 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VM-UNET-V2 Rethinking Vision Mamba UNet for Medical Image Segmentation
Mar 14, 2024
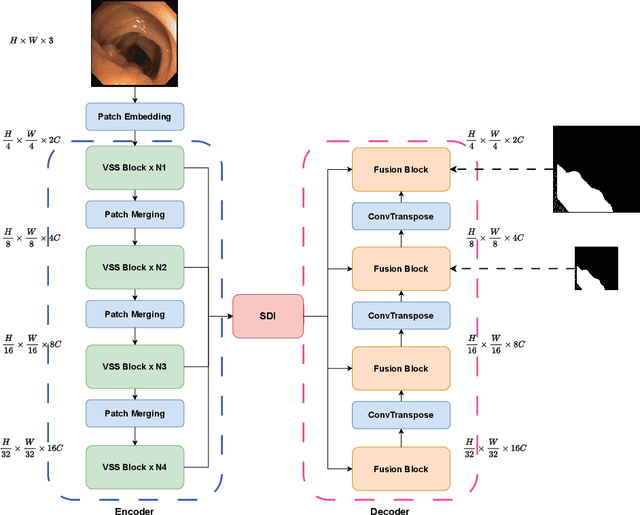
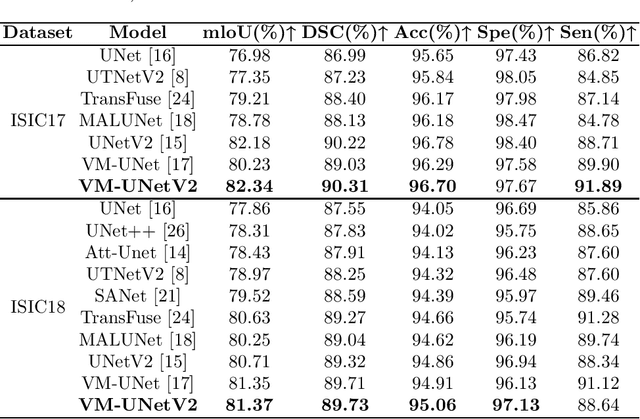
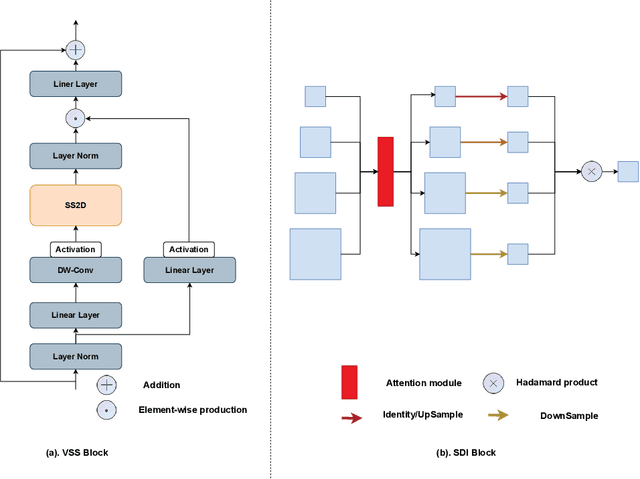
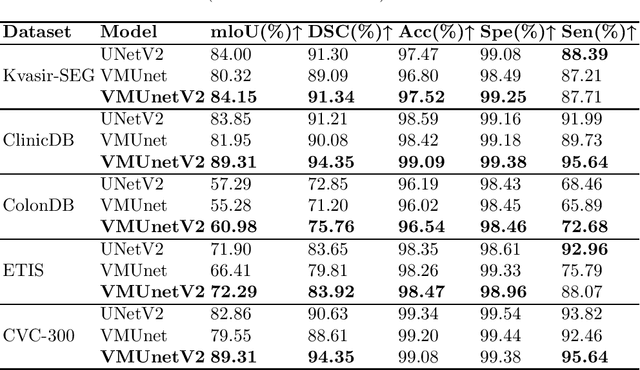
In the field of medical image segmentation, models based on both CNN and Transformer have been thoroughly investigated. However, CNNs have limited modeling capabilities for long-range dependencies, making it challenging to exploit the semantic information within images fully. On the other hand, the quadratic computational complexity poses a challenge for Transformers. Recently, State Space Models (SSMs), such as Mamba, have been recognized as a promising method. They not only demonstrate superior performance in modeling long-range interactions, but also preserve a linear computational complexity. Inspired by the Mamba architecture, We proposed Vison Mamba-UNetV2, the Visual State Space (VSS) Block is introduced to capture extensive contextual information, the Semantics and Detail Infusion (SDI) is introduced to augment the infusion of low-level and high-level features. We conduct comprehensive experiments on the ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir, CVC-ColonDB and ETIS-LaribPolypDB public datasets. The results indicate that VM-UNetV2 exhibits competitive performance in medical image segmentation tasks. Our code is available at https://github.com/nobodyplayer1/VM-UNetV2.