 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Optimizing Pretraining Data Mixtures with LLM-Estimated Utility
Jan 20, 2025



Large Language Models improve with increasing amounts of high-quality training data. However, leveraging larger datasets requires balancing quality, quantity, and diversity across sources. After evaluating nine baseline methods under both compute- and data-constrained scenarios, we find token-count heuristics outperform manual and learned mixes, indicating that simple approaches accounting for dataset size and diversity are surprisingly effective. Building on this insight, we propose two complementary approaches: UtiliMax, which extends token-based heuristics by incorporating utility estimates from reduced-scale ablations, achieving up to a 10.6x speedup over manual baselines; and Model Estimated Data Utility (MEDU), which leverages LLMs to estimate data utility from small samples, matching ablation-based performance while reducing computational requirements by $\sim$200x. Together, these approaches establish a new framework for automated, compute-efficient data mixing that is robust across training regimes.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
Pushing the performances of ASR models on English and Spanish accents
Dec 22, 2022



Speech to text models tend to be trained and evaluated against a single target accent. This is especially true for English for which native speakers from the United States became the main benchmark. In this work, we are going to show how two simple methods: pre-trained embeddings and auxiliary classification losses can improve the performance of ASR systems. We are looking for upgrades as universal as possible and therefore we will explore their impact on several models architectures and several languages.
Scaling ASR Improves Zero and Few Shot Learning
Nov 29, 2021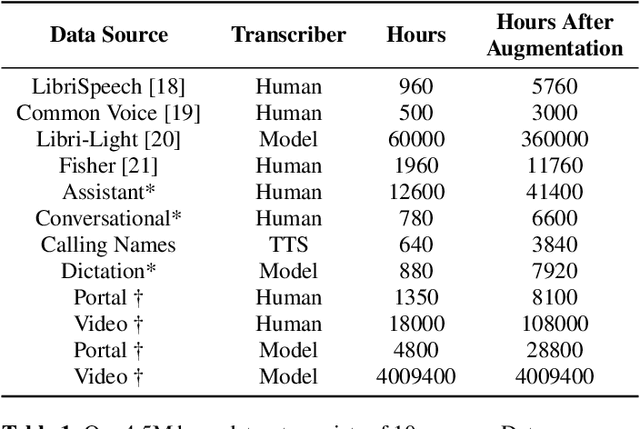
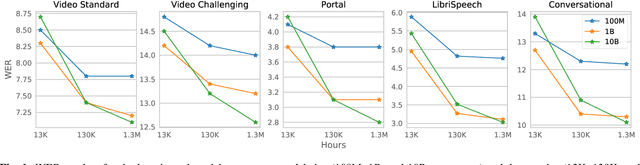
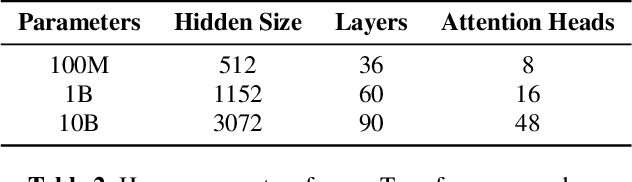
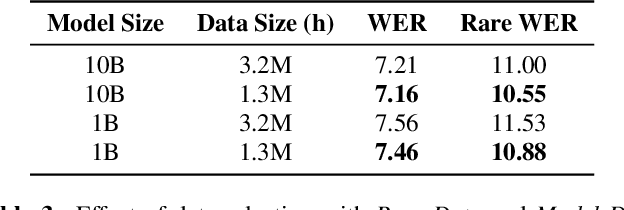
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings
Oct 08, 2021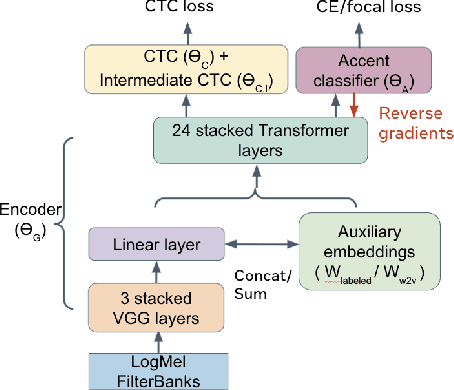
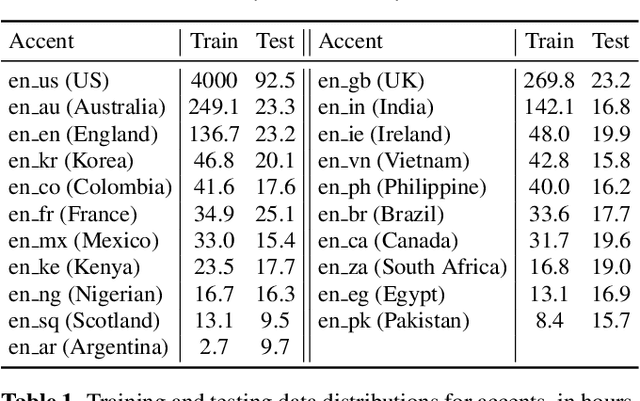
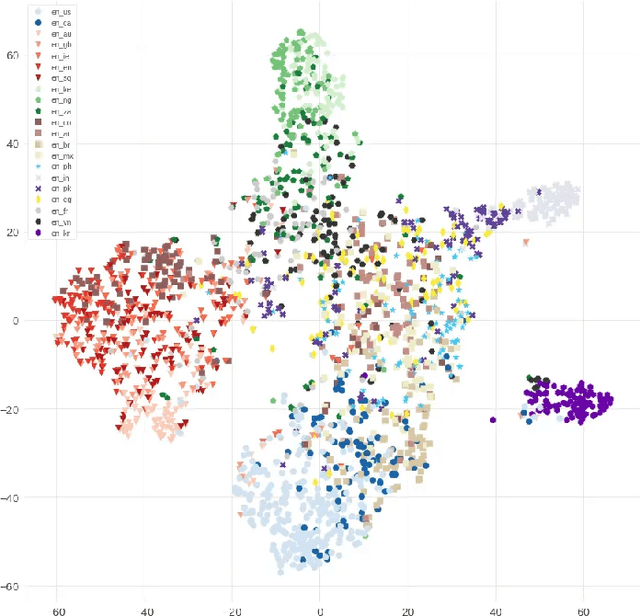

Speech recognition models often obtain degraded performance when tested on speech with unseen accents. Domain-adversarial training (DAT) and multi-task learning (MTL) are two common approaches for building accent-robust ASR models. ASR models using accent embeddings is another approach for improving robustness to accents. In this study, we