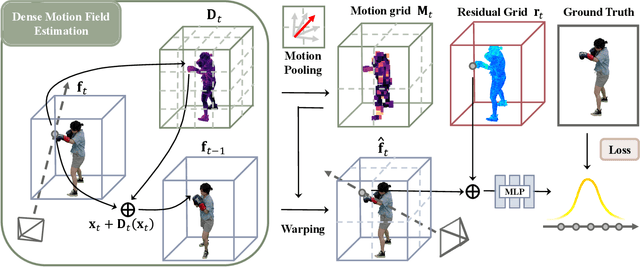
The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
MHfit: Mobile Health Data for Predicting Athletics Fitness Using Machine Learning
Apr 10, 2023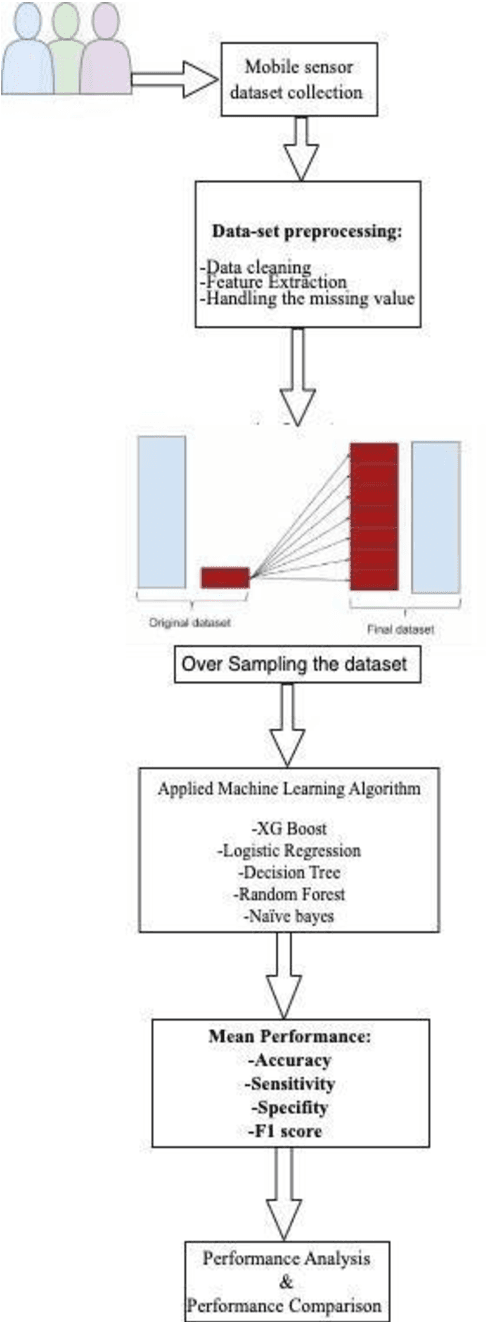
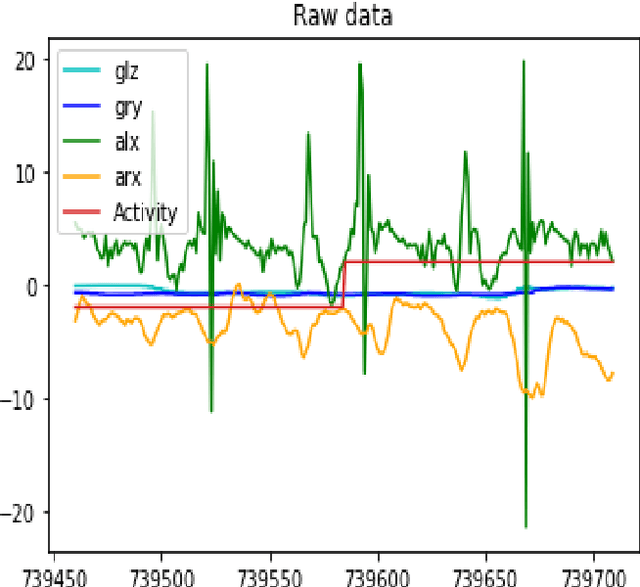
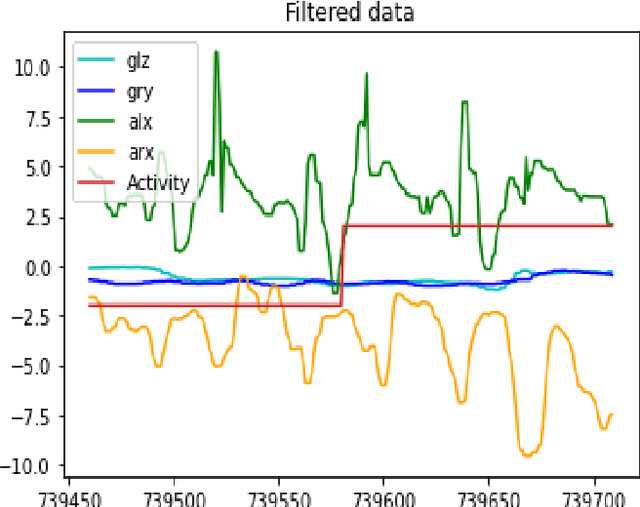
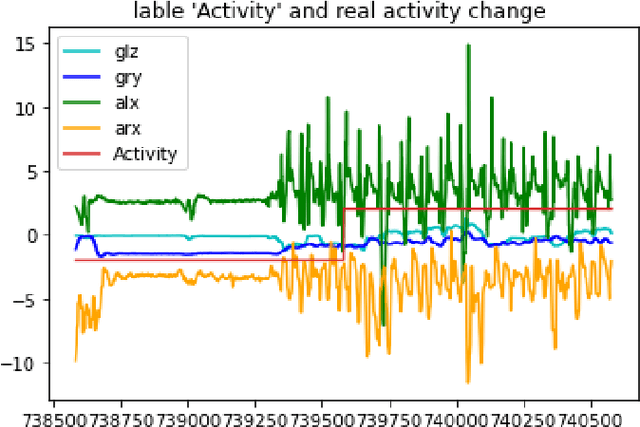
Mobile phones and other electronic gadgets or devices have aided in collecting data without the need for data entry. This paper will specifically focus on Mobile health data. Mobile health data use mobile devices to gather clinical health data and track patient vitals in real-time. Our study is aimed to give decisions for small or big sports teams on whether one athlete good fit or not for a particular game with the compare several machine learning algorithms to predict human behavior and health using the data collected from mobile devices and sensors placed on patients. In this study, we have obtained the dataset from a similar study done on mhealth. The dataset contains vital signs recordings of ten volunteers from different backgrounds. They had to perform several physical activities with a sensor placed on their bodies. Our study used 5 machine learning algorithms (XGBoost, Naive Bayes, Decision Tree, Random Forest, and Logistic Regression) to analyze and predict human health behavior. XGBoost performed better compared to the other machine learning algorithms and achieved 95.2% accuracy, 99.5% in sensitivity, 99.5% in specificity, and 99.66% in F1 score. Our research indicated a promising future in mhealth being used to predict human behavior and further research and exploration need to be done for it to be available for commercial use specifically in the sports industry.