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024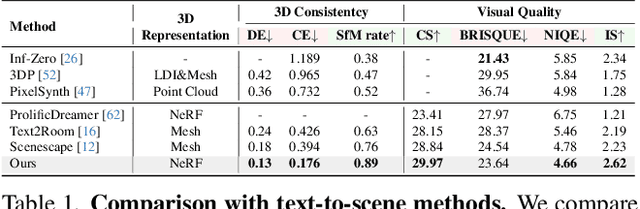
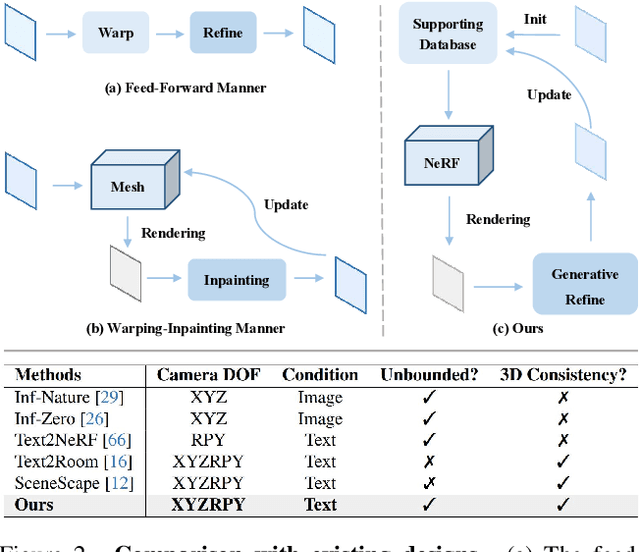
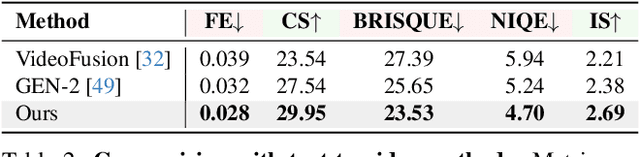
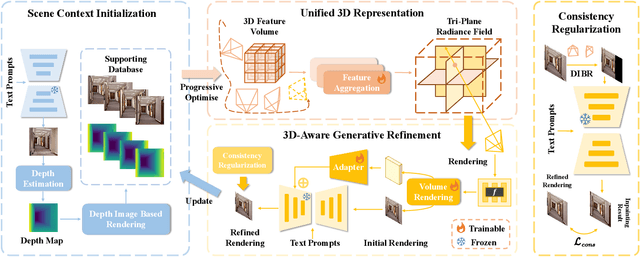
Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
Category-Agnostic Pose Estimation for Point Clouds
Mar 12, 2024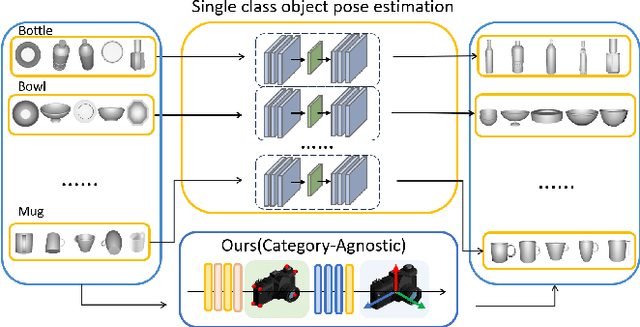

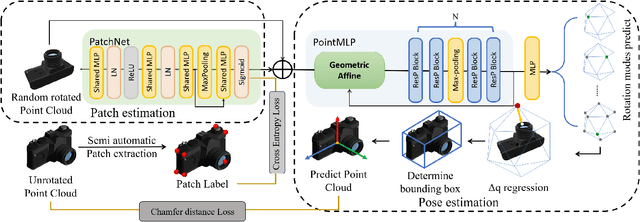
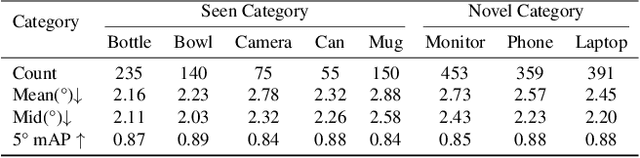
The goal of object pose estimation is to visually determine the pose of a specific object in the RGB-D input. Unfortunately, when faced with new categories, both instance-based and category-based methods are unable to deal with unseen objects of unseen categories, which is a challenge for pose estimation. To address this issue, this paper proposes a method to introduce geometric features for pose estimation of point clouds without requiring category information. The method is based only on the patch feature of the point cloud, a geometric feature with rotation invariance. After training without category information, our method achieves as good results as other category-based methods. Our method successfully achieved pose annotation of no category information instances on the CAMERA25 dataset and ModelNet40 dataset.
