 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabitat-GS: A High-Fidelity Navigation Simulator with Dynamic Gaussian Splatting
Apr 14, 2026Training embodied AI agents depends critically on the visual fidelity of simulation environments and the ability to model dynamic humans. Current simulators rely on mesh-based rasterization with limited visual realism, and their support for dynamic human avatars, where available, is constrained to mesh representations, hindering agent generalization to human-populated real-world scenarios. We present Habitat-GS, a navigation-centric embodied AI simulator extended from Habitat-Sim that integrates 3D Gaussian Splatting scene rendering and drivable gaussian avatars while maintaining full compatibility with the Habitat ecosystem. Our system implements a 3DGS renderer for real-time photorealistic rendering and supports scalable 3DGS asset import from diverse sources. For dynamic human modeling, we introduce a gaussian avatar module that enables each avatar to simultaneously serve as a photorealistic visual entity and an effective navigation obstacle, allowing agents to learn human-aware behaviors in realistic settings. Experiments on point-goal navigation demonstrate that agents trained on 3DGS scenes achieve stronger cross-domain generalization, with mixed-domain training being the most effective strategy. Evaluations on avatar-aware navigation further confirm that gaussian avatars enable effective human-aware navigation. Finally, performance benchmarks validate the system's scalability across varying scene complexity and avatar counts.
GeRM: A Generative Rendering Model From Physically Realistic to Photorealistic
Apr 10, 2026For decades, Physically-Based Rendering (PBR) is the fundation of synthesizing photorealisitic images, and therefore sometimes roughly referred as Photorealistic Rendering (PRR). While PBR is indeed a mathematical simulation of light transport that guarantees physical reality, photorealism has additional reliance on the realistic digital model of geometry and appearance of the real world, leaving a barely explored gap from PBR to PRR (P2P). Consequently, the path toward photorealism faces a critical dilemma: the explicit simulation of PRR encumbered by unreachable realistic digital models for real-world existence, while implicit generation models sacrifice controllability and geometric consistency. Based on this insight, this paper presents the problem, data, and approach of mitigating P2P gap, followed by the first multi-modal generative rendering model, dubbed GeRM, to unify PBR and PRR. GeRM integrates physical attributes like G-buffers with text prompts, and progressive incremental injection to generate controllable photorealistic images, allowing users to fluidly navigate the continuum between strict physical fidelity and perceptual photorealism. Technically, we model the transition between PBR and PRR images as a distribution transfer and aim to learn a distribution transfer vector field (DTV Field) to guide this process. To define the learning objective, we first leverage a multi-agent VLM framework to construct an expert-guided pairwise P2P transfer dataset, named P2P-50K, where each paired sample in the dataset corresponds to a transfer vector in the DTV Field. Subsequently, we propose a multi-condition ControlNet to learn the DTV Field, which synthesizes PBR images and progressively transitions them into PRR images, guided by G-buffers, text prompts, and cues for enhanced regions.
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Apr 08, 2026Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
PhysSkin: Real-Time and Generalizable Physics-Based Animation via Self-Supervised Neural Skinning
Mar 24, 2026Achieving real-time physics-based animation that generalizes across diverse 3D shapes and discretizations remains a fundamental challenge. We introduce PhysSkin, a physics-informed framework that addresses this challenge. In the spirit of Linear Blend Skinning, we learn continuous skinning fields as basis functions lifting motion subspace coordinates to full-space deformation, with subspace defined by handle transformations. To generate mesh-free, discretization-agnostic, and physically consistent skinning fields that generalize well across diverse 3D shapes, PhysSkin employs a new neural skinning fields autoencoder which consists of a transformer-based encoder and a cross-attention decoder. Furthermore, we also develop a novel physics-informed self-supervised learning strategy that incorporates on-the-fly skinning-field normalization and conflict-aware gradient correction, enabling effective balancing of energy minimization, spatial smoothness, and orthogonality constraints. PhysSkin shows outstanding performance on generalizable neural skinning and enables real-time physics-based animation.
