 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
Jun 18, 2026Conditional diffusion and flow models routinely fail to satisfy the very constraints that define their task. For instance, a depth-conditioned model often produces images whose re-extracted depth disagrees with the input, even though the forward operator--the depth predictor defining the constraint--is available during both training and inference. Existing approaches generally fall into two categories: supervised models that treat the conditioning signal as a static cue and ignore alignment information at inference, and guidance-based methods that consult it through hand-tuned linear updates, typically trading fidelity to the condition against the plausibility of the generated sample. We argue that the fundamental gap in both paradigms is that the model is never trained to utilize its own alignment error. We introduce FlowBender, a closed-loop framework that treats this error as a first-class input, training the network to learn a correction policy conditioned on inference-time feedback. At each step, an unguided look-ahead pass estimates the clean signal, a task-specific deviation is computed via the forward operator, and a refinement pass consumes this signal to produce a corrected velocity. We propose several variants of FlowBender, including a gradient-based formulation for differentiable operators and a zero-order variant for non-differentiable settings such as JPEG compression. For efficient sampling, we introduce a prior-step shortcut that enables closed-loop correction at a minimal additional computational cost. Across image-to-image translation, restoration, and 3D mesh texturing, FlowBender consistently outperforms standard supervised baselines, alignment-loss-augmented training, and state-of-the-art inference-time guidance, improving fidelity and plausibility simultaneously rather than trading them against each other. Project page: https://flow-bender.github.io/
VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
Jun 11, 2026We introduce VideoMDM, a diffusion-based framework that trains 3D human motion priors directly from accurate 2D poses extracted from monocular videos, without any 3D ground truth. A pretrained 2D-to-3D lifter provides approximate 3D pose sequences that serve as a noisy teacher: these are diffused, denoised by the model in 3D, and supervised in 2D by reprojecting the prediction and comparing against accurate keypoints. We show that, under mild assumptions, a depth-weighted 2D reprojection loss is equivalent in expectation to direct 3D supervision, and we adapt standard 3D motion regularizers - velocity consistency and over-parameterized representation alignment - to this 2D setting. Unlike methods that lift 2D to 3D only at inference, VideoMDM learns a coherent 3D motion manifold during training. On HumanML3D it nearly closes the gap to fully 3D-supervised MDM (FID 0.88 vs 0.54); On real video datasets Fit3D and NBA the method learns to generate motions consistently preferred by humans, with strong quantitative results.
SceneTeract: Agentic Functional Affordances and VLM Grounding in 3D Scenes
Mar 31, 2026Embodied AI depends on interactive 3D environments that support meaningful activities for diverse users, yet assessing their functional affordances remains a core challenge. We introduce SceneTeract, a framework that verifies 3D scene functionality under agent-specific constraints. Our core contribution is a grounded verification engine that couples high-level semantic reasoning with low-level geometric checks. SceneTeract decomposes complex activities into sequences of atomic actions and validates each step against accessibility requirements (e.g., reachability, clearance, and navigability) conditioned on an embodied agent profile, using explicit physical and geometric simulations. We deploy SceneTeract to perform an in-depth evaluation of (i) synthetic indoor environments, uncovering frequent functional failures that prevent basic interactions, and (ii) the ability of frontier Vision-Language Models (VLMs) to reason about and predict functional affordances, revealing systematic mismatches between semantic confidence and physical feasibility even for the strongest current models. Finally, we leverage SceneTeract as a reward engine for VLM post-training, enabling scalable distillation of geometric constraints into reasoning models. We release the SceneTeract verification suite and data to bridge perception and physical reality in embodied 3D scene understanding.
SpectralSplats: Robust Differentiable Tracking via Spectral Moment Supervision
Mar 25, 20263D Gaussian Splatting (3DGS) enables real-time, photorealistic novel view synthesis, making it a highly attractive representation for model-based video tracking. However, leveraging the differentiability of the 3DGS renderer "in the wild" remains notoriously fragile. A fundamental bottleneck lies in the compact, local support of the Gaussian primitives. Standard photometric objectives implicitly rely on spatial overlap; if severe camera misalignment places the rendered object outside the target's local footprint, gradients strictly vanish, leaving the optimizer stranded. We introduce SpectralSplats, a robust tracking framework that resolves this "vanishing gradient" problem by shifting the optimization objective from the spatial to the frequency domain. By supervising the rendered image via a set of global complex sinusoidal features (Spectral Moments), we construct a global basin of attraction, ensuring that a valid, directional gradient toward the target exists across the entire image domain, even when pixel overlap is completely nonexistent. To harness this global basin without introducing periodic local minima associated with high frequencies, we derive a principled Frequency Annealing schedule from first principles, gracefully transitioning the optimizer from global convexity to precise spatial alignment. We demonstrate that SpectralSplats acts as a seamless, drop-in replacement for spatial losses across diverse deformation parameterizations (from MLPs to sparse control points), successfully recovering complex deformations even from severely misaligned initializations where standard appearance-based tracking catastrophically fails.