ViSaRL: Visual Reinforcement Learning Guided by Human Saliency
Mar 16, 2024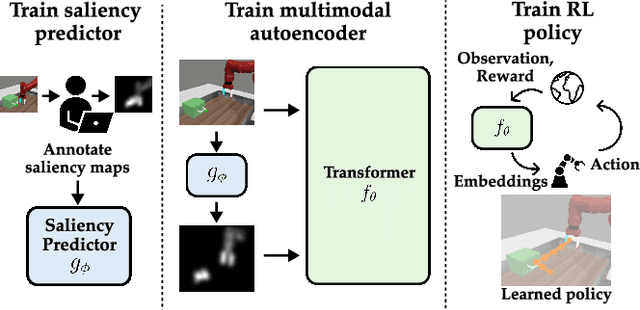

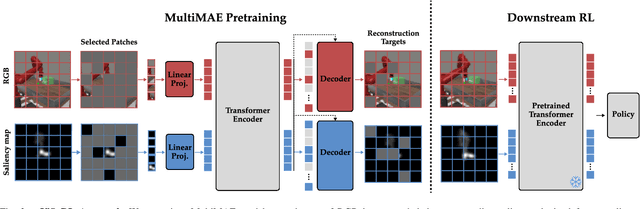
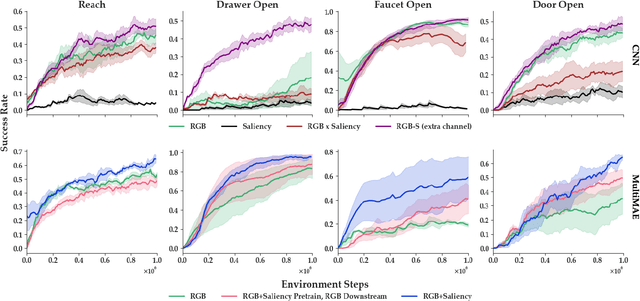
Training robots to perform complex control tasks from high-dimensional pixel input using reinforcement learning (RL) is sample-inefficient, because image observations are comprised primarily of task-irrelevant information. By contrast, humans are able to visually attend to task-relevant objects and areas. Based on this insight, we introduce Visual Saliency-Guided Reinforcement Learning (ViSaRL). Using ViSaRL to learn visual representations significantly improves the success rate, sample efficiency, and generalization of an RL agent on diverse tasks including DeepMind Control benchmark, robot manipulation in simulation and on a real robot. We present approaches for incorporating saliency into both CNN and Transformer-based encoders. We show that visual representations learned using ViSaRL are robust to various sources of visual perturbations including perceptual noise and scene variations. ViSaRL nearly doubles success rate on the real-robot tasks compared to the baseline which does not use saliency.