perform systematic comparisons of DAT and MTL approaches using a large volume of English accent corpus (4000 hours of US English speech and 1244 hours of 20 non-US-English accents speech). We explore embeddings trained under supervised and unsupervised settings: a separate embedding matrix trained using accent labels, and embeddings extracted from a fine-tuned wav2vec model. We find that our DAT model trained with supervised embeddings achieves the best performance overall and consistently provides benefits for all testing datasets, and our MTL model trained with wav2vec embeddings are helpful learning accent-invariant features and improving novel/unseen accents. We also illustrate that wav2vec embeddings have more advantages for building accent-robust ASR when no accent labels are available for training supervised embeddings.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Aug 04, 2021
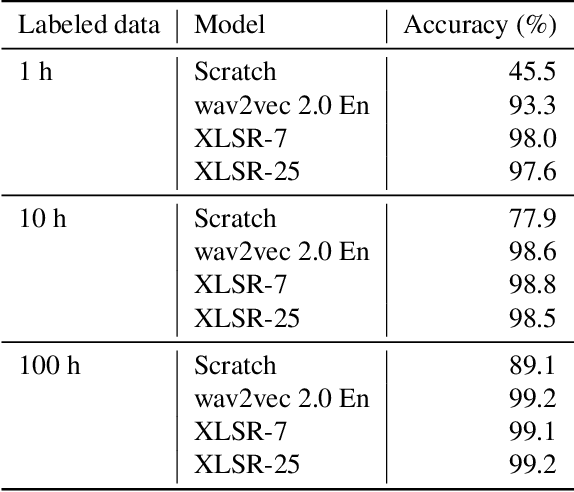
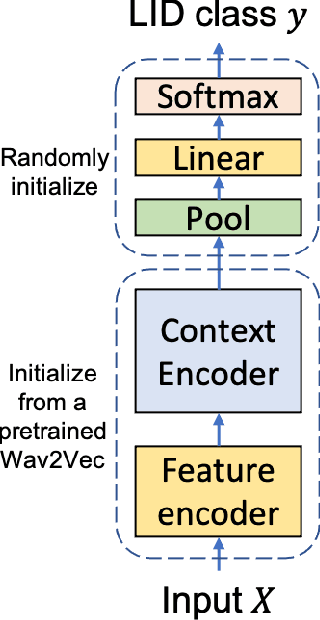
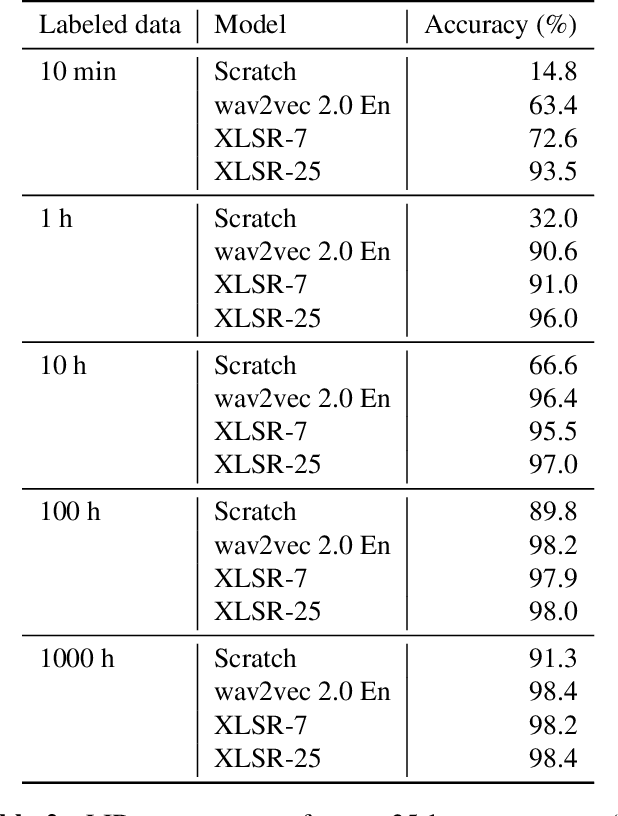
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021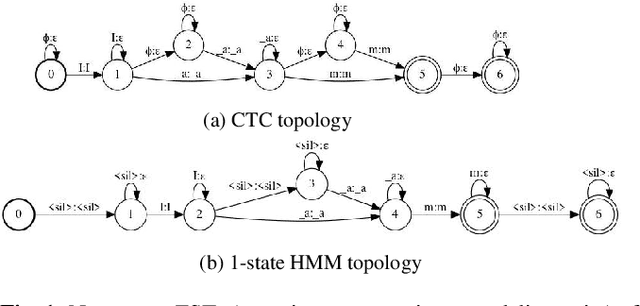
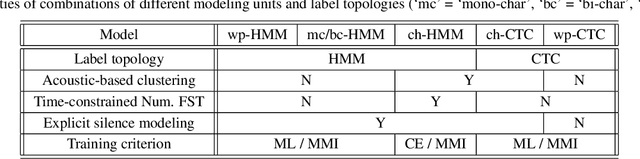
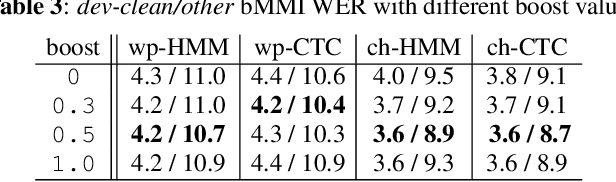
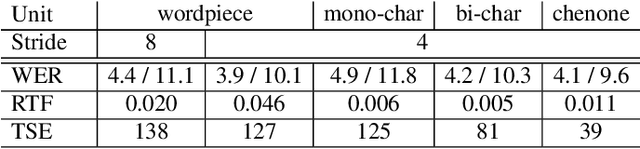
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