DiffWind: Physics-Informed Differentiable Modeling of Wind-Driven Object Dynamics
Mar 10, 2026Modeling wind-driven object dynamics from video observations is highly challenging due to the invisibility and spatio-temporal variability of wind, as well as the complex deformations of objects. We present DiffWind, a physics-informed differentiable framework that unifies wind-object interaction modeling, video-based reconstruction, and forward simulation. Specifically, we represent wind as a grid-based physical field and objects as particle systems derived from 3D Gaussian Splatting, with their interaction modeled by the Material Point Method (MPM). To recover wind-driven object dynamics, we introduce a reconstruction framework that jointly optimizes the spatio-temporal wind force field and object motion through differentiable rendering and simulation. To ensure physical validity, we incorporate the Lattice Boltzmann Method (LBM) as a physics-informed constraint, enforcing compliance with fluid dynamics laws. Beyond reconstruction, our method naturally supports forward simulation under novel wind conditions and enables new applications such as wind retargeting. We further introduce WD-Objects, a dataset of synthetic and real-world wind-driven scenes. Extensive experiments demonstrate that our method significantly outperforms prior dynamic scene modeling approaches in both reconstruction accuracy and simulation fidelity, opening a new avenue for video-based wind-object interaction modeling.
LightCity: An Urban Dataset for Outdoor Inverse Rendering and Reconstruction under Multi-illumination Conditions
Feb 01, 2026Inverse rendering in urban scenes is pivotal for applications like autonomous driving and digital twins. Yet, it faces significant challenges due to complex illumination conditions, including multi-illumination and indirect light and shadow effects. However, the effects of these challenges on intrinsic decomposition and 3D reconstruction have not been explored due to the lack of appropriate datasets. In this paper, we present LightCity, a novel high-quality synthetic urban dataset featuring diverse illumination conditions with realistic indirect light and shadow effects. LightCity encompasses over 300 sky maps with highly controllable illumination, varying scales with street-level and aerial perspectives over 50K images, and rich properties such as depth, normal, material components, light and indirect light, etc. Besides, we leverage LightCity to benchmark three fundamental tasks in the urban environments and conduct a comprehensive analysis of these benchmarks, laying a robust foundation for advancing related research.
One-Shot Refiner: Boosting Feed-forward Novel View Synthesis via One-Step Diffusion
Jan 20, 2026We present a novel framework for high-fidelity novel view synthesis (NVS) from sparse images, addressing key limitations in recent feed-forward 3D Gaussian Splatting (3DGS) methods built on Vision Transformer (ViT) backbones. While ViT-based pipelines offer strong geometric priors, they are often constrained by low-resolution inputs due to computational costs. Moreover, existing generative enhancement methods tend to be 3D-agnostic, resulting in inconsistent structures across views, especially in unseen regions. To overcome these challenges, we design a Dual-Domain Detail Perception Module, which enables handling high-resolution images without being limited by the ViT backbone, and endows Gaussians with additional features to store high-frequency details. We develop a feature-guided diffusion network, which can preserve high-frequency details during the restoration process. We introduce a unified training strategy that enables joint optimization of the ViT-based geometric backbone and the diffusion-based refinement module. Experiments demonstrate that our method can maintain superior generation quality across multiple datasets.
Split4D: Decomposed 4D Scene Reconstruction Without Video Segmentation
Dec 28, 2025This paper addresses the problem of decomposed 4D scene reconstruction from multi-view videos. Recent methods achieve this by lifting video segmentation results to a 4D representation through differentiable rendering techniques. Therefore, they heavily rely on the quality of video segmentation maps, which are often unstable, leading to unreliable reconstruction results. To overcome this challenge, our key idea is to represent the decomposed 4D scene with the Freetime FeatureGS and design a streaming feature learning strategy to accurately recover it from per-image segmentation maps, eliminating the need for video segmentation. Freetime FeatureGS models the dynamic scene as a set of Gaussian primitives with learnable features and linear motion ability, allowing them to move to neighboring regions over time. We apply a contrastive loss to Freetime FeatureGS, forcing primitive features to be close or far apart based on whether their projections belong to the same instance in the 2D segmentation map. As our Gaussian primitives can move across time, it naturally extends the feature learning to the temporal dimension, achieving 4D segmentation. Furthermore, we sample observations for training in a temporally ordered manner, enabling the streaming propagation of features over time and effectively avoiding local minima during the optimization process. Experimental results on several datasets show that the reconstruction quality of our method outperforms recent methods by a large margin.