A Spectrum-based Image Denoising Method with Edge Feature Enhancement
Mar 16, 2024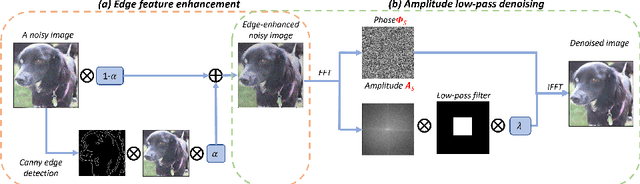
Image denoising stands as a critical challenge in image processing and computer vision, aiming to restore the original image from noise-affected versions caused by various intrinsic and extrinsic factors. This process is essential for applications that rely on the high quality and clarity of visual information, such as image restoration, visual tracking, and image registration, where the original content is vital for performance. Despite the development of numerous denoising algorithms, effectively suppressing noise, particularly under poor capture conditions with high noise levels, remains a challenge. Image denoising's practical importance spans multiple domains, notably medical imaging for enhanced diagnostic precision, as well as surveillance and satellite imagery where it improves image quality and usability. Techniques like the Fourier transform, which excels in noise reduction and edge preservation, along with phase congruency-based methods, offer promising results for enhancing noisy and low-contrast images common in modern imaging scenarios.
Towards Unified Multi-Modal Personalization: Large Vision-Language Models for Generative Recommendation and Beyond
Mar 15, 2024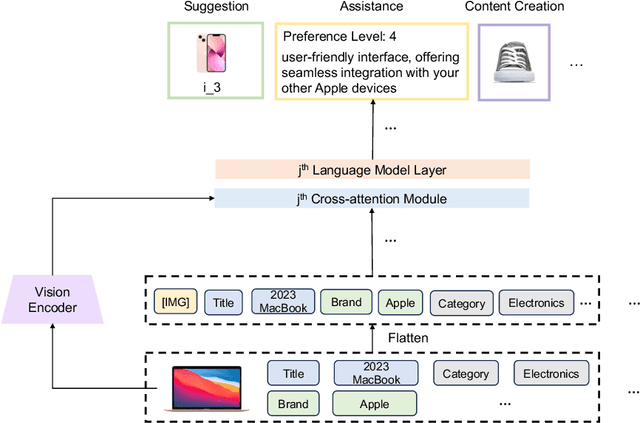
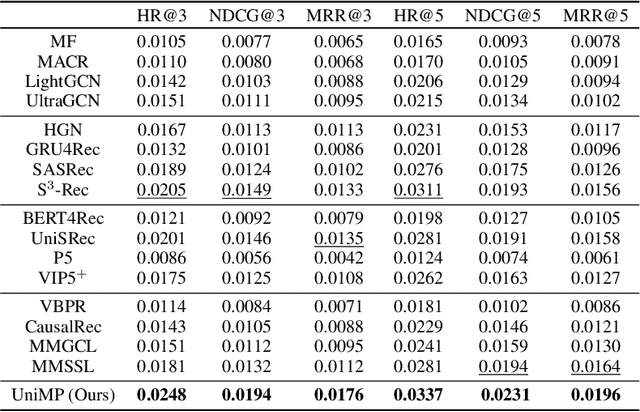
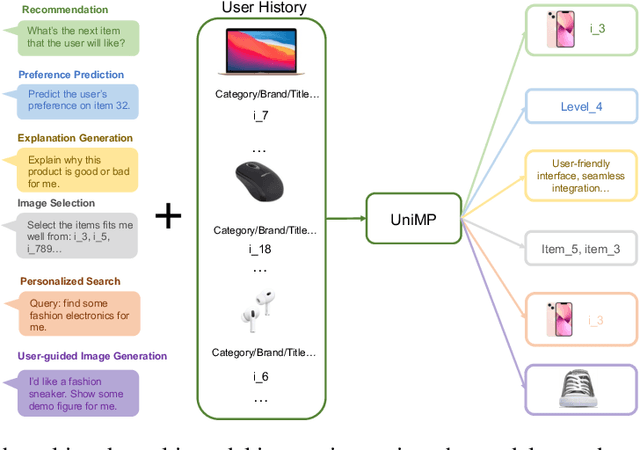
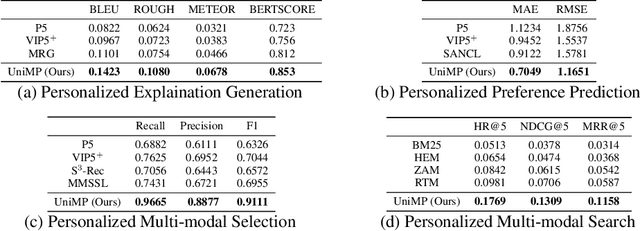