Improving RNN Transducer Based ASR with Auxiliary Tasks
Nov 09, 2020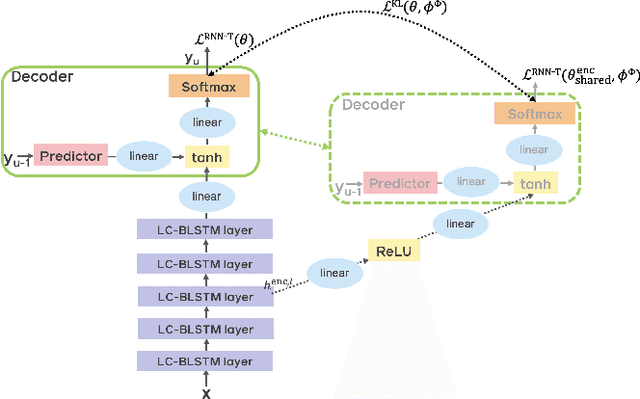

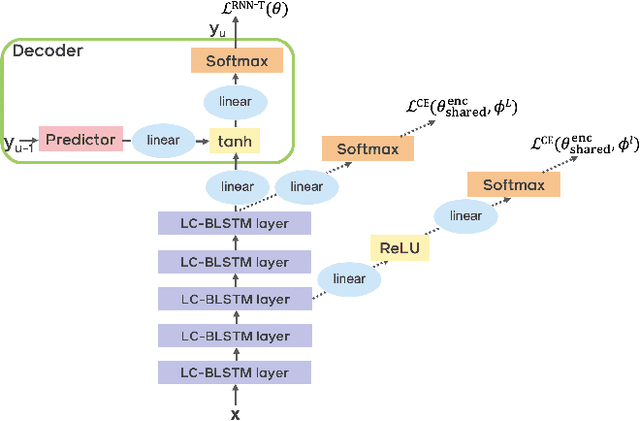
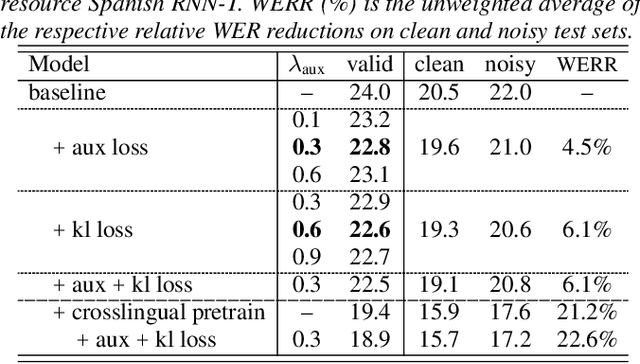
End-to-end automatic speech recognition (ASR) models with a single neural network have recently demonstrated state-of-the-art results compared to conventional hybrid speech recognizers. Specifically, recurrent neural network transducer (RNN-T) has shown competitive ASR performance on various benchmarks. In this work, we examine ways in which RNN-T can achieve better ASR accuracy via performing auxiliary tasks. We propose (i) using the same auxiliary task as primary RNN-T ASR task, and (ii) performing context-dependent graphemic state prediction as in conventional hybrid modeling. In transcribing social media videos with varying training data size, we first evaluate the streaming ASR performance on three languages: Romanian, Turkish and German. We find that both proposed methods provide consistent improvements. Next, we observe that both auxiliary tasks demonstrate efficacy in learning deep transformer encoders for RNN-T criterion, thus achieving competitive results - 2.0%/4.2% WER on LibriSpeech test-clean/other - as compared to prior top performing models.