 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMs
Dec 23, 2025



Diffusion Large Language Models (dLLMs) offer fast, parallel token generation, but their standalone use is plagued by an inherent efficiency-quality tradeoff. We show that, if carefully applied, the attributes of dLLMs can actually be a strength for drafters in speculative decoding with autoregressive (AR) verifiers. Our core insight is that dLLM's speed from parallel decoding drastically lowers the risk of costly rejections, providing a practical mechanism to effectively realize the (elusive) lengthy drafts that lead to large speedups with speculative decoding. We present FailFast, a dLLM-based speculative decoding framework that realizes this approach by dynamically adapting its speculation length. It "fails fast" by spending minimal compute in hard-to-speculate regions to shrink speculation latency and "wins big" by aggressively extending draft lengths in easier regions to reduce verification latency (in many cases, speculating and accepting 70 tokens at a time!). Without any fine-tuning, FailFast delivers lossless acceleration of AR LLMs and achieves up to 4.9$\times$ speedup over vanilla decoding, 1.7$\times$ over the best naive dLLM drafter, and 1.4$\times$ over EAGLE-3 across diverse models and workloads. We open-source FailFast at https://github.com/ruipeterpan/failfast.
Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
Aug 09, 2025Large reasoning models achieve strong performance through test-time scaling but incur substantial computational overhead, particularly from excessive token generation when processing short input prompts. While sparse attention mechanisms can reduce latency and memory usage, existing approaches suffer from significant accuracy degradation due to accumulated errors during long-generation reasoning. These methods generally require either high token retention rates or expensive retraining. We introduce LessIsMore, a training-free sparse attention mechanism for reasoning tasks, which leverages global attention patterns rather than relying on traditional head-specific local optimizations. LessIsMore aggregates token selections from local attention heads with recent contextual information, enabling unified cross-head token ranking for future decoding layers. This unified selection improves generalization and efficiency by avoiding the need to maintain separate token subsets per head. Evaluation across diverse reasoning tasks and benchmarks shows that LessIsMore preserves -- and in some cases improves -- accuracy while achieving a $1.1\times$ average decoding speed-up compared to full attention. Moreover, LessIsMore attends to $2\times$ fewer tokens without accuracy loss, achieving a $1.13\times$ end-to-end speed-up compared to existing sparse attention methods.
Legilimens: Performant Video Analytics on the System-on-Chip Edge
Apr 29, 2025



Continually retraining models has emerged as a primary technique to enable high-accuracy video analytics on edge devices. Yet, existing systems employ such adaptation by relying on the spare compute resources that traditional (memory-constrained) edge servers afford. In contrast, mobile edge devices such as drones and dashcams offer a fundamentally different resource profile: weak(er) compute with abundant unified memory pools. We present Legilimens, a continuous learning system for the mobile edge's System-on-Chip GPUs. Our driving insight is that visually distinct scenes that require retraining exhibit substantial overlap in model embeddings; if captured into a base model on device memory, specializing to each new scene can become lightweight, requiring very few samples. To practically realize this approach, Legilimens presents new, compute-efficient techniques to (1) select high-utility data samples for retraining specialized models, (2) update the base model without complete retraining, and (3) time-share compute resources between retraining and live inference for maximal accuracy. Across diverse workloads, Legilimens lowers retraining costs by 2.8-10x compared to existing systems, resulting in 18-45% higher accuracies.
Guillotine: Hypervisors for Isolating Malicious AIs
Apr 22, 2025As AI models become more embedded in critical sectors like finance, healthcare, and the military, their inscrutable behavior poses ever-greater risks to society. To mitigate this risk, we propose Guillotine, a hypervisor architecture for sandboxing powerful AI models -- models that, by accident or malice, can generate existential threats to humanity. Although Guillotine borrows some well-known virtualization techniques, Guillotine must also introduce fundamentally new isolation mechanisms to handle the unique threat model posed by existential-risk AIs. For example, a rogue AI may try to introspect upon hypervisor software or the underlying hardware substrate to enable later subversion of that control plane; thus, a Guillotine hypervisor requires careful co-design of the hypervisor software and the CPUs, RAM, NIC, and storage devices that support the hypervisor software, to thwart side channel leakage and more generally eliminate mechanisms for AI to exploit reflection-based vulnerabilities. Beyond such isolation at the software, network, and microarchitectural layers, a Guillotine hypervisor must also provide physical fail-safes more commonly associated with nuclear power plants, avionic platforms, and other types of mission critical systems. Physical fail-safes, e.g., involving electromechanical disconnection of network cables, or the flooding of a datacenter which holds a rogue AI, provide defense in depth if software, network, and microarchitectural isolation is compromised and a rogue AI must be temporarily shut down or permanently destroyed.
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
Apr 10, 2025



Recent advances in inference-time compute have significantly improved performance on complex tasks by generating long chains of thought (CoTs) using Large Reasoning Models (LRMs). However, this improved accuracy comes at the cost of high inference latency due to the length of generated reasoning sequences and the autoregressive nature of decoding. Our key insight in tackling these overheads is that LRM inference, and the reasoning that it embeds, is highly tolerant of approximations: complex tasks are typically broken down into simpler steps, each of which brings utility based on the semantic insight it provides for downstream steps rather than the exact tokens it generates. Accordingly, we introduce SpecReason, a system that automatically accelerates LRM inference by using a lightweight model to (speculatively) carry out simpler intermediate reasoning steps and reserving the costly base model only to assess (and potentially correct) the speculated outputs. Importantly, SpecReason's focus on exploiting the semantic flexibility of thinking tokens in preserving final-answer accuracy is complementary to prior speculation techniques, most notably speculative decoding, which demands token-level equivalence at each step. Across a variety of reasoning benchmarks, SpecReason achieves 1.5-2.5$\times$ speedup over vanilla LRM inference while improving accuracy by 1.0-9.9\%. Compared to speculative decoding without SpecReason, their combination yields an additional 19.4-44.2\% latency reduction. We open-source SpecReason at https://github.com/ruipeterpan/specreason.
RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Dec 13, 2024



RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
Marconi: Prefix Caching for the Era of Hybrid LLMs
Nov 28, 2024



Hybrid models that combine the language modeling capabilities of Attention layers with the efficiency of Recurrent layers (e.g., State Space Models) have gained traction in practically supporting long contexts in Large Language Model serving. Yet, the unique properties of these models complicate the usage of complementary efficiency optimizations such as prefix caching that skip redundant computations across requests. Most notably, their use of in-place state updates for recurrent layers precludes rolling back cache entries for partial sequence overlaps, and instead mandates only exact-match cache hits; the effect is a deluge of (large) cache entries per sequence, most of which yield minimal reuse opportunities. We present Marconi, the first system that supports efficient prefix caching with Hybrid LLMs. Key to Marconi are its novel admission and eviction policies that more judiciously assess potential cache entries based not only on recency, but also on (1) forecasts of their reuse likelihood across a taxonomy of different hit scenarios, and (2) the compute savings that hits deliver relative to memory footprints. Across diverse workloads and Hybrid models, Marconi achieves up to 34.4$\times$ higher token hit rates (71.1% or 617 ms lower TTFT) compared to state-of-the-art prefix caching systems.
Apparate: Rethinking Early Exits to Tame Latency-Throughput Tensions in ML Serving
Dec 08, 2023Machine learning (ML) inference platforms are tasked with balancing two competing goals: ensuring high throughput given many requests, and delivering low-latency responses to support interactive applications. Unfortunately, existing platform knobs (e.g., batch sizes) fail to ease this fundamental tension, and instead only enable users to harshly trade off one property for the other. This paper explores an alternate strategy to taming throughput-latency tradeoffs by changing the granularity at which inference is performed. We present Apparate, a system that automatically applies and manages early exits (EEs) in ML models, whereby certain inputs can exit with results at intermediate layers. To cope with the time-varying overhead and accuracy challenges that EEs bring, Apparate repurposes exits to provide continual feedback that powers several novel runtime monitoring and adaptation strategies. Apparate lowers median response latencies by 40.5-91.5% and 10.0-24.2% for diverse CV and NLP workloads, respectively, without affecting throughputs or violating tight accuracy constraints.
MadEye: Boosting Live Video Analytics Accuracy with Adaptive Camera Configurations
Apr 04, 2023



Camera orientations (i.e., rotation and zoom) govern the content that a camera captures in a given scene, which in turn heavily influences the accuracy of live video analytics pipelines. However, existing analytics approaches leave this crucial adaptation knob untouched, instead opting to only alter the way that captured images from fixed orientations are encoded, streamed, and analyzed. We present MadEye, a camera-server system that automatically and continually adapts orientations to maximize accuracy for the workload and resource constraints at hand. To realize this using commodity pan-tilt-zoom (PTZ) cameras, MadEye embeds (1) a search algorithm that rapidly explores the massive space of orientations to identify a fruitful subset at each time, and (2) a novel knowledge distillation strategy to efficiently (with only camera resources) select the ones that maximize workload accuracy. Experiments on diverse workloads show that MadEye boosts accuracy by 2.9-25.7% for the same resource usage, or achieves the same accuracy with 2-3.7x lower resource costs.
Marvolo: Programmatic Data Augmentation for Practical ML-Driven Malware Detection
Jun 07, 2022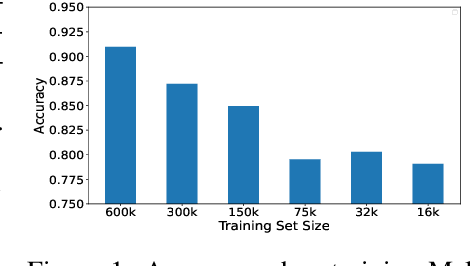


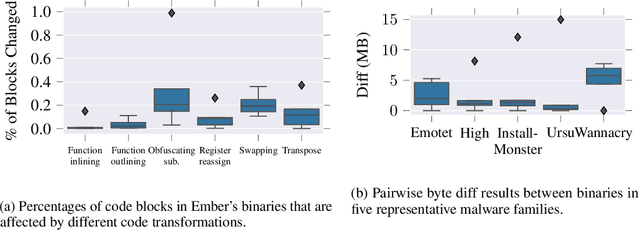
Data augmentation has been rare in the cyber security domain due to technical difficulties in altering data in a manner that is semantically consistent with the original data. This shortfall is particularly onerous given the unique difficulty of acquiring benign and malicious training data that runs into copyright restrictions, and that institutions like banks and governments receive targeted malware that will never exist in large quantities. We present MARVOLO, a binary mutator that programmatically grows malware (and benign) datasets in a manner that boosts the accuracy of ML-driven malware detectors. MARVOLO employs semantics-preserving code transformations that mimic the alterations that malware authors and defensive benign developers routinely make in practice , allowing us to generate meaningful augmented data. Crucially, semantics-preserving transformations also enable MARVOLO to safely propagate labels from original to newly-generated data samples without mandating expensive reverse engineering of binaries. Further, MARVOLO embeds several key optimizations that keep costs low for practitioners by maximizing the density of diverse data samples generated within a given time (or resource) budget. Experiments using wide-ranging commercial malware datasets and a recent ML-driven malware detector show that MARVOLO boosts accuracies by up to 5%, while operating on only a small fraction (15%) of the potential input binaries.