StreamingTalker: Audio-driven 3D Facial Animation with Autoregressive Diffusion Model
Nov 19, 2025



This paper focuses on the task of speech-driven 3D facial animation, which aims to generate realistic and synchronized facial motions driven by speech inputs. Recent methods have employed audio-conditioned diffusion models for 3D facial animation, achieving impressive results in generating expressive and natural animations. However, these methods process the whole audio sequences in a single pass, which poses two major challenges: they tend to perform poorly when handling audio sequences that exceed the training horizon and will suffer from significant latency when processing long audio inputs. To address these limitations, we propose a novel autoregressive diffusion model that processes input audio in a streaming manner. This design ensures flexibility with varying audio lengths and achieves low latency independent of audio duration. Specifically, we select a limited number of past frames as historical motion context and combine them with the audio input to create a dynamic condition. This condition guides the diffusion process to iteratively generate facial motion frames, enabling real-time synthesis with high-quality results. Additionally, we implemented a real-time interactive demo, highlighting the effectiveness and efficiency of our approach. We will release the code at https://zju3dv.github.io/StreamingTalker/.
UniVerse: Unleashing the Scene Prior of Video Diffusion Models for Robust Radiance Field Reconstruction
Oct 02, 2025
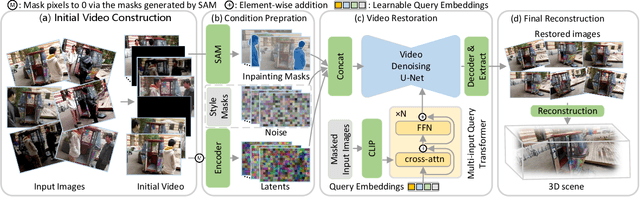
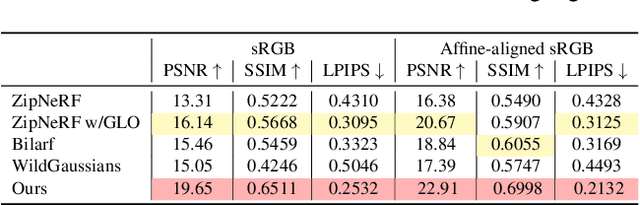

This paper tackles the challenge of robust reconstruction, i.e., the task of reconstructing a 3D scene from a set of inconsistent multi-view images. Some recent works have attempted to simultaneously remove image inconsistencies and perform reconstruction by integrating image degradation modeling into neural 3D scene representations.However, these methods rely heavily on dense observations for robustly optimizing model parameters.To address this issue, we propose to decouple robust reconstruction into two subtasks: restoration and reconstruction, which naturally simplifies the optimization process.To this end, we introduce UniVerse, a unified framework for robust reconstruction based on a video diffusion model. Specifically, UniVerse first converts inconsistent images into initial videos, then uses a specially designed video diffusion model to restore them into consistent images, and finally reconstructs the 3D scenes from these restored images.Compared with case-by-case per-view degradation modeling, the diffusion model learns a general scene prior from large-scale data, making it applicable to diverse image inconsistencies.Extensive experiments on both synthetic and real-world datasets demonstrate the strong generalization capability and superior performance of our method in robust reconstruction. Moreover, UniVerse can control the style of the reconstructed 3D scene. Project page: https://jin-cao-tma.github.io/UniVerse.github.io/