Developing a universal model that can effectively harness heterogeneous resources and respond to a wide range of personalized needs has been a longstanding community aspiration. Our daily choices, especially in domains like fashion and retail, are substantially shaped by multi-modal data, such as pictures and textual descriptions. These modalities not only offer intuitive guidance but also cater to personalized user preferences. However, the predominant personalization approaches mainly focus on the ID or text-based recommendation problem, failing to comprehend the information spanning various tasks or modalities. In this paper, our goal is to establish a Unified paradigm for Multi-modal Personalization systems (UniMP), which effectively leverages multi-modal data while eliminating the complexities associated with task- and modality-specific customization. We argue that the advancements in foundational generative modeling have provided the flexibility and effectiveness necessary to achieve the objective. In light of this, we develop a generic and extensible personalization generative framework, that can handle a wide range of personalized needs including item recommendation, product search, preference prediction, explanation generation, and further user-guided image generation. Our methodology enhances the capabilities of foundational language models for personalized tasks by seamlessly ingesting interleaved cross-modal user history information, ensuring a more precise and customized experience for users. To train and evaluate the proposed multi-modal personalized tasks, we also introduce a novel and comprehensive benchmark covering a variety of user requirements. Our experiments on the real-world benchmark showcase the model's potential, outperforming competitive methods specialized for each task.
