 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Dec 19, 2025



We present FlexAvatar, a flexible large reconstruction model for high-fidelity 3D head avatars with detailed dynamic deformation from single or sparse images, without requiring camera poses or expression labels. It leverages a transformer-based reconstruction model with structured head query tokens as canonical anchor to aggregate flexible input-number-agnostic, camera-pose-free and expression-free inputs into a robust canonical 3D representation. For detailed dynamic deformation, we introduce a lightweight UNet decoder conditioned on UV-space position maps, which can produce detailed expression-dependent deformations in real time. To better capture rare but critical expressions like wrinkles and bared teeth, we also adopt a data distribution adjustment strategy during training to balance the distribution of these expressions in the training set. Moreover, a lightweight 10-second refinement can further enhances identity-specific details in extreme identities without affecting deformation quality. Extensive experiments demonstrate that our FlexAvatar achieves superior 3D consistency, detailed dynamic realism compared with previous methods, providing a practical solution for animatable 3D avatar creation.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
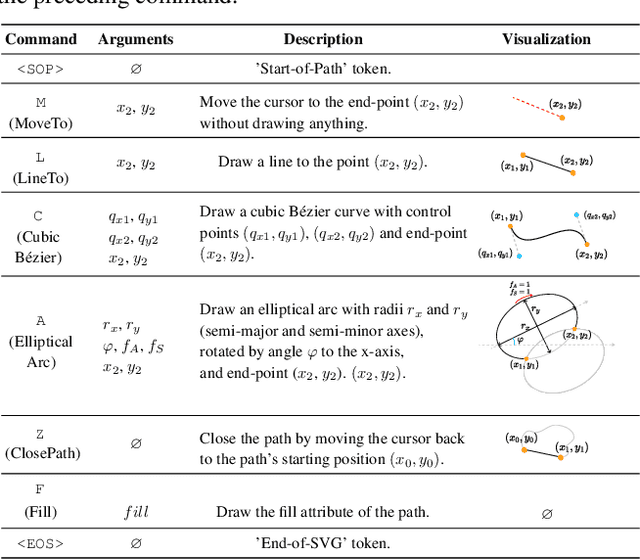


Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
MotionAgent: Fine-grained Controllable Video Generation via Motion Field Agent
Feb 05, 2025



We propose MotionAgent, enabling fine-grained motion control for text-guided image-to-video generation. The key technique is the motion field agent that converts motion information in text prompts into explicit motion fields, providing flexible and precise motion guidance. Specifically, the agent extracts the object movement and camera motion described in the text and converts them into object trajectories and camera extrinsics, respectively. An analytical optical flow composition module integrates these motion representations in 3D space and projects them into a unified optical flow. An optical flow adapter takes the flow to control the base image-to-video diffusion model for generating fine-grained controlled videos. The significant improvement in the Video-Text Camera Motion metrics on VBench indicates that our method achieves precise control over camera motion. We construct a subset of VBench to evaluate the alignment of motion information in the text and the generated video, outperforming other advanced models on motion generation accuracy.
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Apr 15, 2024



Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Dec 03, 2023



Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

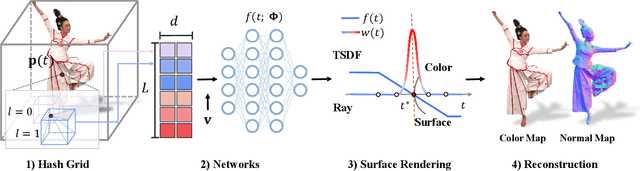
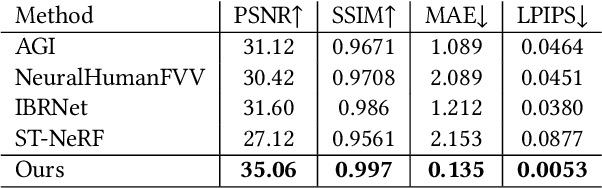
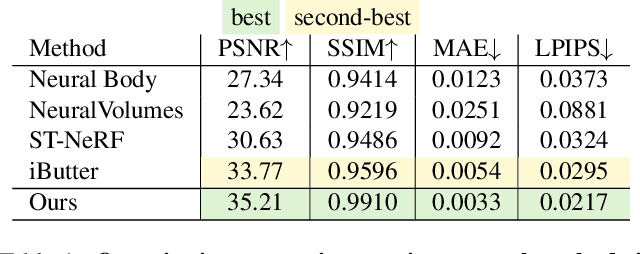
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time
Feb 22, 2022
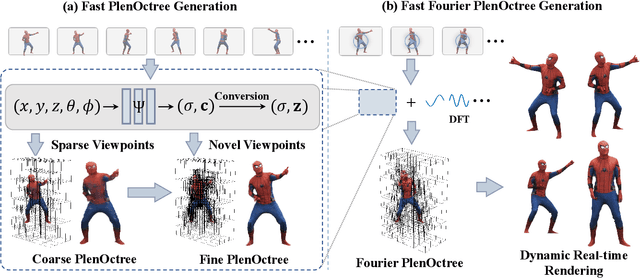