Retrieval-Augmented Gaussian Avatars: Improving Expression Generalization
Mar 09, 2026Template-free animatable head avatars can achieve high visual fidelity by learning expression-dependent facial deformation directly from a subject's capture, avoiding parametric face templates and hand-designed blendshape spaces. However, since learned deformation is supervised only by the expressions observed for a single identity, these models suffer from limited expression coverage and often struggle when driven by motions that deviate from the training distribution. We introduce RAF (Retrieval-Augmented Faces), a simple training-time augmentation designed for template-free head avatars that learn deformation from data. RAF constructs a large unlabeled expression bank and, during training, replaces a subset of the subject's expression features with nearest-neighbor expressions retrieved from this bank while still reconstructing the subject's original frames. This exposes the deformation field to a broader range of expression conditions, encouraging stronger identity-expression decoupling and improving robustness to expression distribution shift without requiring paired cross-identity data, additional annotations, or architectural changes. We further analyze how retrieval augmentation increases expression diversity and validate retrieval quality with a user study showing that retrieved neighbors are perceptually closer in expression and pose. Experiments on the NeRSemble benchmark demonstrate that RAF consistently improves expression fidelity over the baseline, in both self-driving and cross-driving scenarios.
DiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion Enhancer
Mar 05, 2026Simulation is essential to the development and evaluation of autonomous robots such as self-driving vehicles. Neural reconstruction is emerging as a promising solution as it enables simulating a wide variety of scenarios from real-world data alone in an automated and scalable way. However, while methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results, they often exhibit artifacts particularly when rendering novel views, and fail to realistically integrate inserted dynamic objects, especially when they were captured from different scenes. To overcome these limitations, we introduce DiffusionHarmonizer, an online generative enhancement framework that transforms renderings from such imperfect scenes into temporally consistent outputs while improving their realism. At its core is a single-step temporally-conditioned enhancer that is converted from a pretrained multi-step image diffusion model, capable of running in online simulators on a single GPU. The key to training it effectively is a custom data curation pipeline that constructs synthetic-real pairs emphasizing appearance harmonization, artifact correction, and lighting realism. The result is a scalable system that significantly elevates simulation fidelity in both research and production environments.
Test-Time Training with KV Binding Is Secretly Linear Attention
Feb 24, 2026Test-time training (TTT) with KV binding as sequence modeling layer is commonly interpreted as a form of online meta-learning that memorizes a key-value mapping at test time. However, our analysis reveals multiple phenomena that contradict this memorization-based interpretation. Motivated by these findings, we revisit the formulation of TTT and show that a broad class of TTT architectures can be expressed as a form of learned linear attention operator. Beyond explaining previously puzzling model behaviors, this perspective yields multiple practical benefits: it enables principled architectural simplifications, admits fully parallel formulations that preserve performance while improving efficiency, and provides a systematic reduction of diverse TTT variants to a standard linear attention form. Overall, our results reframe TTT not as test-time memorization, but as learned linear attention with enhanced representational capacity.