MonoOcc: Digging into Monocular Semantic Occupancy Prediction
Mar 13, 2024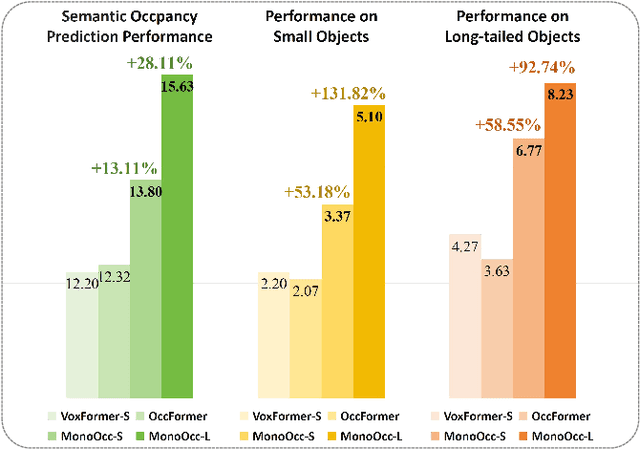
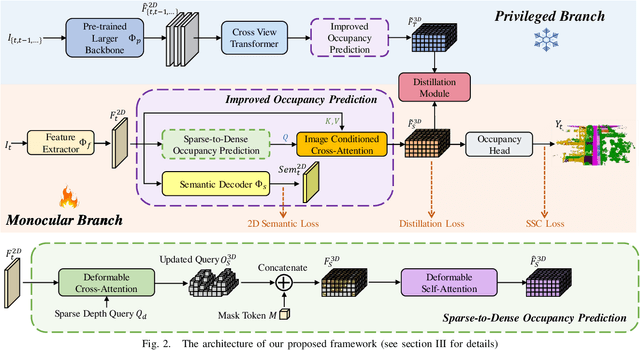
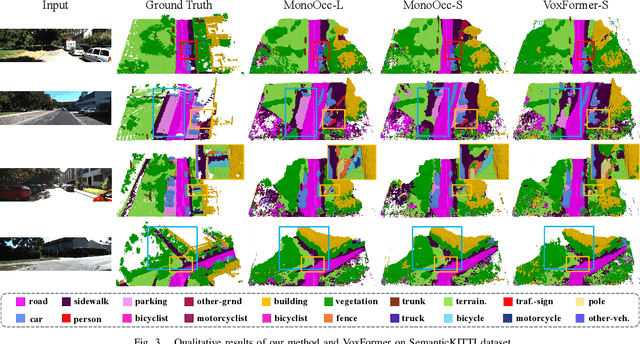
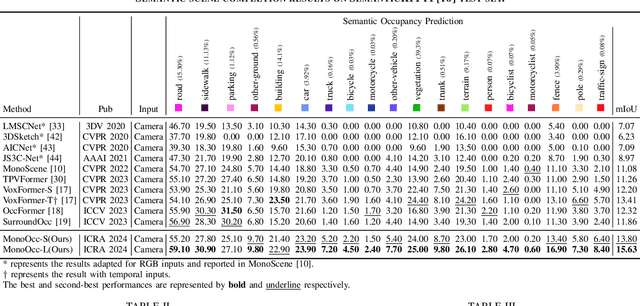
Monocular Semantic Occupancy Prediction aims to infer the complete 3D geometry and semantic information of scenes from only 2D images. It has garnered significant attention, particularly due to its potential to enhance the 3D perception of autonomous vehicles. However, existing methods rely on a complex cascaded framework with relatively limited information to restore 3D scenes, including a dependency on supervision solely on the whole network's output, single-frame input, and the utilization of a small backbone. These challenges, in turn, hinder the optimization of the framework and yield inferior prediction results, particularly concerning smaller and long-tailed objects. To address these issues, we propose MonoOcc. In particular, we (i) improve the monocular occupancy prediction framework by proposing an auxiliary semantic loss as supervision to the shallow layers of the framework and an image-conditioned cross-attention module to refine voxel features with visual clues, and (ii) employ a distillation module that transfers temporal information and richer knowledge from a larger image backbone to the monocular semantic occupancy prediction framework with low cost of hardware. With these advantages, our method yields state-of-the-art performance on the camera-based SemanticKITTI Scene Completion benchmark. Codes and models can be accessed at https://github.com/ucaszyp/MonoOcc
NoiseDiffusion: Correcting Noise for Image Interpolation with Diffusion Models beyond Spherical Linear Interpolation
Mar 13, 2024