Implicit neural representations such as Neural Radiance Field (NeRF) have focused mainly on modeling static objects captured under multi-view settings where real-time rendering can be achieved with smart data structures, e.g., PlenOctree. In this paper, we present a novel Fourier PlenOctree (FPO) technique to tackle efficient neural modeling and real-time rendering of dynamic scenes captured under the free-view video (FVV) setting. The key idea in our FPO is a novel combination of generalized NeRF, PlenOctree representation, volumetric fusion and Fourier transform. To accelerate FPO construction, we present a novel coarse-to-fine fusion scheme that leverages the generalizable NeRF technique to generate the tree via spatial blending. To tackle dynamic scenes, we tailor the implicit network to model the Fourier coefficients of timevarying density and color attributes. Finally, we construct the FPO and train the Fourier coefficients directly on the leaves of a union PlenOctree structure of the dynamic sequence. We show that the resulting FPO enables compact memory overload to handle dynamic objects and supports efficient fine-tuning. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF and achieves over an order of magnitude acceleration over SOTA while preserving high visual quality for the free-viewpoint rendering of unseen dynamic scenes.
NeuVV: Neural Volumetric Videos with Immersive Rendering and Editing
Feb 12, 2022



Some of the most exciting experiences that Metaverse promises to offer, for instance, live interactions with virtual characters in virtual environments, require real-time photo-realistic rendering. 3D reconstruction approaches to rendering, active or passive, still require extensive cleanup work to fix the meshes or point clouds. In this paper, we present a neural volumography technique called neural volumetric video or NeuVV to support immersive, interactive, and spatial-temporal rendering of volumetric video contents with photo-realism and in real-time. The core of NeuVV is to efficiently encode a dynamic neural radiance field (NeRF) into renderable and editable primitives. We introduce two types of factorization schemes: a hyper-spherical harmonics (HH) decomposition for modeling smooth color variations over space and time and a learnable basis representation for modeling abrupt density and color changes caused by motion. NeuVV factorization can be integrated into a Video Octree (VOctree) analogous to PlenOctree to significantly accelerate training while reducing memory overhead. Real-time NeuVV rendering further enables a class of immersive content editing tools. Specifically, NeuVV treats each VOctree as a primitive and implements volume-based depth ordering and alpha blending to realize spatial-temporal compositions for content re-purposing. For example, we demonstrate positioning varied manifestations of the same performance at different 3D locations with different timing, adjusting color/texture of the performer's clothing, casting spotlight shadows and synthesizing distance falloff lighting, etc, all at an interactive speed. We further develop a hybrid neural-rasterization rendering framework to support consumer-level VR headsets so that the aforementioned volumetric video viewing and editing, for the first time, can be conducted immersively in virtual 3D space.
iButter: Neural Interactive Bullet Time Generator for Human Free-viewpoint Rendering
Aug 12, 2021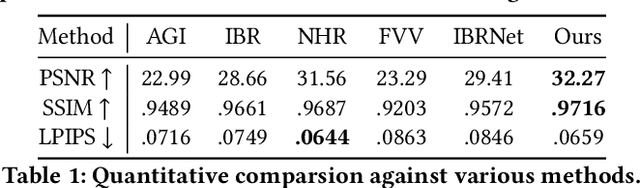
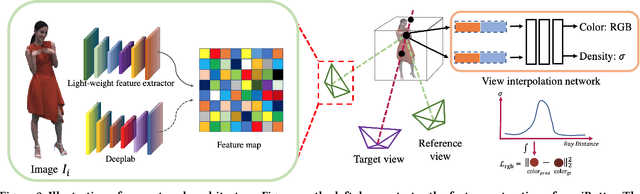
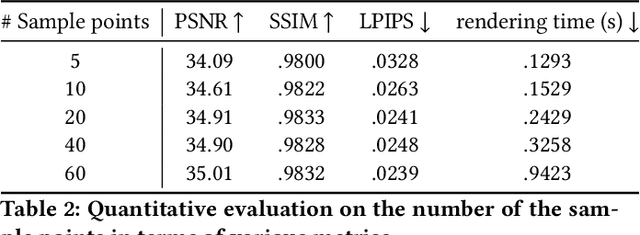
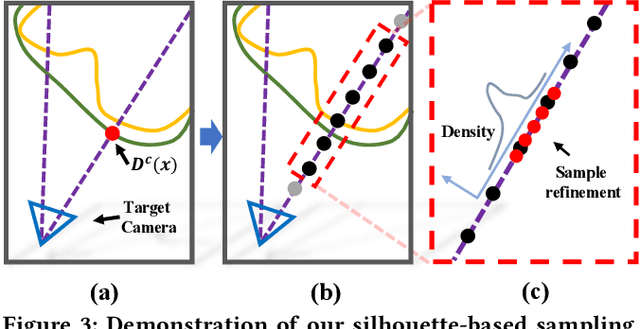
Generating ``bullet-time'' effects of human free-viewpoint videos is critical for immersive visual effects and VR/AR experience. Recent neural advances still lack the controllable and interactive bullet-time design ability for human free-viewpoint rendering, especially under the real-time, dynamic and general setting for our trajectory-aware task. To fill this gap, in this paper we propose a neural interactive bullet-time generator (iButter) for photo-realistic human free-viewpoint rendering from dense RGB streams, which enables flexible and interactive design for human bullet-time visual effects. Our iButter approach consists of a real-time preview and design stage as well as a trajectory-aware refinement stage. During preview, we propose an interactive bullet-time design approach by extending the NeRF rendering to a real-time and dynamic setting and getting rid of the tedious per-scene training. To this end, our bullet-time design stage utilizes a hybrid training set, light-weight network design and an efficient silhouette-based sampling strategy. During refinement, we introduce an efficient trajectory-aware scheme within 20 minutes, which jointly encodes the spatial, temporal consistency and semantic cues along the designed trajectory, achieving photo-realistic bullet-time viewing experience of human activities. Extensive experiments demonstrate the effectiveness of our approach for convenient interactive bullet-time design and photo-realistic human free-viewpoint video generation.