RadarGen: Automotive Radar Point Cloud Generation from Cameras
Dec 19, 2025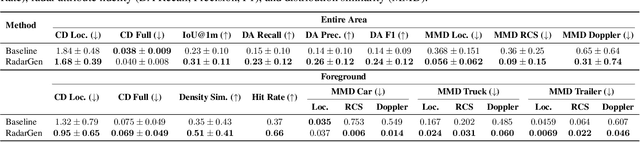
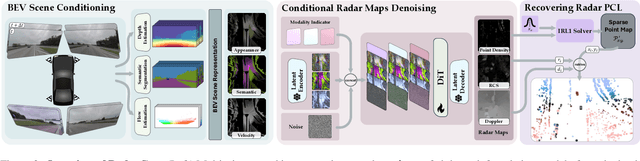
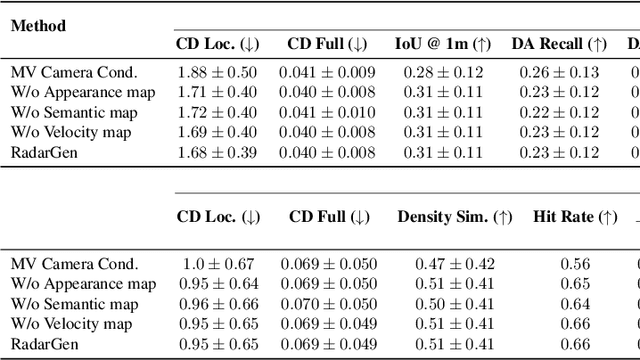
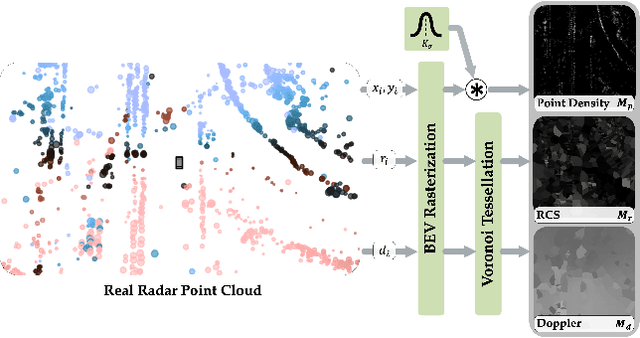
We present RadarGen, a diffusion model for synthesizing realistic automotive radar point clouds from multi-view camera imagery. RadarGen adapts efficient image-latent diffusion to the radar domain by representing radar measurements in bird's-eye-view form that encodes spatial structure together with radar cross section (RCS) and Doppler attributes. A lightweight recovery step reconstructs point clouds from the generated maps. To better align generation with the visual scene, RadarGen incorporates BEV-aligned depth, semantic, and motion cues extracted from pretrained foundation models, which guide the stochastic generation process toward physically plausible radar patterns. Conditioning on images makes the approach broadly compatible, in principle, with existing visual datasets and simulation frameworks, offering a scalable direction for multimodal generative simulation. Evaluations on large-scale driving data show that RadarGen captures characteristic radar measurement distributions and reduces the gap to perception models trained on real data, marking a step toward unified generative simulation across sensing modalities.
InstructMix2Mix: Consistent Sparse-View Editing Through Multi-View Model Personalization
Nov 18, 2025We address the task of multi-view image editing from sparse input views, where the inputs can be seen as a mix of images capturing the scene from different viewpoints. The goal is to modify the scene according to a textual instruction while preserving consistency across all views. Existing methods, based on per-scene neural fields or temporal attention mechanisms, struggle in this setting, often producing artifacts and incoherent edits. We propose InstructMix2Mix (I-Mix2Mix), a framework that distills the editing capabilities of a 2D diffusion model into a pretrained multi-view diffusion model, leveraging its data-driven 3D prior for cross-view consistency. A key contribution is replacing the conventional neural field consolidator in Score Distillation Sampling (SDS) with a multi-view diffusion student, which requires novel adaptations: incremental student updates across timesteps, a specialized teacher noise scheduler to prevent degeneration, and an attention modification that enhances cross-view coherence without additional cost. Experiments demonstrate that I-Mix2Mix significantly improves multi-view consistency while maintaining high per-frame edit quality.
Gaussian See, Gaussian Do: Semantic 3D Motion Transfer from Multiview Video
Nov 18, 2025We present Gaussian See, Gaussian Do, a novel approach for semantic 3D motion transfer from multiview video. Our method enables rig-free, cross-category motion transfer between objects with semantically meaningful correspondence. Building on implicit motion transfer techniques, we extract motion embeddings from source videos via condition inversion, apply them to rendered frames of static target shapes, and use the resulting videos to supervise dynamic 3D Gaussian Splatting reconstruction. Our approach introduces an anchor-based view-aware motion embedding mechanism, ensuring cross-view consistency and accelerating convergence, along with a robust 4D reconstruction pipeline that consolidates noisy supervision videos. We establish the first benchmark for semantic 3D motion transfer and demonstrate superior motion fidelity and structural consistency compared to adapted baselines. Code and data for this paper available at https://gsgd-motiontransfer.github.io/