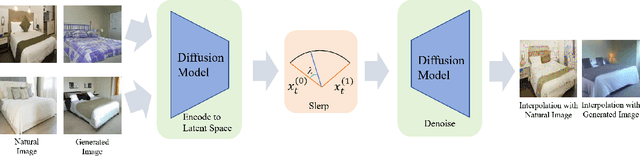

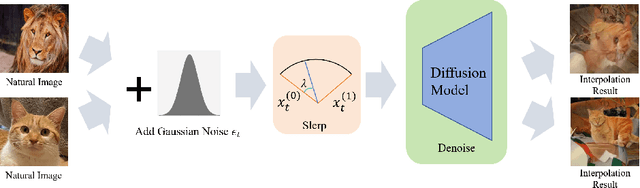
Image interpolation based on diffusion models is promising in creating fresh and interesting images. Advanced interpolation methods mainly focus on spherical linear interpolation, where images are encoded into the noise space and then interpolated for denoising to images. However, existing methods face challenges in effectively interpolating natural images (not generated by diffusion models), thereby restricting their practical applicability. Our experimental investigations reveal that these challenges stem from the invalidity of the encoding noise, which may no longer obey the expected noise distribution, e.g., a normal distribution. To address these challenges, we propose a novel approach to correct noise for image interpolation, NoiseDiffusion. Specifically, NoiseDiffusion approaches the invalid noise to the expected distribution by introducing subtle Gaussian noise and introduces a constraint to suppress noise with extreme values. In this context, promoting noise validity contributes to mitigating image artifacts, but the constraint and introduced exogenous noise typically lead to a reduction in signal-to-noise ratio, i.e., loss of original image information. Hence, NoiseDiffusion performs interpolation within the noisy image space and injects raw images into these noisy counterparts to address the challenge of information loss. Consequently, NoiseDiffusion enables us to interpolate natural images without causing artifacts or information loss, thus achieving the best interpolation results.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024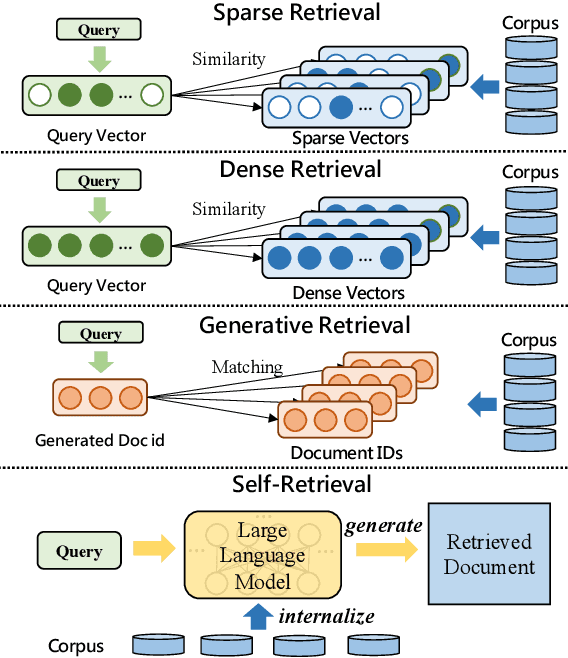
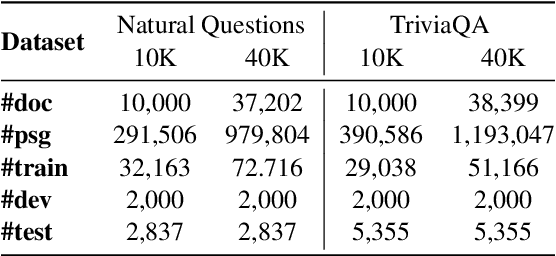
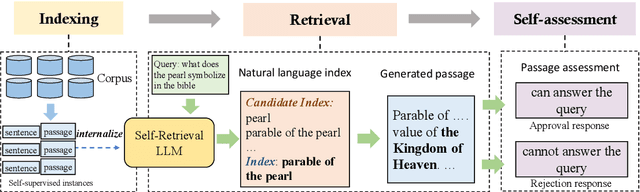
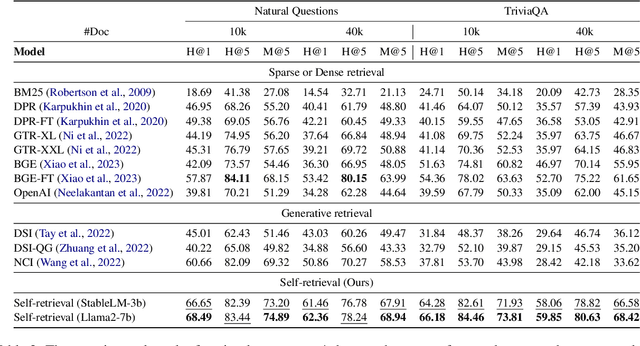
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
Self-supervised co-salient object detection via feature correspondence at multiple scales
Mar 17, 2024

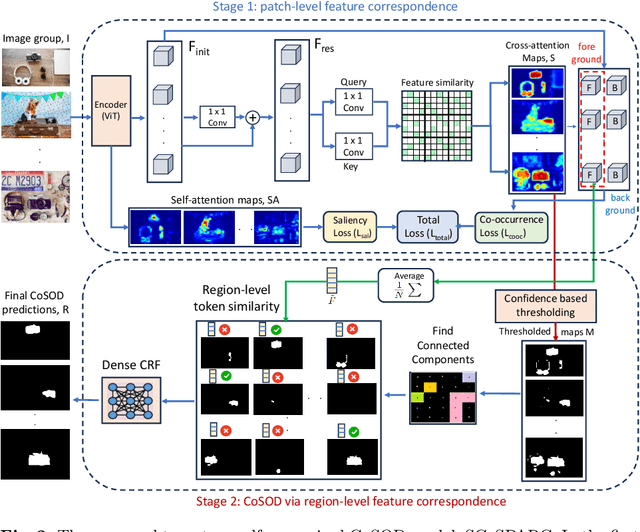
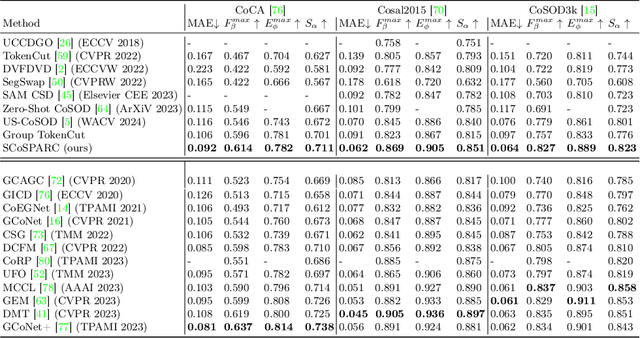
Our paper introduces a novel two-stage self-supervised approach for detecting co-occurring salient objects (CoSOD) in image groups without requiring segmentation annotations. Unlike existing unsupervised methods that rely solely on patch-level information (e.g. clustering patch descriptors) or on computation heavy off-the-shelf components for CoSOD, our lightweight model leverages feature correspondences at both patch and region levels, significantly improving prediction performance. In the first stage, we train a self-supervised network that detects co-salient regions by computing local patch-level feature correspondences across images. We obtain the segmentation predictions using confidence-based adaptive thresholding. In the next stage, we refine these intermediate segmentations by eliminating the detected regions (within each image) whose averaged feature representations are dissimilar to the foreground feature representation averaged across all the cross-attention maps (from the previous stage). Extensive experiments on three CoSOD benchmark datasets show that our self-supervised model outperforms the corresponding state-of-the-art models by a huge margin (e.g. on the CoCA dataset, our model has a 13.7% F-measure gain over the SOTA unsupervised CoSOD model). Notably, our self-supervised model also outperforms several recent fully supervised CoSOD models on the three test datasets (e.g., on the CoCA dataset, our model has a 4.6% F-measure gain over a recent supervised CoSOD model).